






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
30
Jul
Keras实现两个优化器:Lookahead和LazyOptimizer
By 苏剑林 | 2019-07-30 | 57016位读者 | Kimi 引用最近用Keras实现了两个优化器,也算是有点实现技巧,遂放在一起写篇文章简介一下(如果只有一个的话我就不写了)。这两个优化器的名字都挺有意思的,一个是look ahead(往前看?),一个是lazy(偷懒?),难道是两个完全不同的优化思路么?非也非也~只能说发明者们起名字太有创意了。
Lookahead
首先登场的是Lookahead优化器,它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 183779位读者 | Kimi 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
21
Jul
思考:两个椭圆片能粘合成一个立体吗?
By 苏剑林 | 2019-07-21 | 75562位读者 | Kimi 引用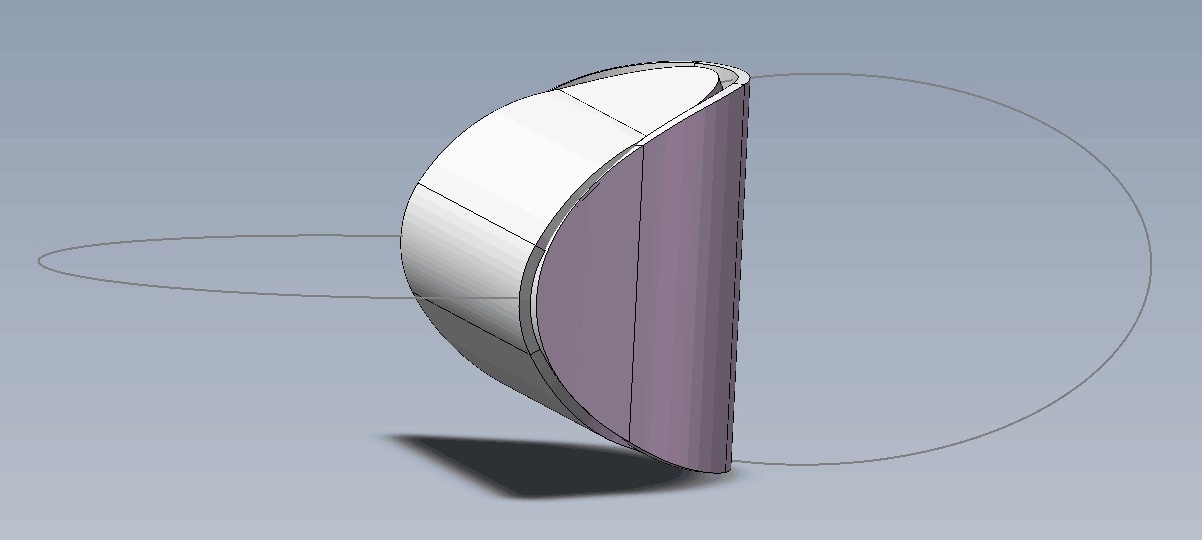
16
Jul
“让Keras更酷一些!”:层中层与mask
By 苏剑林 | 2019-07-16 | 189051位读者 | Kimi 引用这一篇“让Keras更酷一些!”将和读者分享两部分内容:第一部分是“层中层”,顾名思义,是在Keras中自定义层的时候,重用已有的层,这将大大减少自定义层的代码量;另外一部分就是应读者所求,介绍一下序列模型中的mask原理和方法。
