






3
Aug
美华裔教授破百年物理定律 获国际同行喝彩(图)
By 苏剑林 | 2009-08-03 | 16415位读者 | 引用
29
Aug
行动起来!共同应对全球气候变暖
By 苏剑林 | 2009-08-29 | 15883位读者 | 引用8月28日是距离哥本哈根气候大会召开倒数100天的日子。
在这个特殊的日子,绿色和平将以特别的行动,邀请了广大的中国公众一起关注全球变暖,参与拯救气候的伟大使命。
11点至16点这五个小时内,“我在乎”和观众们一起来观看见证了这些“冰孩子”们的命运:
中国 — 8月28日,无数双眼睛见证了这样的一幕:绿色和平取自长江、黄河和恒河三条大江源头的冰川融水在北京制作而成冰雕孩子,同印度新德里雕刻成数字“100”的冰雕遥相呼应。冰小孩的在北京和印度新德里的迅速“消失”,告诉我们喜马拉雅—青藏高原地区冰川的加速消融,影响最大的当然是亚洲国家人民的生活。
13
Oct
两名美国经济学家同获2009年诺贝尔经济学奖
By 苏剑林 | 2009-10-13 | 16489位读者 | 引用
18
Apr
【奥赛之行】非同一般的天文奥赛
By 苏剑林 | 2010-04-18 | 22431位读者 | 引用
14
Aug
今天我们都是舟曲人——举国哀悼舟曲遇难同胞
By 苏剑林 | 2010-08-14 | 22145位读者 | 引用
4
Oct
哈勃定律——宇宙各向同性的体现
By 苏剑林 | 2010-10-04 | 21741位读者 | 引用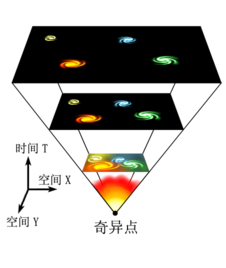
universe_mystery_expand
1929年哈勃(Edwin Hubble)对河外星系的视向速度与距离的关系进行了研究。当时只有46个河外星系的视向速度可以利用,而其中仅有24个有推算出的距离,哈勃得出了视向速度与距离之间大致的线性正比关系。
不少宇宙学的书籍中都提到了标题,那么,为什么哈勃定律是宇宙各向同性的体现?或者说为什么宇宙各向同性就必然导致哈勃定律?
首先我们得需要了解一下宇宙学原理,它告诉我们宇宙在大尺度范围是均匀的、各向同性的。基于这个原理,我们会得到一些很奇怪的东西,如宇宙中的每一点都是宇宙的中心。另外,我们还可以得到:宇宙的(整体)运动情况在每一个方向都应该取相同的形式。
23
Mar
梯度下降和EM算法:系出同源,一脉相承
By 苏剑林 | 2017-03-23 | 202291位读者 | 引用PS:本文就是梳理了梯度下降与EM算法的关系,通过同一种思路,推导了普通的梯度下降法、pLSA中的EM算法、K-Means中的EM算法,以此表明它们基本都是同一个东西的不同方面,所谓“横看成岭侧成峰,远近高低各不同”罢了。
在机器学习中,通常都会将我们所要求解的问题表示为一个带有未知参数的损失函数(Loss),如平均平方误差(MSE),然后想办法求解这个函数的最小值,来得到最佳的参数值,从而完成建模。因将函数乘以-1后,最大值也就变成了最小值,因此一律归为最小值来说。如何求函数的最小值,在机器学习领域里,一般会流传两个大的方向:1、梯度下降;2、EM算法,也就是最大期望算法,一般用于复杂的最大似然问题的求解。
在通常的教程中,会将这两个方法描述得迥然不同,就像两大体系在分庭抗礼那样,而EM算法更是被描述得玄乎其玄的感觉。但事实上,这两个方法,都是同一个思路的不同例子而已,所谓“本是同根生”,它们就是一脉相承的东西。
让我们,先从远古的牛顿法谈起。
牛顿迭代法
给定一个复杂的非线性函数$f(x)$,希望求它的最小值,我们一般可以这样做,假定它足够光滑,那么它的最小值也就是它的极小值点,满足$f'(x_0)=0$,然后可以转化为求方程$f'(x)=0$的根了。非线性方程的根我们有个牛顿法,所以
\begin{equation}x_{n+1} = x_{n} - \frac{f'(x_n)}{f''(x_n)}\end{equation}
15
Sep
殊途同归的策略梯度与零阶优化
By 苏剑林 | 2020-09-15 | 53356位读者 | 引用深度学习如此成功的一个巨大原因就是基于梯度的优化算法(SGD、Adam等)能有效地求解大多数神经网络模型。然而,既然是基于梯度,那么就要求模型是可导的,但随着研究的深入,我们时常会有求解不可导模型的需求,典型的例子就是直接优化准确率、F1、BLEU等评测指标,或者在神经网络里边加入了不可导模块(比如“跳读”操作)。

Gradient
本文将简单介绍两种求解不可导的模型的有效方法:强化学习的重要方法之一策略梯度(Policy Gradient),以及干脆不需要梯度的零阶优化(Zeroth Order Optimization)。表面上来看,这是两种思路完全不一样的优化方法,但本文将进一步证明,在一大类优化问题中,其实两者基本上是等价的。

最近评论