






10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 108295位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 82498位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow
28
Apr
“让Keras更酷一些!”:中间变量、权重滑动和安全生成器
By 苏剑林 | 2019-04-28 | 110520位读者 | 引用继续“让Keras更酷一些”之旅。
今天我们会用Keras实现灵活地输出任意中间变量,还有无缝地进行权重滑动平均,最后顺便介绍一下生成器的进程安全写法。
首先是输出中间变量。在自定义层时,我们可能希望查看中间变量,这些需求有些是比较容易实现的,比如查看中间某个层的输出,只需要将截止到这个层的部分模型保存为一个新模型即可,但有些需求是比较困难的,比如在使用Attention层时我们可能希望查看那个Attention矩阵的值,如果用构建新模型的方法则会非常麻烦。而本文则给出一种简单的方法,彻底满足这个需求。
接着是权重滑动平均。权重滑动平均是稳定、加速模型训练甚至提升模型效果的一种有效方法,很多大型模型(尤其是GAN)几乎都用到了权重滑动平均。一般来说权重滑动平均是作为优化器的一部分,所以一般需要重写优化器才能实现它。本文介绍一个权重滑动平均的实现,它可以无缝插入到任意Keras模型中,不需要自定义优化器。
至于生成器的进程安全写法,则是因为Keras读取生成器的时候,用到了多进程,如果生成器本身也包含了一些多进程操作,那么可能就会导致异常,所以需要解决这个这个问题。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 285819位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
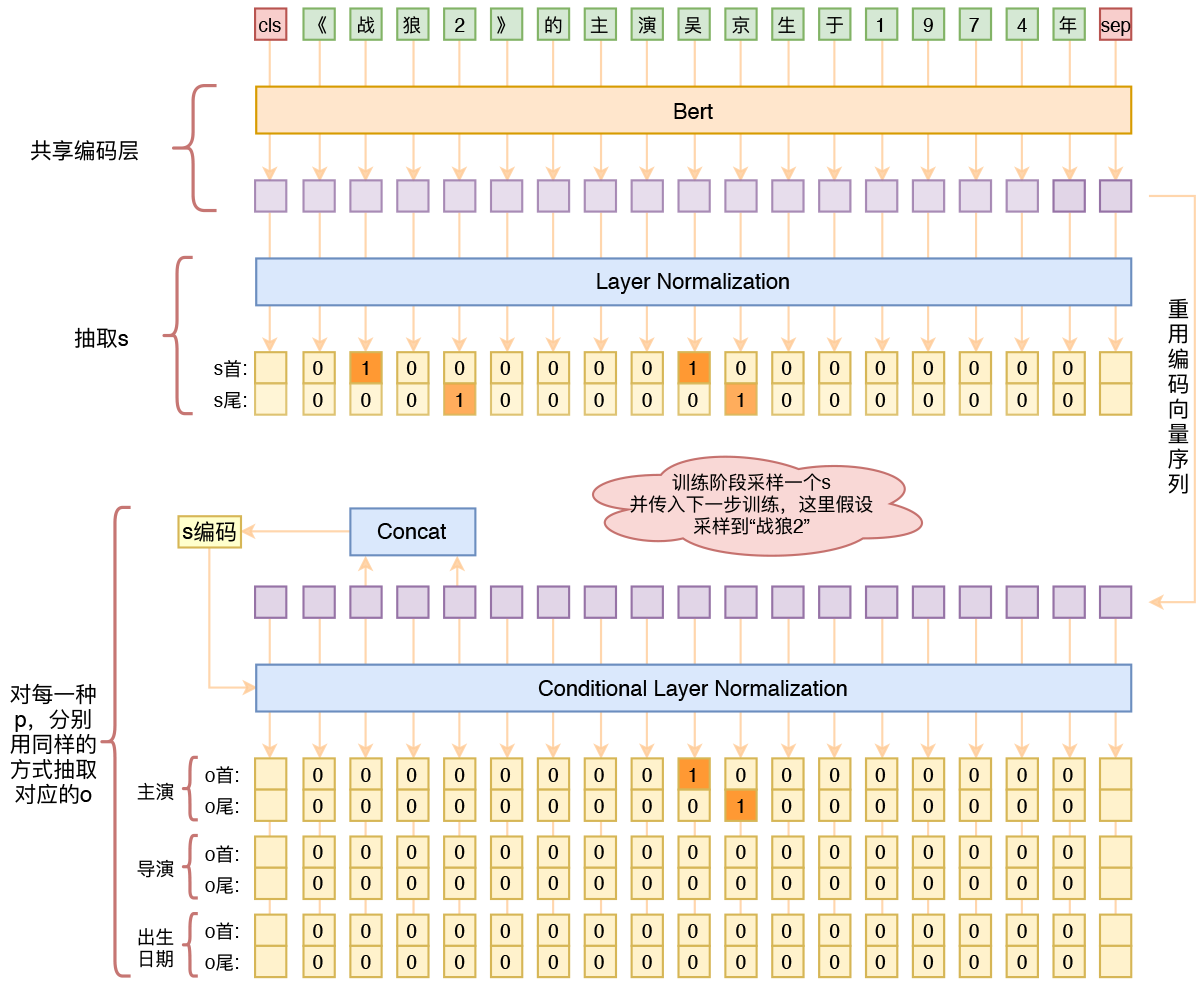
基于Bert的三元组抽取模型结构示意图
