






14
Feb
多任务学习漫谈(三):分主次之序
By 苏剑林 | 2022-02-14 | 38827位读者 | 引用多任务学习是一个很宽泛的命题,不同场景下多任务学习的目标不尽相同。在《多任务学习漫谈(一):以损失之名》和《多任务学习漫谈(二):行梯度之事》中,我们将多任务学习的目标理解为“做好每一个任务”,具体表现是“尽量平等地处理每一个任务”,我们可以称之为“平行型多任务学习”。然而,并不是所有多任务学习的目标都是如此,在很多场景下,我们主要还是想学好某一个主任务,其余任务都只是辅助,希望通过增加其他任务的学习来提升主任务的效果罢了,此类场景我们可以称为“主次型多任务学习”。
在这个背景下,如果还是沿用平行型多任务学习的“做好每一个任务”的学习方案,那么就可能会明显降低主任务的效果了。所以本文继续沿着“行梯度之事”的想法,探索主次型多任务学习的训练方案。
目标形式
在这篇文章中,我们假设读者已经阅读并且基本理解《多任务学习漫谈(二):行梯度之事》里边的思想和方法,那么在梯度视角下,让某个损失函数保持下降的必要条件是更新量与其梯度夹角至少大于90度,这是贯穿全文的设计思想。
21
Feb
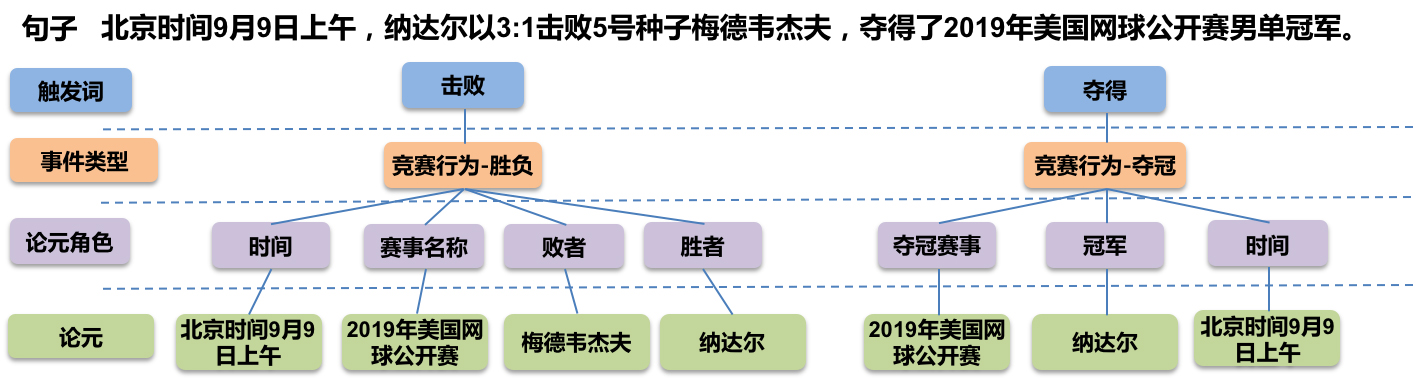
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 85072位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
标准的事件抽取样本(图片来自百度DuEE的GitHub)
2
Nov
利用CUR分解加速交互式相似度模型的检索
By 苏剑林 | 2022-11-02 | 34505位读者 | 引用文本相似度有“交互式”和“特征式”两种做法,想必很多读者对此已经不陌生,之前笔者也写过一篇文章《CoSENT(二):特征式匹配与交互式匹配有多大差距?》来对比两者的效果。总的来说,交互式相似度效果通常会好些,但直接用它来做大规模检索是不现实的,而特征式相似度则有着更快的检索速度,以及稍逊一筹的效果。
因此,如何在保证交互式相似度效果的前提下提高它的检索速度,是学术界一直都有在研究的课题。近日,论文《Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization》提出了一份新的答卷:CUR分解。

