






2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 68247位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 145094位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在Q,K转置相乘之后还要除以一个√d再做Softmax(下面均不失一般性地假设Q,K,V∈Rn×d):
Attention(Q,K,V)=softmax(QK⊤√d)V
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以√d的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
oi=n∑j=1ai,jvj,ai,j=eλqi⋅kjn∑j=1eλqi⋅kj
其中λ是缩放因子,它跟qi,kj无关,但原则上可以跟长度n、维度d等参数有关,目前主流的就是λ=1/√d。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 219522位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
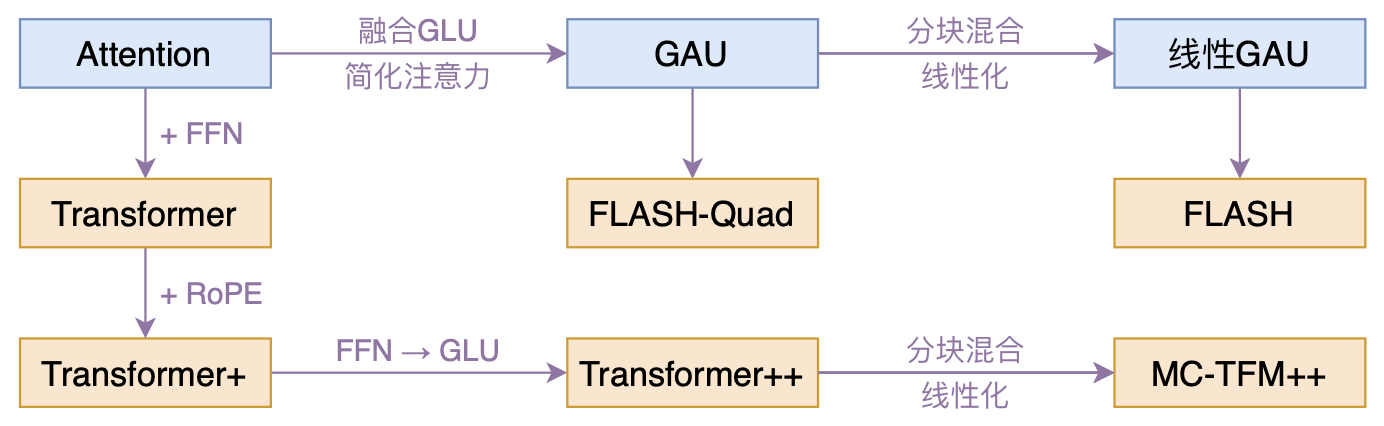
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 70914位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 94985位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的relu2除以序列长度:
A=1nrelu2(Q(Z)K(Z)⊤√s)=1nsrelu2(Q(Z)K(Z)⊤)
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 537315位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 165007位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
编码:x→z,生成:z→x
12
Jan
Transformer升级之路:7、长度外推性与局部注意力
By 苏剑林 | 2023-01-12 | 112172位读者 | 引用对于Transformer模型来说,其长度的外推性是我们一直在追求的良好性质,它是指我们在短序列上训练的模型,能否不用微调地用到长序列上并依然保持不错的效果。之所以追求长度外推性,一方面是理论的完备性,觉得这是一个理想模型应当具备的性质,另一方面也是训练的实用性,允许我们以较低成本(在较短序列上)训练出一个长序列可用的模型。
下面我们来分析一下加强Transformer长度外推性的关键思路,并由此给出一个“超强基线”方案,然后我们带着这个“超强基线”来分析一些相关的研究工作。
思维误区
第一篇明确研究Transformer长度外推性的工作应该是ALIBI,出自2021年中期,距今也不算太久。为什么这么晚(相比Transformer首次发表的2017年)才有人专门做这个课题呢?估计是因为我们长期以来,都想当然地认为Transformer的长度外推性是位置编码的问题,找到更好的位置编码就行了。

最近评论