






10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 252593位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现(f(z)对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于z的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号z换成y或者c。
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 146815位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}三个向量序列的交互和融合,其中\boldsymbol{Q},\boldsymbol{K}的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把\boldsymbol{V}按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 119290位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 77827位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
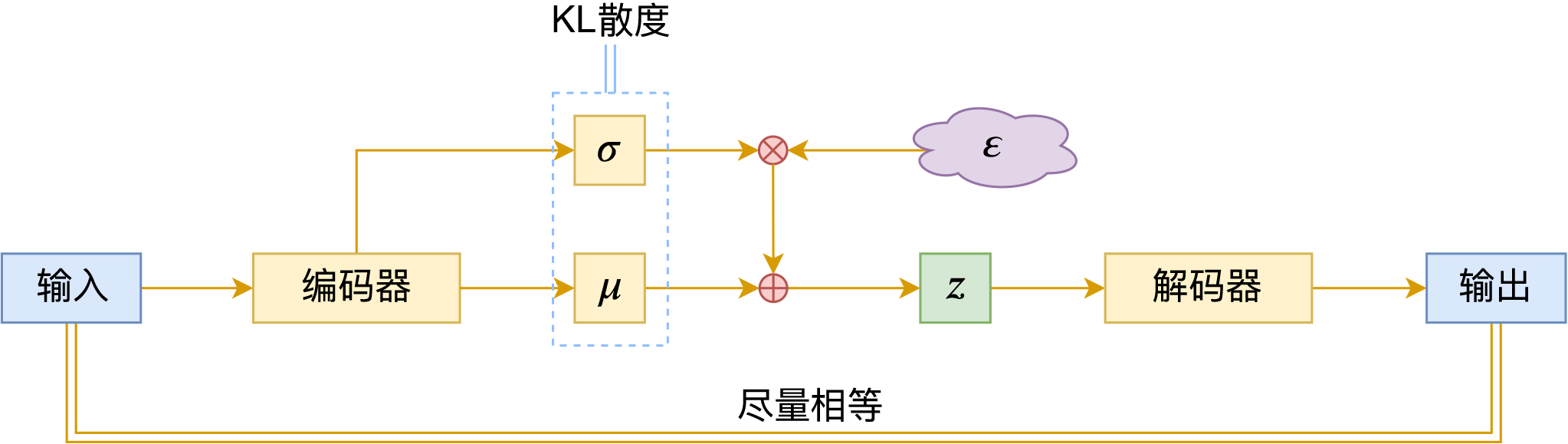
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 105402位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如L_1, L_2惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为f(x),\mathcal{D}为训练数据集合,l(f(x), y)为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
\theta是f(x)里边的可训练参数。假如往模型输入添加噪声\varepsilon,其分布为q(\varepsilon),那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重\theta,甚至可以是输出y(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,q(\varepsilon)的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布U([0,1])或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
22
Oct
从梯度最大化看Attention的Scale操作
By 苏剑林 | 2023-10-22 | 81060位读者 | 引用我们知道,Scaled Dot-Product Attention的Scale因子是\frac{1}{\sqrt{d}},其中d是\boldsymbol{q},\boldsymbol{k}的维度。这个Scale因子的一般解释是:如果不除以\sqrt{d},那么初始的Attention就会很接近one hot分布,这会造成梯度消失,导致模型训练不起来。然而,可以证明的是,当Scale等于0时同样也会有梯度消失问题,这也就是说Scale太大太小都不行。
那么多大的Scale才适合呢?\frac{1}{\sqrt{d}}是最佳的Scale了吗?本文试图从梯度角度来回答这个问题。
已有结果
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经推导过标准的Scale因子\frac{1}{\sqrt{d}},推导的思路很简单,假设初始阶段\boldsymbol{q},\boldsymbol{k}\in\mathbb{R}^d都采样自“均值为0、方差为1”的分布,那么可以算得
\begin{equation}\mathbb{V}ar[\boldsymbol{q}\cdot\boldsymbol{k}] = d\end{equation}
28
Oct
在Python中使用GMP(gmpy2)
By 苏剑林 | 2014-10-28 | 70373位读者 | 引用之前笔者曾写过《初试在Python中使用PARI/GP》,简单介绍了一下在Python中调用PARI/GP的方法。PARI/GP是一个比较强大的数论库,“针对数论中的快速计算(大数分解,代数数论,椭圆曲线...)而设计”,它既可以被C/C++或Python之类的编程语言调用,而且它本身又是一种自成一体的脚本语言。而如果仅仅需要高精度的大数运算功能,那么GMP似乎更满足我们的需求。
了解C/C++的读者都会知道GMP(全称是GNU Multiple Precision Arithmetic Library,即GNU高精度算术运算库),它是一个开源的高精度运算库,其中不但有普通的整数、实数、浮点数的高精度运算,还有随机数生成,尤其是提供了非常完备的数论中的运算接口,比如Miller-Rabin素数测试算法、大素数生成、欧几里德算法、求域中元素的逆、Jacobi符号、legendre符号等[来源]。虽然在C/C++中调用GMP并不算复杂,但是如果能在以高开发效率著称的Python中使用GMP,那么无疑是一件快事。这正是本文要说的gmpy2。
31
May
基于最小熵原理的NLP库:nlp zero
By 苏剑林 | 2018-05-31 | 109972位读者 | 引用陆陆续续写了几篇最小熵原理的博客,致力于无监督做NLP的一些基础工作。为了方便大家实验,把文章中涉及到的一些算法封装为一个库,供有需要的读者测试使用。
由于面向的是无监督NLP场景,而且基本都是NLP任务的基础工作,因此命名为nlp zero。
地址
Github: https://github.com/bojone/nlp-zero
Pypi: https://pypi.org/project/nlp-zero/
可以直接通过
pip install nlp-zero==0.1.6进行安装。整个库纯Python实现,没有第三方调用,支持Python2.x和3.x。

最近评论