






8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 34419位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
14
Oct
训练集、验证集和测试集的意义
By 苏剑林 | 2017-10-14 | 51507位读者 | 引用
23
Jun
貌离神合的RNN与ODE:花式RNN简介
By 苏剑林 | 2018-06-23 | 105610位读者 | 引用本来笔者已经决心不玩RNN了,但是在上个星期思考时忽然意识到RNN实际上对应了ODE(常微分方程)的数值解法,这为我一直以来想做的事情——用深度学习来解决一些纯数学问题——提供了思路。事实上这是一个颇为有趣和有用的结果,遂介绍一翻。顺便地,本文也涉及到了自己动手编写RNN的内容,所以本文也可以作为编写自定义的RNN层的一个简单教程。
注:本文并非前段时间的热点“神经ODE”的介绍(但有一定的联系)。
RNN基本
什么是RNN?
众所周知,RNN是“循环神经网络(Recurrent Neural Network)”,跟CNN不同,RNN可以说是一类模型的总称,而并非单个模型。简单来讲,只要是输入向量序列$(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_T)$,输出另外一个向量序列$(\boldsymbol{y}_1,\boldsymbol{y}_2,\dots,\boldsymbol{y}_T)$,并且满足如下递归关系
$$\boldsymbol{y}_t=f(\boldsymbol{y}_{t-1}, \boldsymbol{x}_t, t)\tag{1}$$
的模型,都可以称为RNN。也正因为如此,原始的朴素RNN,还有改进的如GRU、LSTM、SRU等模型,我们都称为RNN,因为它们都可以作为上式的一个特例。还有一些看上去与RNN没关的内容,比如前不久介绍的CRF的分母的计算,实际上也是一个简单的RNN。
说白了,RNN其实就是递归计算。
6
Aug
“让Keras更酷一些!”:精巧的层与花式的回调
By 苏剑林 | 2018-08-06 | 171343位读者 | 引用Keras伴我走来
回想起进入机器学习领域的这两三年来,Keras是一直陪伴在笔者的身边。要不是当初刚掉进这个坑时碰到了Keras这个这么易用的框架,能快速实现我的想法,我也不确定我是否能有毅力坚持下来,毕竟当初是theano、pylearn、caffe、torch等的天下,哪怕在今天它们对我来说仍然像天书一般。
后来为了拓展视野,我也去学习了一段时间的tensorflow,用纯tensorflow写过若干程序,但不管怎样,仍然无法割舍Keras。随着对Keras的了解的深入,尤其是花了一点时间研究过Keras的源码后,我发现Keras并没有大家诟病的那样“欠缺灵活性”。事实上,Keras那精巧的封装,可以让我们轻松实现很多复杂的功能。我越来越感觉,Keras像是一件非常精美的艺术品,充分体现了Keras的开发者们深厚的创作功力。
本文介绍Keras中自定义模型的一些内容,相对而言,这属于Keras进阶的内容,刚入门的朋友请暂时忽略。
层的自定义
这里介绍Keras中自定义层及其一些运用技巧,在这之中我们可以看到Keras层的精巧之处。
20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 127511位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到$\text{argmax}$等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是$\max$操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
29
Apr
节省显存的重计算技巧也有了Keras版了
By 苏剑林 | 2020-04-29 | 50744位读者 | 引用不少读者最近可能留意到了公众号文章《BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码)》,里边介绍了一个叫做“重计算”的技巧,简单来说就是用来省显存的方法,让平均训练速度慢一点,但batch_size可以增大好几倍。该技巧首先发布于论文《Training Deep Nets with Sublinear Memory Cost》,其实在2016年就已经提出了,只不过似乎还没有特别流行起来。
探索
公众号文章提到该技巧在pytorch和paddlepaddle都有原生实现了,但tensorflow还没有。但事实上从tensorflow 1.8开始,tensorflow就已经自带了该功能了,当时被列入了tf.contrib这个子库中,而从tensorflow 1.15开始,它就被内置为tensorflow的主函数之一,那就是tf.recompute_grad。
找到tf.recompute_grad之后,笔者就琢磨了一下它的用法,经过一番折腾,最终居然真的成功地用起来了,居然成功地让batch_size从48增加到了144!然而,在继续整理测试的过程中,发现这玩意居然在tensorflow 2.x是失效的...于是再折腾了两天,查找了各种资料并反复调试,最终算是成功地补充了这一缺陷。
最后是笔者自己的开源实现:
该实现已经内置在bert4keras中,使用bert4keras的读者可以升级到最新版本(0.7.5+)来测试该功能。
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 71603位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
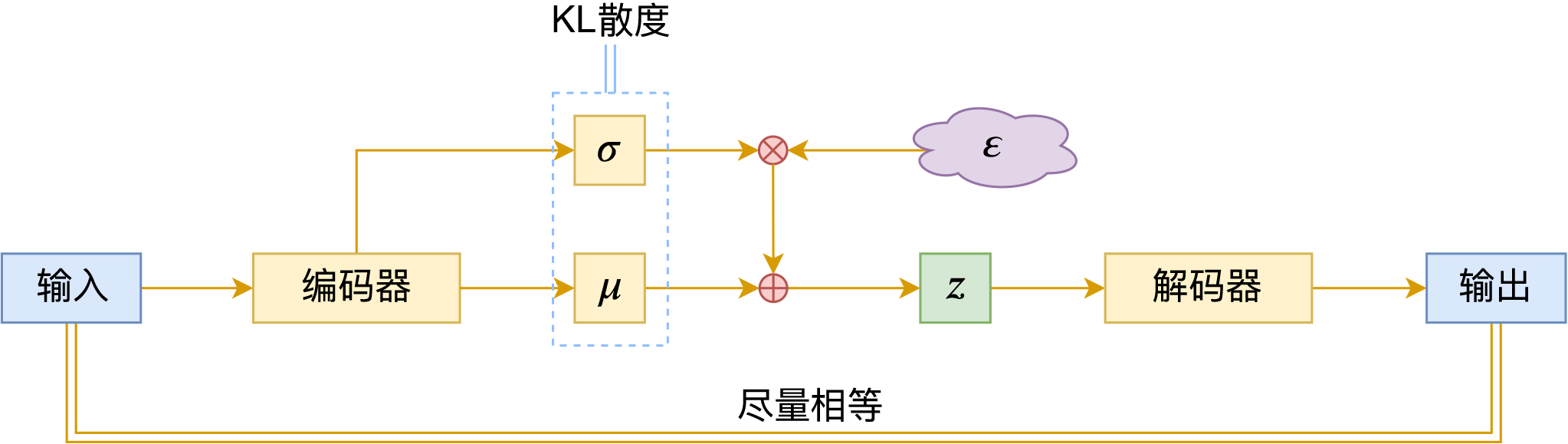
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 37498位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。

最近评论