CUR分解示意图
21
Sep
生成扩散模型漫谈(十一):统一扩散模型(应用篇)
By 苏剑林 | 2022-09-21 | 51183位读者 | 引用在《生成扩散模型漫谈(十):统一扩散模型(理论篇)》中,笔者自称构建了一个统一的模型框架(Unified Diffusion Model,UDM),它允许更一般的扩散方式和数据类型。那么UDM框架究竟能否实现如期目的呢?本文通过一些具体例子来演示其一般性。
框架回顾
首先,UDM通过选择噪声分布q(\boldsymbol{\varepsilon})和变换\boldsymbol{\mathcal{F}}来构建前向过程
\begin{equation}\boldsymbol{x}_t = \boldsymbol{\mathcal{F}}_t(\boldsymbol{x}_0,\boldsymbol{\varepsilon}),\quad \boldsymbol{\varepsilon}\sim q(\boldsymbol{\varepsilon})\end{equation}
然后,通过如下的分解来实现反向过程\boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)的采样
\begin{equation}\hat{\boldsymbol{x}}_0\sim p(\boldsymbol{x}_0|\boldsymbol{x}_t)\quad \& \quad \boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\hat{\boldsymbol{x}}_0)\end{equation}
其中p(\boldsymbol{x}_0|\boldsymbol{x}_t)就是用\boldsymbol{x}_t预估\boldsymbol{x}_0的概率,一般用简单分布q(\boldsymbol{x}_0|\boldsymbol{x}_t)来近似建模,训练目标基本上就是-\log q(\boldsymbol{x}_0|\boldsymbol{x}_t)或其简单变体。当\boldsymbol{x}_0是连续型数据时,q(\boldsymbol{x}_0|\boldsymbol{x}_t)一般就取条件正态分布;当\boldsymbol{x}_0是离散型数据时,q(\boldsymbol{x}_0|\boldsymbol{x}_t)可以选择自回归模型或者非自回归模型。
28
Mar
Google新作试图“复活”RNN:RNN能否再次辉煌?
By 苏剑林 | 2023-03-28 | 66289位读者 | 引用当前,像ChatGPT之类的LLM可谓是“风靡全球”。有读者留意到,几乎所有LLM都还是用最初的Multi-Head Scaled-Dot Attention,近年来大量的Efficient工作如线性Attention、FLASH等均未被采用。是它们版本效果太差,还是根本没有必要考虑效率?其实答案笔者在《线性Transformer应该不是你要等的那个模型》已经分析过了,只有序列长度明显超过hidden size时,标准Attention才呈现出二次复杂度,在此之前它还是接近线性的,它的速度比很多Efficient改进都快,而像GPT3用到了上万的hidden size,这意味着只要你的LLM不是面向数万长度的文本生成,那么用Efficient改进是没有必要的,很多时候速度没提上去,效果还降低了。
那么,真有数万甚至数十万长度的序列处理需求时,我们又该用什么模型呢?近日,Google的一篇论文《Resurrecting Recurrent Neural Networks for Long Sequences》重新优化了RNN模型,特别指出了RNN在处理超长序列场景下的优势。那么,RNN能否再次辉煌?
26
Sep
脑洞大开:非线性RNN居然也可以并行计算?
By 苏剑林 | 2023-09-26 | 63849位读者 | 引用近年来,线性RNN由于其可并行训练以及常数推理成本等特性,吸引了一定研究人员的关注(例如笔者之前写的《Google新作试图“复活”RNN:RNN能否再次辉煌?》),这让RNN在Transformer遍地开花的潮流中仍有“一席之地”。然而,目前看来这“一席之地”只属于线性RNN,因为非线性RNN无法高效地并行训练,所以在架构之争中是“心有余而力不足”。
不过,一篇名为《Parallelizing Non-Linear Sequential Models over the Sequence Length》的论文有不同的看法,它提出了一种迭代算法,宣传可以实现非线性RNN的并行训练!真有如此神奇?接下来我们一探究竟。
求不动点
原论文对其方法做了非常一般的介绍,而且其侧重点是PDE和ODE,这里我们直接从RNN入手。考虑常见的简单非线性RNN:
\begin{equation}x_t = \tanh(Ax_{t-1} + u_t)\label{eq:rnn}\end{equation}
25
Dec
写了个刷论文的辅助网站:Cool Papers
By 苏剑林 | 2023-12-25 | 116163位读者 | 引用写在开头
一直以来,笔者都有日刷Arxiv的习惯,以求尽可能跟上领域内最新成果,并告诫自己“不进则退”。之前也有不少读者问我是怎么刷Arxiv的、有什么辅助工具等,但事实上,在很长的时间里,笔者都是直接刷Arxiv官网,并且没有用任何算法过滤,都是自己一篇篇过的。这个过程很枯燥,但并非不能接受,之所以不用算法初筛,主要还是担心算法漏召,毕竟“刷”就是为了追新,一旦算法漏召就“错失先机”了。
自从Kimi Chat发布后,笔者就一直计划着写一个辅助网站结合Kimi来加速刷论文的过程。最近几个星期稍微闲了一点,于是在GPT4、Kimi的帮助下,初步写成了这个网站,并且经过几天的测试和优化后,已经逐步趋于稳定,于是正式邀请读者试用。
Cool Papers:https://papers.cool
7
Mar
用傅里叶级数拟合一维概率密度函数
By 苏剑林 | 2024-03-07 | 37493位读者 | 引用在《“闭门造车”之多模态思路浅谈(一):无损输入》中我们曾提到,图像生成的本质困难是没有一个连续型概率密度的万能拟合器。当然,也不能说完全没有,比如高斯混合模型(GMM)理论上就是可以拟合任意概率密度,就连GAN本质上也可以理解为混合了无限个高斯模型的GMM。然而,GMM尽管理论上的能力是足够的,但它的最大似然估计会很困难,尤其是通常不适用基于梯度的优化器,这限制了它的使用场景。
近日,Google的一篇新论文《Fourier Basis Density Model》针对一维情形,提出了一个新的解决方案——用傅里叶级数来拟合。论文的分析过程颇为有趣,构造形式也很是巧妙,值得学习一番。
问题简述
可能有读者质疑:只研究一维情形有什么价值?确实,如果只考虑图像生成场景,那可能真的价值有限,但一维概率密度估计本身有它的应用价值,如数据的有损压缩,所以它依然是一个值得研究的主题。再者,即便我们需要研究多维的概率密度,也可以通过自回归的方式转化为多个一维的条件概率密度来估计。最后,这个分析和构造过程本身就很值得回味,所以哪怕是仅仅作为一道数学分析题来练习也是相当有益的。

最近评论