






31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 90006位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 83854位读者 | 引用这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt
4
Dec
开局一段扯,数据全靠编?真被一篇“神论文”气到了
By 苏剑林 | 2021-12-04 | 61622位读者 | 引用这篇文章谈一下笔者被昨天出来的一篇“神论文”气到了的经历。
这篇“神论文”是《How not to Lie with a Benchmark: Rearranging NLP Leaderboards》,论文的大致内容是说目前很多排行榜算平均都用算术平均,而它认为几何平均与调和平均更加合理。最关键是它还对GLUE、SuperGLUE等榜单上的模型用几何平均和调和平均重新算了一下排名,结果发现那些超过人类的模型在新的平均方案下都没超过人类了。
看上去是不是觉得挺有意思的?我也觉得挺有意思的,所以打算写一篇博客介绍一下它。结果博客快写完了,然后在对数据的时候,发现里边表格的数据全是乱来的!!!真实的结果完全不支撑它的结论!!!所以,这篇博客就从“表扬大会”变成了“批评大会”...
18
May
当BERT-whitening引入超参数:总有一款适合你
By 苏剑林 | 2022-05-18 | 48076位读者 | 引用在《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者提出了BERT-whitening,验证了一个线性变换就能媲美当时的SOTA方法BERT-flow。此外,BERT-whitening还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
为了弥补这个不足,本文提出往BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上whitening后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。
方法概要
目前BERT-whitening的流程是:
\begin{equation}\begin{aligned}
\tilde{\boldsymbol{x}}_i =&\, (\boldsymbol{x}_i - \boldsymbol{\mu})\boldsymbol{U}\boldsymbol{\Lambda}^{-1/2} \\
\boldsymbol{\mu} =&\, \frac{1}{N}\sum\limits_{i=1}^N \boldsymbol{x}_i \\
\boldsymbol{\Sigma} =&\, \frac{1}{N}\sum\limits_{i=1}^N (\boldsymbol{x}_i - \boldsymbol{\mu})^{\top}(\boldsymbol{x}_i - \boldsymbol{\mu}) = \boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{\top} \,\,(\text{SVD分解})
\end{aligned}\end{equation}
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 23994位读者 | 引用
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 61409位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
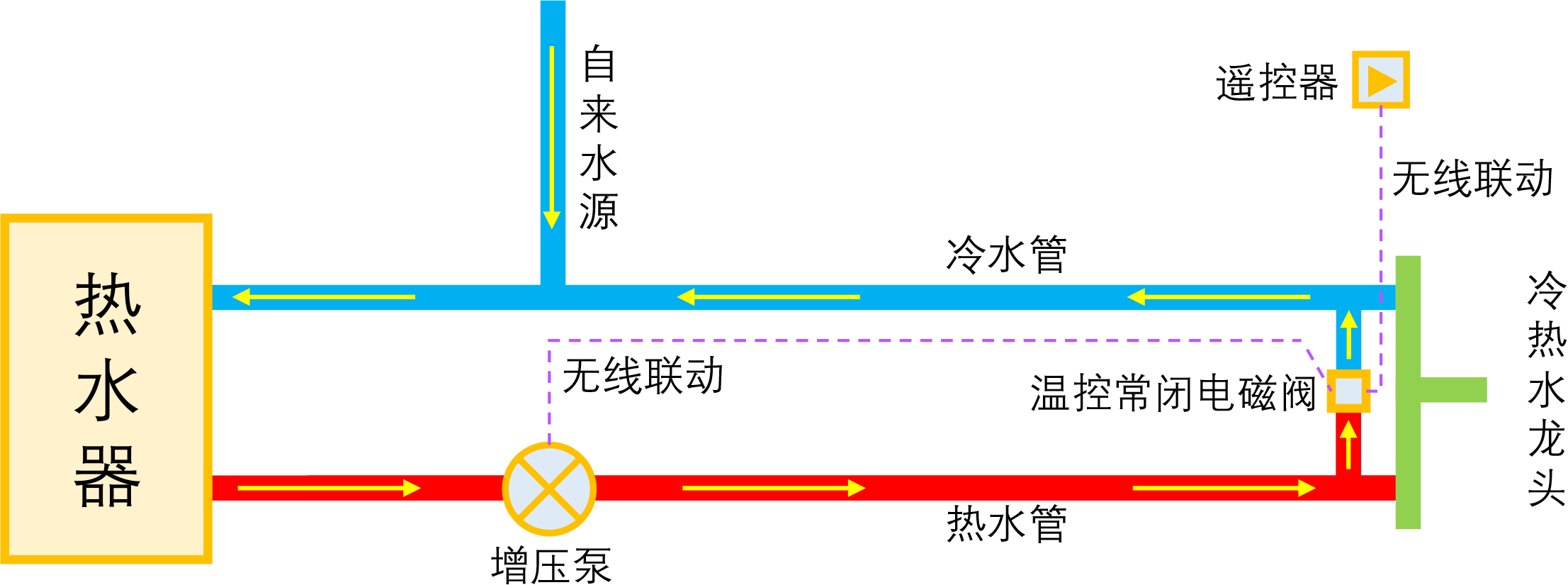
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。
10
Apr
从JL引理看熵不变性Attention
By 苏剑林 | 2023-04-10 | 38986位读者 | 引用在《从熵不变性看Attention的Scale操作》、《熵不变性Softmax的一个快速推导》中笔者提出了熵不变性Softmax,简单来说就是往Softmax之前的Attention矩阵多乘上一个\log n,理论上有助于增强长度外推性,其中n是序列长度。\log n这个因子让笔者联系到了JL引理(Johnson-Lindenstrauss引理),因为JL引理告诉我们编码n个向量只需要\mathcal{O}(\log n)的维度就行了,大家都是\log n,这两者有没有什么关联呢?
熵不变性
我们知道,熵是不确定性的度量,用在注意力机制中,我们将它作为“集中注意力的程度”。所谓熵不变性,指的是不管序列长度n是多少,我们都要将注意力集中在关键的几个token上,而不要太过分散。为此,我们提出的熵不变性Attention形式为
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\log_{512} n}{\sqrt{d}}QK^{\top}\right)V\label{eq:core}\end{equation}
14
Aug
Transformer升级之路:13、逆用Leaky ReRoPE
By 苏剑林 | 2023-08-14 | 25969位读者 | 引用上周在《Transformer升级之路:12、无限外推的ReRoPE?》中,笔者提出了ReRoPE和Leaky ReRoPE,诸多实验结果表明,它们能够在几乎不损失训练效果的情况下免微调地扩展LLM的Context长度,并且实现了“longer context, lower loss”的理想特性,此外跟NTK-aware Scaled RoPE不同的是,其中ReRoPE似乎还有表现出了无限的Context处理能力。
总之,ReRoPE看起来相当让人满意,但美中不足的是会增加推理成本,具体表现为第一步推理需要算两次Attention,以及后续每步推理需要重新计算位置编码。本文试图通过在训练中逆用Leaky ReRoPE的方法来解决这个问题。
回顾
让我们不厌其烦地重温一下:RoPE形式上是一种绝对位置编码,但实际达到的效果是相对位置编码,对应的相对位置矩阵是:
\begin{equation}\begin{pmatrix}0 & \\
1 & 0 & \\
2 & 1 & 0 &\\
3 & 2 & 1 & 0 & \\
\ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\small{L - 2} & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\small{L - 1} & \small{L - 2} & \ddots & \ddots & \ddots & 3 & 2 & 1 & 0 & \\
\end{pmatrix}\label{eq:rope}\end{equation}

最近评论