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 465939位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
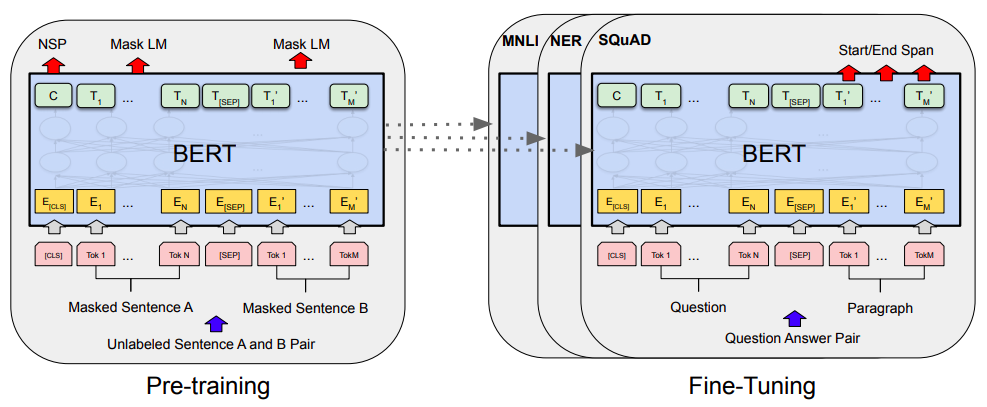
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
29
Sep
“让Keras更酷一些!”:层与模型的重用技巧
By 苏剑林 | 2019-09-29 | 122846位读者 | 引用今天我们继续来深挖Keras,再次体验Keras那无与伦比的优雅设计。这一次我们的焦点是“重用”,主要是层与模型的重复使用。
所谓重用,一般就是奔着两个目标去:一是为了共享权重,也就是说要两个层不仅作用一样,还要共享权重,同步更新;二是避免重写代码,比如我们已经搭建好了一个模型,然后我们想拆解这个模型,构建一些子模型等。
基础
事实上,Keras已经为我们考虑好了很多,所以很多情况下,掌握好基本用法,就已经能满足我们很多需求了。
层的重用
层的重用是最简单的,将层初始化好,存起来,然后反复调用即可:
x_in = Input(shape=(784,))
x = x_in
layer = Dense(784, activation='relu') # 初始化一个层,并存起来
x = layer(x) # 第一次调用
x = layer(x) # 再次调用
x = layer(x) # 再次调用
27
Aug
自己实现了一个bert4keras
By 苏剑林 | 2019-08-27 | 193425位读者 | 引用
8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 86777位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花n倍的时间,可以达到n倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。

最近评论