






10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 271578位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
Lθ=Ez∼pθ(z)[f(z)]
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现(f(z)对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于z的连续性,它对应不同的形式:
∫pθ(z)f(z)dz(连续情形)∑zpθ(z)f(z)(离散情形)
当然,离散情况下我们更喜欢将记号z换成y或者c。
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 310498位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
3
May
从动力学角度看优化算法(四):GAN的第三个阶段
By 苏剑林 | 2019-05-03 | 109353位读者 | 引用在对GAN的学习和思考过程中,我发现我不仅学习到了一种有效的生成模型,而且它全面地促进了我对各种模型各方面的理解,比如模型的优化和理解视角、正则项的意义、损失函数与概率分布的联系、概率推断等等。GAN不单单是一个“造假的玩具”,而是具有深刻意义的概率模型和推断方法。
作为事后的总结,我觉得对GAN的理解可以粗糙地分为三个阶段:
1、样本阶段:在这个阶段中,我们了解了GAN的“鉴别者-造假者”诠释,懂得从这个原理出发来写出基本的GAN公式(如原始GAN、LSGAN),比如判别器和生成器的loss,并且完成简单GAN的训练;同时,我们知道GAN有能力让图片更“真”,利用这个特性可以把GAN嵌入到一些综合模型中。
2、分布阶段:在这个阶段中,我们会从概率分布及其散度的视角来分析GAN,典型的例子是WGAN和f-GAN,同时能基本理解GAN的训练困难问题,比如梯度消失和mode collapse等,甚至能基本地了解变分推断,懂得自己写出一些概率散度,继而构造一些新的GAN形式。
3、动力学阶段:在这个阶段中,我们开始结合优化器来分析GAN的收敛过程,试图了解GAN是否能真的达到理论的均衡点,进而理解GAN的loss和正则项等因素如何影响的收敛过程,由此可以针对性地提出一些训练策略,引导GAN模型到达理论均衡点,从而提高GAN的效果。
31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 125807位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 538202位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 188150位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
