






26
Sep
数学基本技艺之23、24(上)
By 苏剑林 | 2013-09-26 | 17379位读者 | 引用
28
Dec
矩阵描述三维空间旋转
By 苏剑林 | 2013-12-28 | 97401位读者 | 引用本节简单介绍用矩阵来描述旋转。在二维平面上,复数无疑是描述旋转的最佳工具;然而推广到三维空间中,却要动用到“四元数”了。为了证明四元数的相关结论,我们需要三维旋转的矩阵描述。最一般的旋转运动为:绕某一根轴旋转θ角度。这样我们就需要三个参数来描述它:确定一根轴至少需要两个参数,确定角度需要一个参数。因此,如果要用“数”来描述三维空间的伸缩和旋转的话,“三元数”显然是不够的,完成这一目的至少需要四元数。这也从另外一个角度反映了三元数的不存在性。
矩阵方法
首先我们认识到,如果旋转轴是坐标轴之一,那么旋转矩阵将是最简单的,比如向量\boldsymbol{x}=(x_0,y_0,z_0)^{T}绕z轴逆时针旋转\theta角后的坐标就可以描述为
\begin{equation}
\boldsymbol{R}_{\theta}\boldsymbol{x}\end{equation}
11
Jan
几何的数与数的几何:超复数的浅探究
By 苏剑林 | 2014-01-11 | 63930位读者 | 引用这也是我的期末论文之一...全文共17页,包括了四元数的构造方法,初等应用等。附录包括行列式与体积、三维旋转的描述等。使用LaTex进行写作(LaTex会让你爱上数学写作的)
几何的数与数的几何
――超复数的浅探究
摘要
今天,不论是数学还是物理的高维问题,都采用向量分析为基本工具,数学物理中难觅四元数的影子。然而在历史上,四元数的发展有着重要的意义。四元数(Quaternion)运算实际上是向量分析的“鼻祖”,向量点积和叉积的概念也首先出现在四元数的运算中,四元数的诞生还标记着非交换代数的开端。即使是现在,四元数还是计算机描述三维空间旋转问题最简单的工具。另外,作为复数的推广,四元数还为某些复数问题的一般化提供了思路。
本文把矩阵与几何适当地结合起来,利用矩阵行列式\det (AB) =(\det A)(\det B)这一性质得出了四元数以及更高维的超复数的生成规律,并讨论了它的一些性质以及它在描述旋转方面的应用。部分证明细节和不完善的思想放到了附录之中。
在学车的时候,我堂大哥曾问我一道作圆的问题:
三圆的外切圆和内切圆 (1)
平面上给出三个两两相切的圆以及它们的圆心,求作一个圆与这三个圆都相切(尺规作图)。
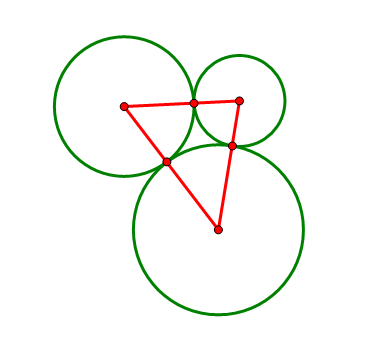
如果从纯几何的途径入手,我们甚至很难判断这样的圆是否存在。但是我之前似乎已经看过类似的题目,于是很快想到一个名词:反演。反演可以将圆反演成直线(圆过反演点),也可以将圆反演成圆(圆不过反演点),而其他的相切、相交等关系保持不变。对反演后的图形进行相同的反演,就变回原来的图形。本题的难点在于圆太多,利用反演,我们可以将它变为两条直线和一个圆的问题。
假设读者已经有了反演的基本知识,如果没有,请到
http://zh.wikipedia.org/wiki/反演
阅读相关内容。
19
Mar
一本对称闯物理:相对论力学(一)
By 苏剑林 | 2014-03-19 | 32917位读者 | 引用简单说说

