






18
Dec
迟到一年的建模:再探碎纸复原
By 苏剑林 | 2014-12-18 | 81837位读者 | 引用前言:一年前国赛的时候,很初级地做了一下B题,做完之后还写了个《碎纸复原:一个人的数学建模》。当时就是对题目很有兴趣,然后通过一天的学习,基本完成了附件一二的代码,对附件三也只是有个概念。而今年我们上的数学建模课,老师把这道题作为大作业让我们做,于是我便再拾起了一年前的那份激情,继续那未完成的一个人的数学建模...
与去年不同的是,这次将所有代码用Python实现了,更简洁,更清晰,甚至可能更高效~~以下是论文全文。
研究背景
2011年10月29日,美国国防部高级研究计划局(DARPA)宣布了一场碎纸复原挑战赛(Shredder Challenge),旨在寻找到高效有效的算法,对碎纸机处理后的碎纸屑进行复原。[1]该竞赛吸引了全美9000支参赛队伍参与角逐,经过一个多月的时间,有一支队伍成功完成了官方的题目。
近年来,碎纸复原技术日益受到重视,它显示了在碎片中“还原真相”的可能性,表明我们可以从一些破碎的片段中“解密”出原始信息来。另一方面,该技术也和照片处理领域中的“全景图拼接技术”有一定联系,该技术是指通过若干张不同侧面的照片,合成一张完整的全景图。因此,分析研究碎纸复原技术,有着重要的意义。
10
Jun
【翻译】巨型望远镜:要继续,就得有牺牲!
By 苏剑林 | 2015-06-10 | 27490位读者 | 引用
2007年末公布的30米望远镜效果图
文章来自:新科学家,这是一篇关于30米望远镜(Thirty Meter Telescope,TMT)的新闻,起因是望远镜的制造遭到当地人的不满,当然背后的原因是很深远的,难以说清楚。更多有关TMT的新闻,可以阅读:http://www.ctmt.org/
夏威夷的巨型望远镜:要继续,就得有牺牲!
四分之一必须离开!在停止了两个月之后,夏威夷的巨型30米望远镜(Thirty Meter Telescope,TMT)重新回归到建设进程——但要牺牲其他望远镜。
由于夏威夷当地居民的抗议声越来越大,早在四月望远镜的建设工作就被迫暂停。与该望远镜相比,目前世界上所有的望远镜都相形见绌——它让能够让天文学家们凝视可见的宇宙的边缘。它位于许多夏威夷人认为是“神圣之地”的死火山莫纳克亚山,因此被夏威夷人认为是一种侮辱——尤其是在山顶已经有十多个望远镜了。
13
Nov
ARXIV数学论文分布:偏微分方程最热门!
By 苏剑林 | 2015-11-13 | 31510位读者 | 引用笔者成功地保研到了中山大学的基础数学专业,这个专业自然是比较理论性的,虽然如此,我还会保持着我对数据分析、计算机等方面的兴趣。这几天兴致来了,想做一下结合我的专业跟数据挖掘相结合的研究,所以就爬取了ARXIV上面近五年(2010年到2014年)的数学论文(包含的数据有:标题、分类、年份、月份),想对这几年来数学的“行情”做一下简单的分析。个人认为,ARVIX作为目前全球最大的论文预印本的电子数据库,对它的数据进行分析,所得到的结论是能够具有一定的代表性的。
当然,本文只是用来练手爬虫和基本数据分析的文章,并没有挖掘出特别有价值的信息。文末附录了笔者爬取到的数据,供有兴趣的读者进一步分析研究。
整体情况
这五年来,ARXIV的数学论文总数为135009篇,平均每年27000篇,或者每天74篇。
27
Aug
fashion mnist的一个baseline (MobileNet 95%)
By 苏剑林 | 2017-08-27 | 80340位读者 | 引用浅尝
昨天简单试了一下在fashion mnist的gan模型,发现还能work,当然那个尝试也没什么技术水平,就是把原来的脚本改一下路径跑了就完事。今天回到fashion mnist本身的主要任务——10分类,用Keras测了一下一些模型在上面的分类效果,最后得到了94.5%左右的准确率,加上随机翻转的数据扩增能做到95%。
首先随便手写了一些模型的组合,测试发现准确率都不大好,看来对于这个数据集来说,自己构思模型是比较困难的了,于是想着用现成的模型结构。一说到现成的cnn模型,基本上我们都会想到VGG、ResNet、inception、Xception等,但这些模型为解决imagenet的1000分类问题而设计,用到这个入门级别的数据集上似乎过于庞大了,而且也容易过拟合。后来突然想起,Keras好像自带了个叫MobileNet的模型,查看了一下模型权重,发现参数量不大,但是容量应该还是可以的,故选用MobileNet做实验。
深究
16
Oct
如何划分一个跟测试集更接近的验证集?
