






1
Sep
Decoder-only的LLM为什么需要位置编码?
By 苏剑林 | 2024-09-01 | 33421位读者 | 引用众所周知,目前主流的LLM,都是基于Causal Attention的Decoder-only模型(对此我们在《为什么现在的LLM都是Decoder-only的架构?》也有过相关讨论),而对于Causal Attention,已经有不少工作表明它不需要额外的位置编码(简称NoPE)就可以取得非平凡的结果。然而,事实是主流的Decoder-only LLM都还是加上了额外的位置编码,比如RoPE、ALIBI等。
那么问题就来了:明明说了不加位置编码也可以,为什么主流的LLM反而都加上了呢?不是说“多一事不如少一事”吗?这篇文章我们从三个角度给出笔者的看法:
1、位置编码对于Attention的作用是什么?
2、NoPE的Causal Attention是怎么实现位置编码的?
3、NoPE实现的位置编码有什么不足?
16
Oct
Cool Papers浏览器扩展升级至v0.2.0
By 苏剑林 | 2024-10-16 | 19930位读者 | 引用年初,我们在《更便捷的Cool Papers打开方式:Chrome重定向扩展》中发布了一个Chrome浏览器插件(Cool Papers Redirector v0.1.0),可以通过右击菜单从任意页面中重定向到Cool Papers中,让大家更方便地获取Kimi对论文的理解。前几天我们把该插件升级到了v0.2.0,并顺利上架到了Chrome应用商店中,遂在此向大家推送一下。
更新汇总
相比旧版v0.1.0,当前版v0.2.0的主要更新内容如下:
1、右键菜单跳转改为在新标签页打开;
2、右键菜单支持同时访问多个论文ID;
3、右键菜单支持PDF页面;
4、右键菜单新增更多论文源(arXiv、OpenReview、ACL、IJCAI、PMLR);
5、右键菜单在搜索不到论文ID时,转入站内搜索(即划词搜索);
6、在某些网站的适当位置插入快捷跳转链接(arXiv、OpenReview,ACL)。
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 62095位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 57560位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 218181位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
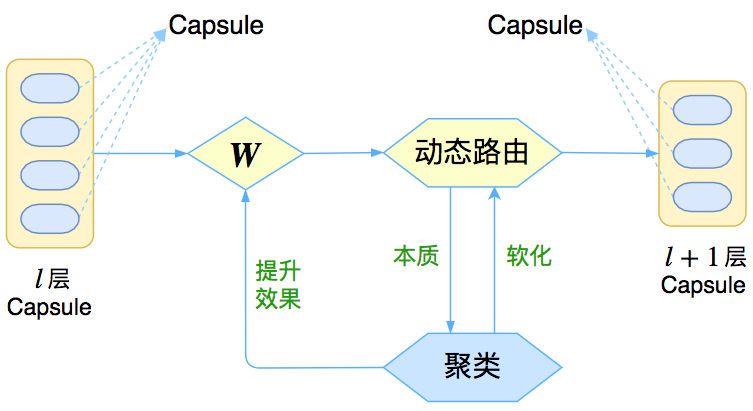
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 315323位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
16
Jul

最近评论