






13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 486147位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
15
Jul
不成功的尝试:将多标签交叉熵推广到“n个m分类”上去
By 苏剑林 | 2022-07-15 | 27122位读者 | 引用可能有读者留意到,这次更新相对来说隔得比较久了。事实上,在上周末时就开始准备这篇文章了,然而笔者低估了这个问题的难度,几乎推导了整整一周,仍然还没得到一个完善的结果出来。目前发出来的,仍然只是一个失败的结果,希望有经验的读者可以指点指点。
在文章《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个多标签分类损失函数,它能自动调节正负类的不平衡问题,后来在《多标签“Softmax+交叉熵”的软标签版本》中我们还进一步得到了它的“软标签”版本。本质上来说,多标签分类就是“n个2分类”问题,那么相应的,“n个m分类”的损失函数又该是怎样的呢?
这就是本文所要探讨的问题。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 170969位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
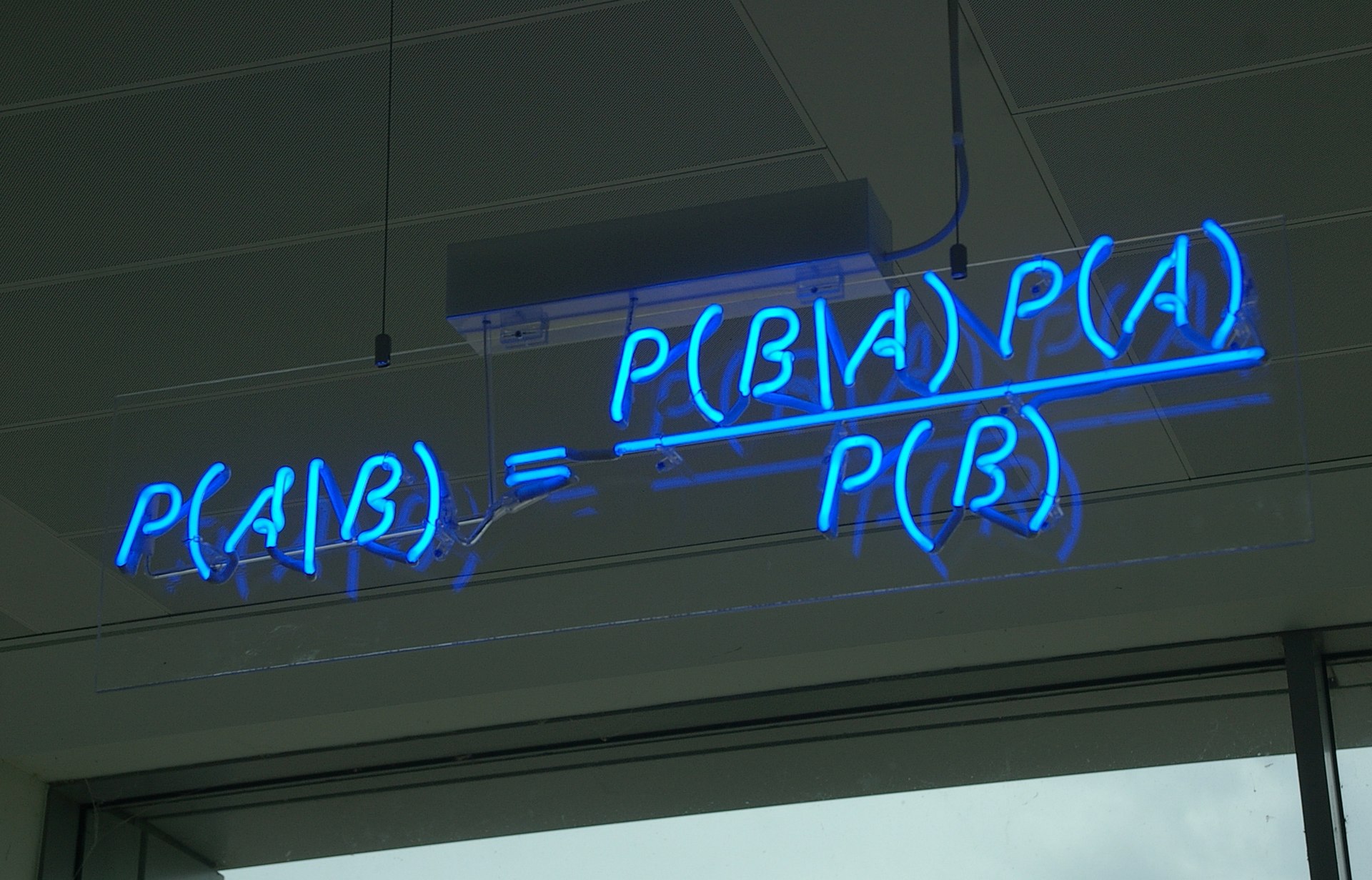
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 78553位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 44127位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 147663位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 234757位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的T步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了T步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 36060位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。

最近评论