






29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 82081位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
10
Dec
BiGAN-QP:简单清晰的编码&生成模型
By 苏剑林 | 2018-12-10 | 70883位读者 | 引用前不久笔者通过直接在对偶空间中分析的思路,提出了一个称为GAN-QP的对抗模型框架,它的特点是可以从理论上证明既不会梯度消失,又不需要L约束,使得生成模型的搭建和训练都得到简化。
GAN-QP是一个对抗框架,所以理论上原来所有的GAN任务都可以往上面试试。前面《不用L约束又不会梯度消失的GAN,了解一下?》一文中我们只尝试了标准的随机生成任务,而这篇文章中我们尝试既有生成器、又有编码器的情况:BiGAN-QP。
BiGAN与BiGAN-QP
注意这是BiGAN,不是前段时间很火的BigGAN,BiGAN是双向GAN(Bidirectional GAN),提出于《Adversarial feature learning》一文,同期还有一篇非常相似的文章叫做《Adversarially Learned Inference》,提出了叫做ALI的模型,跟BiGAN差不多。总的来说,它们都是往普通的GAN模型中加入了编码器,使得模型既能够具有普通GAN的随机生成功能,又具有编码器的功能,可以用来提取有效的特征。把GAN-QP这种对抗模式用到BiGAN中,就得到了BiGAN-QP。
话不多说,先来上效果图(左边是原图,右边是重构):

BiGAN-QP重构效果图
28
Jun
积分梯度:一种新颖的神经网络可视化方法
By 苏剑林 | 2020-06-28 | 100805位读者 | 引用本文介绍一种神经网络的可视化方法:积分梯度(Integrated Gradients),它首先在论文《Gradients of Counterfactuals》中提出,后来《Axiomatic Attribution for Deep Networks》再次介绍了它,两篇论文作者都是一样的,内容也大体上相同,后一篇相对来说更易懂一些,如果要读原论文的话,建议大家优先读后一篇。当然,它已经是2016~2017年间的工作了,“新颖”说的是它思路上的创新有趣,而不是指最近发表。

笔者在中文情感分类上对积分梯度的实验效果(越红的token越重要)
所谓可视化,简单来说就是对于给定的输入x以及模型F(x),我们想办法指出x的哪些分量对模型的决策有重要影响,或者说对x各个分量的重要性做个排序,用专业的话术来说那就是“归因”。一个朴素的思路是直接使用梯度∇xF(x)来作为x各个分量的重要性指标,而积分梯度是对它的改进。然而,笔者认为,很多介绍积分梯度方法的文章(包括原论文),都过于“生硬”(形式化),没有很好地突出积分梯度能比朴素梯度更有效的本质原因。本文试图用自己的思路介绍一下积分梯度方法。
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 60896位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
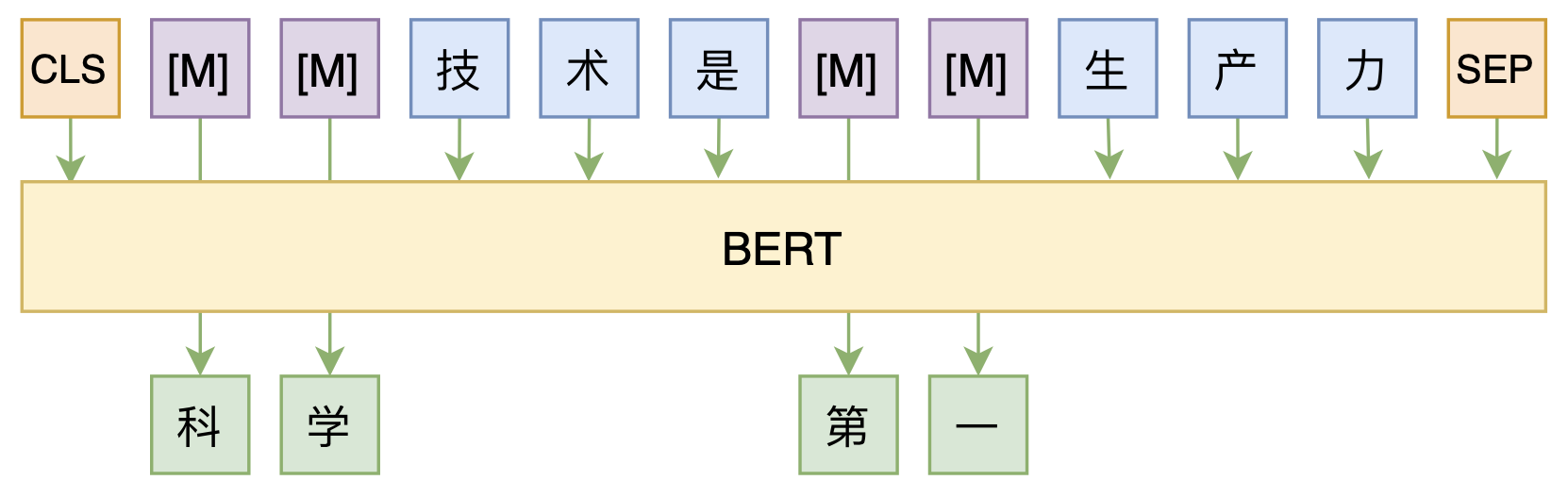
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 117593位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在Rn上的连续型概率分布,其概率密度函数为
p(x)=1√(2π)ndet(Σ)exp{−12(x−μ)⊤Σ−1(x−μ)}
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 64685位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 42929位读者 | 引用
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 127356位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。

最近评论