






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 144400位读者 | Kimi 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
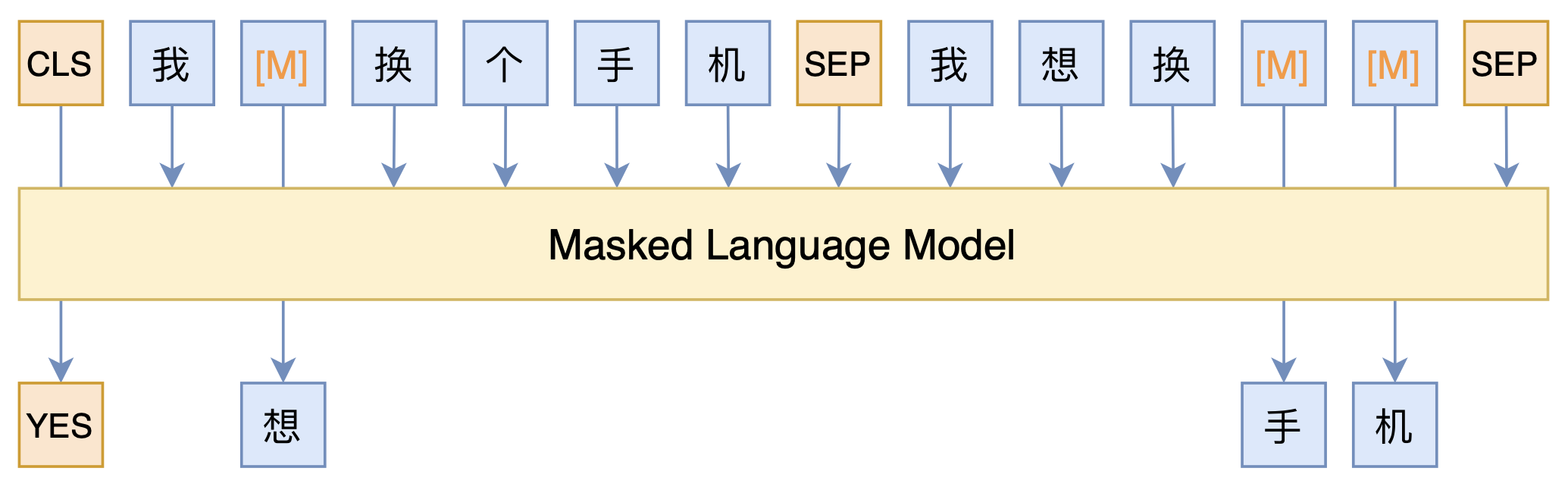
本文模型示意图
3
Mar
T5 PEGASUS:开源一个中文生成式预训练模型
By 苏剑林 | 2021-03-03 | 274712位读者 | Kimi 引用去年在文章《那个屠榜的T5模型,现在可以在中文上玩玩了》中我们介绍了Google的多国语言版T5模型(mT5),并给出了用mT5进行中文文本生成任务的例子。诚然,mT5做中文生成任务也是一个可用的方案,但缺乏完全由中文语料训练出来模型总感觉有点别扭,于是决心要搞一个出来。
经过反复斟酌测试,我们决定以mT5为基础架构和初始权重,先结合中文的特点完善Tokenizer,然后模仿PEGASUS来构建预训练任务,从而训练一版新的T5模型,这就是本文所开源的T5 PEGASUS。

T5 PEGASUS的训练数据示例
25
Feb
【搜出来的文本】⋅(四)通过增、删、改来用词造句
By 苏剑林 | 2021-02-25 | 65803位读者 | Kimi 引用“用词造句”是小学阶段帮助我们理解和运用词语的一个经典任务,从自然语言处理的角度来看,它是一个句子扩写或者句子补全任务,它其实要求我们具有不定向地进行文本生成的能力。然而,当前主流的语言模型都是单方向生成的(多数是正向的,即从左往右,少数是反向的,即从右往左),但用词造句任务中所给的若干个词未必一定出现在句首或者句末,这导致无法直接用语言模型来完成造句任务。
本文我们将介绍论文《CGMH: Constrained Sentence Generation by Metropolis-Hastings Sampling》,它使用MCMC采样使得单向语言模型也可以做到不定向生成,通过增、删、改操作模拟了人的写作润色过程,从而能无监督地完成用词造句等多种文本生成任务。
问题设置
无监督地进行文本采样,那么直接可以由语言模型来完成,而我们同样要做的,是往这个采样过程中加入一些信号$\boldsymbol{c}$,使得它能生成我们期望的一些文本。在本系列第一篇文章《【搜出来的文本】⋅(一)从文本生成到搜索采样》的“明确目标”一节中,我们就介绍了本系列的指导思想:把我们要寻找的目标量化地写下来,然后最大化它或者从中采样。
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 71810位读者 | Kimi 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
