






18
Jul
科学空间终于恢复访问了!
By 苏剑林 | 2012-07-18 | 47091位读者 | 引用最近在浏览“数学研发论坛”的时候,发现了一系列不等式手册,感觉是挺宝贵的资源,就把它转载到这里来了。
当然,里边的内容难度不一,很多东西我自己也未必用得上,甚至不能弄懂,不过还是放在这里保存,并与大家分享。
原文链接:http://bbs.emath.ac.cn/thread-1549-1-1.html
文件包内容:
152个未解决的问题.pdf
HLODER 与 MINKOWSKI不等式.pdf
不等式常用证法50种.pdf
不等式基本性质.pdf
单调函数不等式.pdf
调和函数不等式.pdf
多边形与多面体不等式.pdf
反三角函数不等式.pdf
级数不等式.pdf
数论不等式.pdf
农村的一个习俗就是孩子上大学了,一般要摆个大学酒,请亲朋好友们一起庆祝一番,说是光宗耀祖等等。那仪式好比婚礼仪式那样隆重......
这几天都是同学们摆大学酒的日子,10号去了东城镇喝老朱的大学酒,还要麻烦老朱他们免费接送,真的有点过意不去呀;11号是我自己的大学酒,叫了一群同学来,最后到场的有二十五个^_^,大家一起在村子礼堂二楼“包场”;12号是大宇和芬姐的,两边都答应了,所以中午去大宇那儿吃了一顿,下午去芬姐那玩了一番......
其实,于我们而言,大学酒就是一场同学们的聚会,藉着这个契机,我们昔日的同窗好友聚在一起,回忆过去,畅谈未来,讲述着我们那说不尽的友谊。我是很庆幸的一个人,三天四个人的大学酒都有我的参与,这至少给了我一些鼓励,这说明我的人际关系还不坏。谢谢邀请我的朋友们。也许很快我们就要真正地各分东西了,但是我相信,很多东西依然会存在我们的心中,那就像一条纽带,将我们紧紧联系在一起,如同天涯咫尺一般。
我相信,有很多地久天长的东西。
大学酒:



4
Dec
[转载]复杂的机械,简单的原理
By 苏剑林 | 2012-12-04 | 47779位读者 | 引用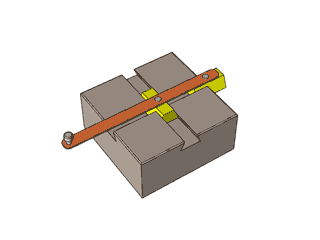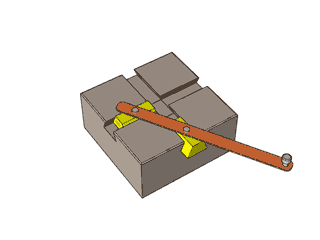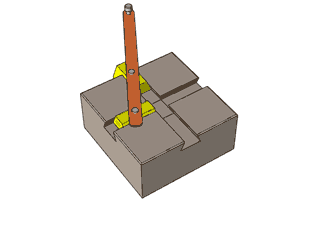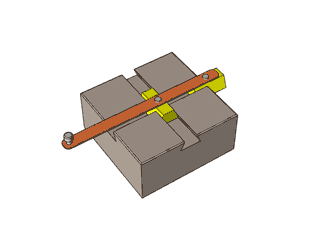
5
Feb
[公告]评论功能说明
By 苏剑林 | 2013-02-05 | 18270位读者 | 引用
4
Feb
[问题解答]双曲线上的最短距离
By 苏剑林 | 2013-02-04 | 28836位读者 | 引用
6
Feb

最近评论