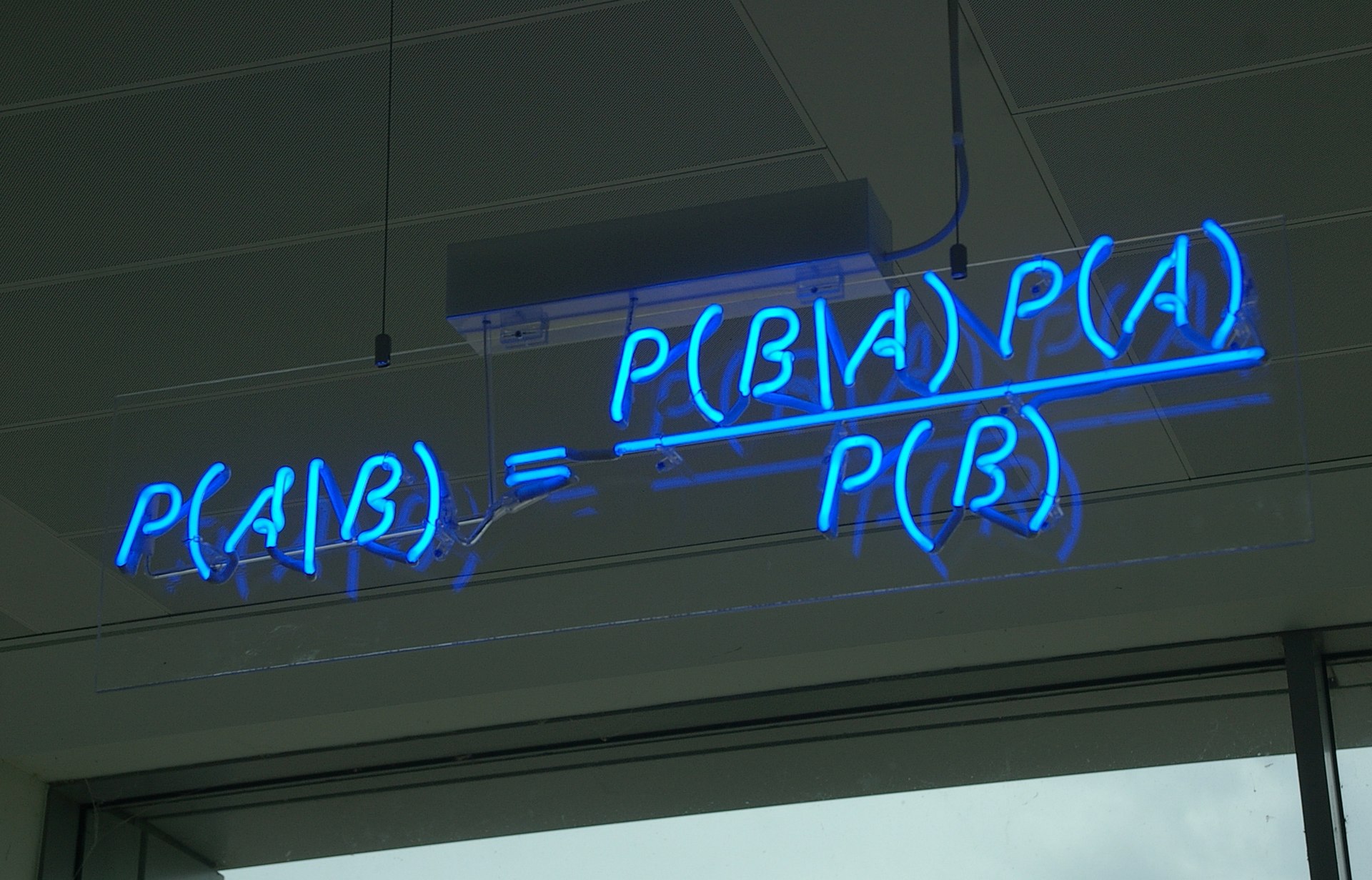
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
24
Jun
生成扩散模型漫谈(十九):作为扩散ODE的GAN
By 苏剑林 | 2023-06-24 | 40028位读者 | 引用在文章《生成扩散模型漫谈(十六):W距离 ≤ 得分匹配》中,我们推导了Wasserstein距离与扩散模型得分匹配损失之间的一个不等式,表明扩散模型的优化目标与WGAN的优化目标在某种程度上具有相似性。而在本文,我们将探讨《MonoFlow: Rethinking Divergence GANs via the Perspective of Wasserstein Gradient Flows》中的研究成果,它进一步展示了GAN与扩散模型之间的联系:GAN实际上可以被视为在另一个时间维度上的扩散ODE!
这些发现表明,尽管GAN和扩散模型表面上是两种截然不同的生成式模型,但它们实际上存在许多相似之处,并在许多方面可以相互借鉴和参考。
思路简介
我们知道,GAN所训练的生成器是从噪声\boldsymbol{z}到真实样本的一个直接的确定性变换\boldsymbol{g}_{\boldsymbol{\theta}}(\boldsymbol{z}),而扩散模型的显著特点是“渐进式生成”,它的生成过程对应于从一系列渐变的分布p_0(\boldsymbol{x}_0),p_1(\boldsymbol{x}_1),\cdots,p_T(\boldsymbol{x}_T)中采样(注:在前面十几篇文章中,\boldsymbol{x}_T是噪声,\boldsymbol{x}_0是目标样本,采样过程是\boldsymbol{x}_T\to \boldsymbol{x}_0,但为了便于下面的表述,这里反过来改为\boldsymbol{x}_0\to \boldsymbol{x}_T)。看上去确实找不到多少相同之处,那怎么才能将两者联系起来呢?
6
Nov
这个星期对微分方程的认识
By 苏剑林 | 2010-11-06 | 38878位读者 | 引用这个星期研究了两道微分方程问题:“导弹跟踪”以及“太阳炉”问题。从中我加深了对微分方程的理解,也熟悉了微分方程的相关运算。仅此记录,权当抛砖引玉。
一、微分方程的本质
很多读者都知道,自从牛顿和莱布尼兹发明微积分之后,微积分就迅速地渗透到了几乎所有的学科,后来发展出许多出色的分支,如变分、微分方程等。众所周知,微分方程是解决很多重要问题的工具。不知道各位读者对微分及微分方程的认识如何?其实对于常微分方程而言,它的本质和我们已经学习过的代数方程一样,只不过相互之间的对应运算关系除了常规的加减乘除幂等之外,还多了两个相互关系:微分和积分。例如对于一阶微分方程\dot{y}=f(x,y),也许大家都认为它是一个二元方程,其实不然,这是一个“四个未知数、三道方程”所组成的方程组,我们可以将它写成
dy=f(x,y)dx,y=\int dy,x=\int dx

最近评论