《可畏的对称》
笔者最近陶醉于从李对称的角度来理解力学和场论,并且计算得到一些比较有趣的结果,遂想在此与大家分享。我发现,仅仅需要一个描述对称的无穷小生成元和一些最基本的假设,几乎就可以完成地推导出整个相对论力学来,甚至推导出整个(经典)场论理论来。这确实是不可思议的,我现在能基本体会到当年徐一鸿大师写的《可畏的对称》的含义了。对称的威力如此之大,以至于我们真的不得不敬畏它。而在构思本文题目的时候,我也曾想到过用“可畏的对称”为题,但不免有抄袭和老套之嫌。后来想到曾有一部漫画叫《一本漫画闯天涯》,遂将“漫画”改成“对称”,“天涯”改成“物理”,似乎也能表达我对“对称”的感觉。
对称就是在某种变换下保持不变的性质,比如狭义相对论要求所有物理定律在所有惯性系中保持不变,这相对于要求描述物理定律的方程在匀速运动的坐标变换下保持不变,结合光速不变的要求,我们就可以推导出洛伦兹变换,从而完成地描述了狭义相对论里边的对称。然而,并不是任何时候都可以想推导洛伦兹变换那样,能够把一个完整的变换推导出来的。幸好,李对称的不需要完整的对称描述,它只需要“无穷小变换”(意味着我们可以忽略掉高阶项),对应地产生一个“无穷小生成元”,用这个无穷小生成元,就足以完整构建出我们所需要的物理来。这种“无穷小”决定“广泛”、“局部”决定“全局”的奇妙至今仍让我觉得不可思议。(关于李对称、无穷小生成元的基本概念,不妨先阅读:《求解微分方程的李对称方法》)
27
Feb
从Knotsevich在黑板上写的级数题目谈起
By 苏剑林 | 2015-02-27 | 32366位读者 | 引用
2
May
寻求一个光滑的最大值函数
By 苏剑林 | 2015-05-02 | 151502位读者 | 引用在最优化问题中,求一个函数的最大值或最小值,最直接的方法是求导,然后比较各阶极值的大小。然而,我们所要优化的函数往往不一定可导,比如函数中含有最大值函数\max(x,y)的。这时候就得求助于其他思路了。有一个很巧妙的思路是,将这些不可导函数用一个可导的函数来近似它,从而我们用求极值的方法来求出它近似的最优值。本文的任务,就是探究一个简单而有用的函数,它能够作为最大值函数的近似,并且具有多阶导数。下面是笔者给出的一个推导过程。
在数学分析中,笔者已经学习过一个关于最大值函数的公式,即当x \geq 0, y \geq 0时,我们有
\max(x,y)=\frac{1}{2}\left(|x+y|+|x-y|\right)\tag{1}
那么,为了寻求一个最大值的函数,我们首先可以考虑寻找一个能够近似表示绝对值|x|的函数,这样我们就把问题从二维降低到一维了。那么,哪个函数可以使用呢?
13
Jun
“噪声对比估计”杂谈:曲径通幽之妙
By 苏剑林 | 2018-06-13 | 197657位读者 | 引用说到噪声对比估计,或者“负采样”,大家可能立马就想到了Word2Vec。事实上,它的含义远不止于此,噪音对比估计(NCE, Noise Contrastive Estimation)是一个迂回但却异常精美的技巧,它使得我们在没法直接完成归一化因子(也叫配分函数)的计算时,就能够去估算出概率分布的参数。本文就让我们来欣赏一下NCE的曲径通幽般的美妙。
注:由于出发点不同,本文所介绍的“噪声对比估计”实际上更偏向于所谓的“负采样”技巧,但两者本质上是一样的,在此不作区分。
问题起源
问题的根源是难分难舍的指数概率分布~
指数族分布
在很多问题中都会出现指数族分布,即对于某个变量\boldsymbol{x}的概率p(\boldsymbol{x}),我们将其写成
p(\boldsymbol{x}) = \frac{e^{G(\boldsymbol{x})}}{Z}\tag{1}
其中G(\boldsymbol{x})是\boldsymbol{x}的某个“能量”函数,而Z=\sum_{\boldsymbol{x}} e^{G(\boldsymbol{x})}则是归一化常数,也叫配分函数。这种分布也称为“玻尔兹曼分布”。

最近评论