层中层
在《“让Keras更酷一些!”:精巧的层与花式的回调》一文中我们已经介绍过Keras自定义层的基本方法,其核心步骤是定义build和call两个函数,其中build负责创建可训练的权重,而call则定义具体的运算。
拒绝重复劳动
经常用到自定义层的读者可能会感觉到,在自定义层的时候我们经常在重复劳动,比如我们想要增加一个线性变换,那就要在build中增加一个kernel和bias变量(还要自定义变量的初始化、正则化等),然后在call里边用K.dot来执行,有时候还需要考虑维度对齐的问题,步骤比较繁琐。但事实上,一个线性变换其实就是一个不加激活函数的Dense层罢了,如果在自定义层时能重用已有的层,那显然就可以大大节省代码量了。
8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 101976位读者 | Kimi 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 65669位读者 | Kimi 引用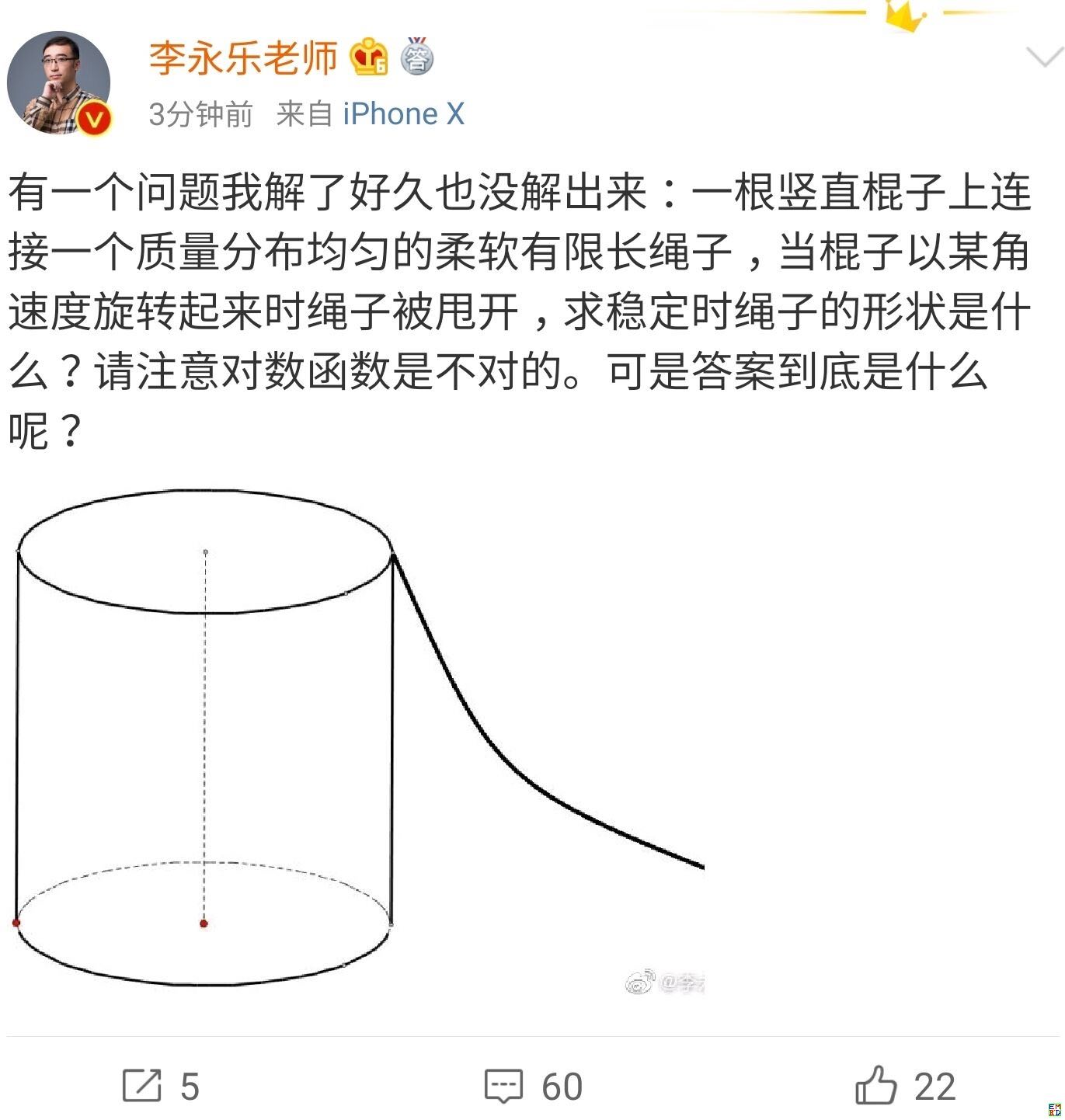
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 188974位读者 | Kimi 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 480350位读者 | Kimi 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。

最近评论