






6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 744044位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
8
Jun
Naive Bayes is all you need ?
By 苏剑林 | 2023-06-08 | 26615位读者 | 引用很抱歉,起了这么个具有标题党特征的题目。在写完《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》之后,笔者就觉得朴素贝叶斯(Naive Bayes)跟Attention机制有很多相同的特征,后来再推导了一下发现,Attention机制其实可以看成是一种广义的、参数化的朴素贝叶斯。既然如此,“Attention is All You Need”不也就意味着“Naive Bayes is all you need”了?这就是本文标题的缘由。
接下来笔者将介绍自己的思考过程,分析如何从朴素贝叶斯角度来理解Attention机制。
朴素贝叶斯
本文主要考虑语言模型,它要建模的是$p(x_t|x_1,\cdots,x_{t-1})$。根据贝叶斯公式,我们有
\begin{equation}p(x_t|x_1,\cdots,x_{t-1}) = \frac{p(x_1,\cdots,x_{t-1}|x_t)p(x_t)}{p(x_1,\cdots,x_{t-1})}\propto p(x_1,\cdots,x_{t-1}|x_t)p(x_t)\end{equation}
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 106279位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 161560位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。
24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 67444位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
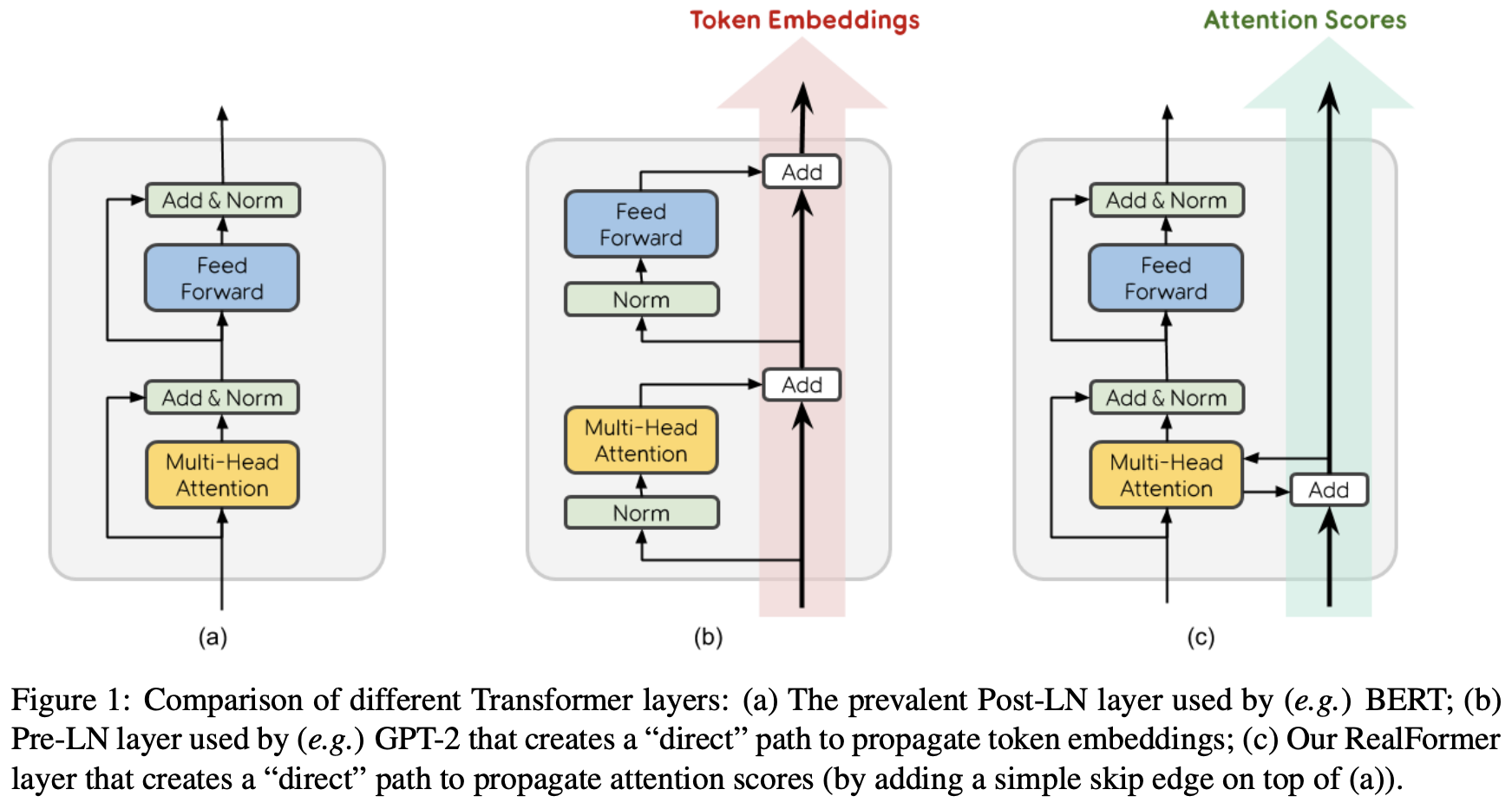
PostLN、PreLN和RealFormer结构示意图
22
Apr
Transformer升级之路:3、从Performer到线性Attention
By 苏剑林 | 2021-04-22 | 40823位读者 | 引用看过笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Performer:用随机投影将Attention的复杂度线性化》的读者,可能会觉得本文的标题有点不自然,因为是先有线性Attention然后才有Performer的,它们的关系为“Performer是线性Attention的一种实现,在保证线性复杂度的同时保持了对标准Attention的近似”,所以正常来说是“从线性Attention到Performer”才对。
然而,本文并不是打算梳理线性Attention的发展史,而是打算反过来思考Performer给线性Attention所带来的启示,所以是“从Performer到线性Attention”。
激活函数
线性Attention的常见形式是
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 35867位读者 | 引用标准Attention的$\mathscr{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
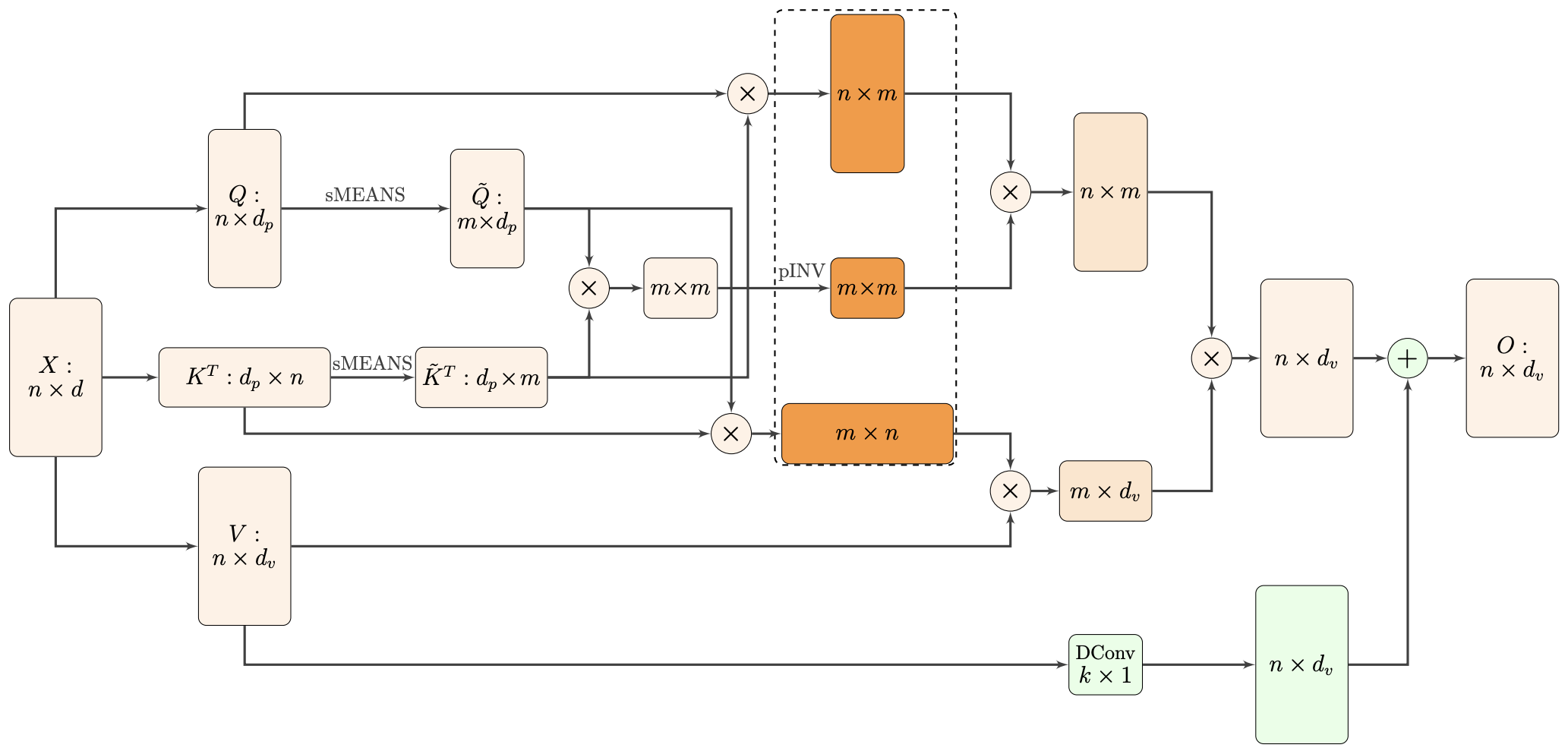
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 79693位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。

最近评论