By 苏剑林 | 2020-10-16 | 57423位读者 | 引用不管是打比赛、做实验还是搞工程,我们经常会遇到训练集与测试集分布不一致的情况。一般来说我们会从训练集中划分出来一个验证集,通过这个验证集来调整一些超参数(参考《训练集、验证集和测试集的意义》),比如控制模型的训练轮数以防止过拟合。然而,如果验证集本身跟测试集差别比较大,那么验证集上很好的模型也不代表在测试集上很好,因此如何让划分出来验证集跟测试集的分布差异更小一些,是一个值得研究的题目。
两种情况
首先,明确一下,本文所考虑的,是能给拿到测试集数据本身、但不知道测试集标签的场景。如果是那种提交模型封闭评测的场景,我们完全看不到测试集的,那就没什么办法了。为什么会出现测试集跟训练集分布不一致的现象呢?主要有两种情况。
24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 124416位读者 | 引用前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
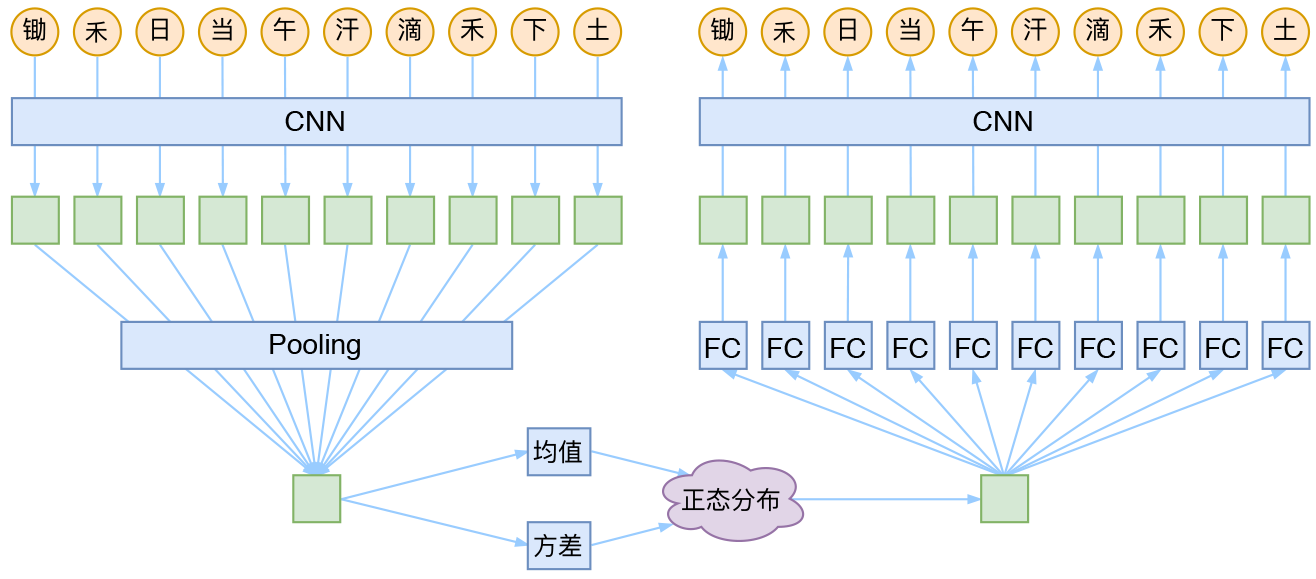
cnn + vae 诗歌生成模型
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 960538位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
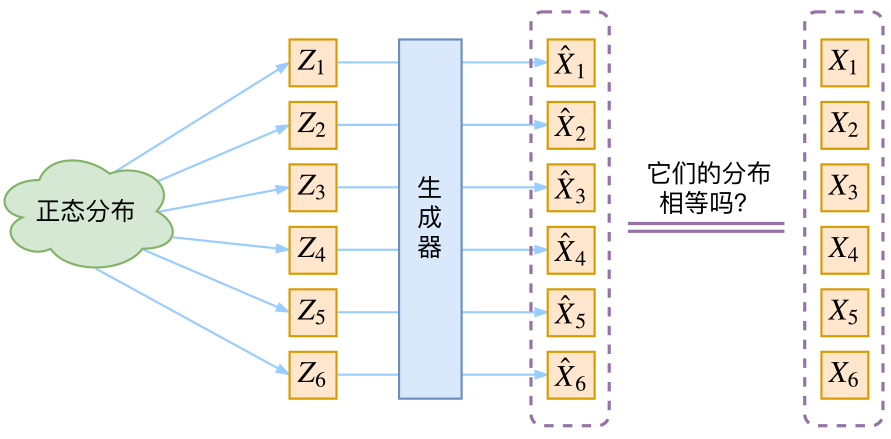
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
28
Mar
变分自编码器(二):从贝叶斯观点出发
By 苏剑林 | 2018-03-28 | 463213位读者 | 引用源起
前几天写了博文《变分自编码器(一):原来是这么一回事》,从一种比较通俗的观点来理解变分自编码器(VAE),在那篇文章的视角中,VAE跟普通的自编码器差别不大,无非是多加了噪声并对噪声做了约束。然而,当初我想要弄懂VAE的初衷,是想看看究竟贝叶斯学派的概率图模型究竟是如何与深度学习结合来发挥作用的,如果仅仅是得到一个通俗的理解,那显然是不够的。
所以我对VAE继续思考了几天,试图用更一般的、概率化的语言来把VAE说清楚。事实上,这种思考也能回答通俗理解中无法解答的问题,比如重构损失用MSE好还是交叉熵好、重构损失和KL损失应该怎么平衡,等等。
建议在阅读《变分自编码器(一):原来是这么一回事》后对本文进行阅读,本文在内容上尽量不与前文重复。
准备
在进入对VAE的描述之前,我觉得有必要把一些概念性的内容讲一下。

最近评论