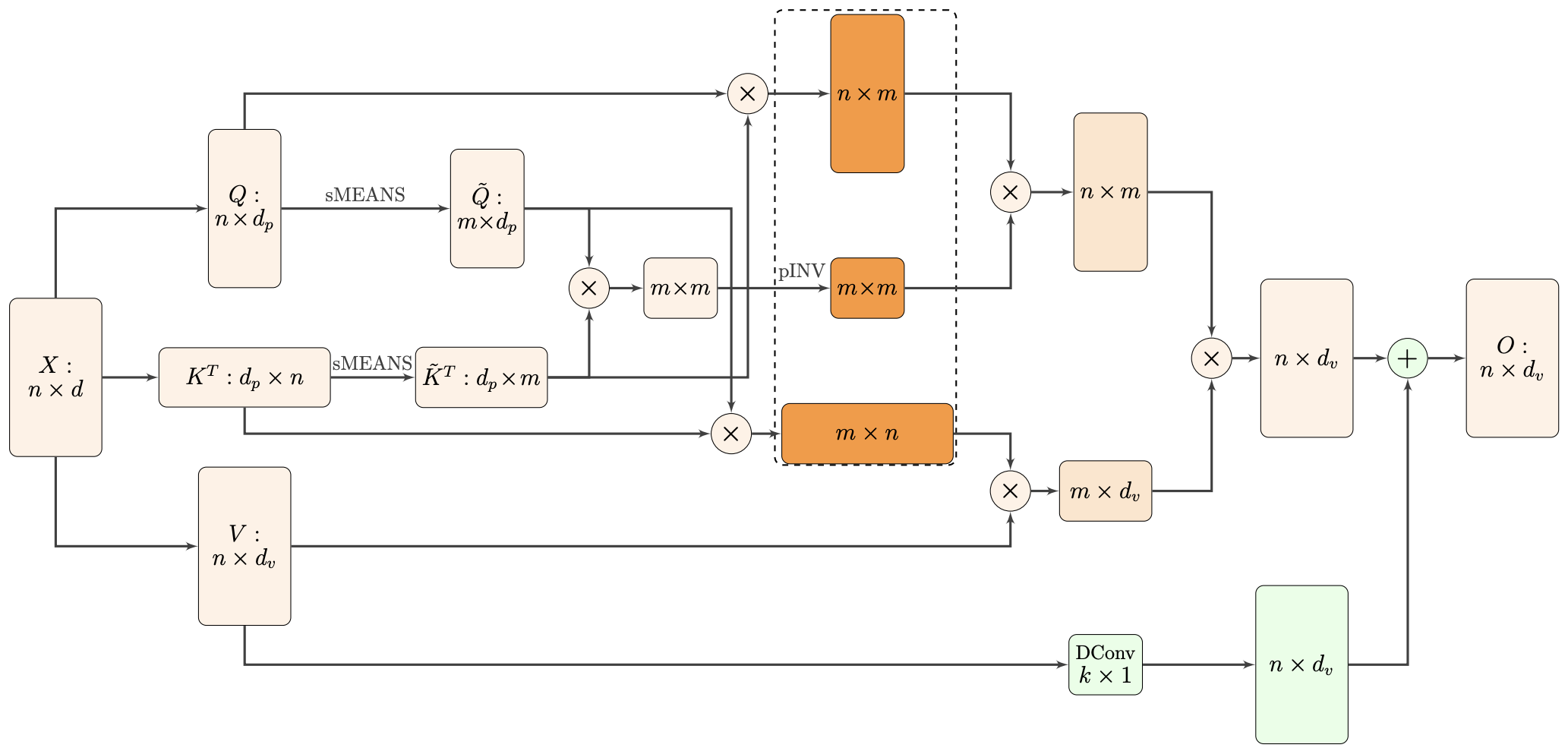
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
9
Feb
一个二值化词向量模型,是怎么跟果蝇搭上关系的?
By 苏剑林 | 2021-02-09 | 36172位读者 | Kimi 引用
果蝇(图片来自Google搜索)
可能有些读者最近会留意到ICLR 2021的论文《Can a Fruit Fly Learn Word Embeddings?》,文中写到它是基于仿生思想(仿果蝇的嗅觉回路)做出来的一个二值化词向量模型。其实论文的算法部分并不算难读,可能整篇论文读下来大家的最主要疑惑就是“这东西跟果蝇有什么关系?”、“作者真是从果蝇里边受到启发的?”等等。本文就让我们来追寻一下该算法的来龙去脉,试图回答一下这个词向量模型是怎么跟果蝇搭上关系的。
BioWord
原论文并没有给该词向量模型起个名字,为了称呼上的方便,这里笔者就自作主张将其称为“BioWord”了。总的来说,论文内容大体上有三部分:
1、给每个n-gram构建了一个词袋表示向量;
2、对这些n-gram向量执行BioHash算法,得到所谓的(二值化的)静态/动态词向量;
3、“拼命”讲了一个故事。
3
Feb
让研究人员绞尽脑汁的Transformer位置编码
By 苏剑林 | 2021-02-03 | 330490位读者 | Kimi 引用不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:1、想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;2、想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第$k$个向量$\boldsymbol{x}_k$中加入位置向量$\boldsymbol{p}_k$变为$\boldsymbol{x}_k + \boldsymbol{p}_k$,其中$\boldsymbol{p}_k$只依赖于位置编号$k$。
26
Jan
Seq2Seq重复解码现象的理论分析尝试
By 苏剑林 | 2021-01-26 | 44549位读者 | Kimi 引用去年笔者写过博文《如何应对Seq2Seq中的“根本停不下来”问题?》,里边介绍了一篇论文中对Seq2Seq解码不停止现象的处理,并指出那篇论文只是提了一些应对该问题的策略,并没有提供原理上的理解。近日,笔者在Arixv读到了AAAI 2021的一篇名为《A Theoretical Analysis of the Repetition Problem in Text Generation》的论文,里边从理论上分析了Seq2Seq重复解码现象。从本质上来看,重复解码和解码不停止其实都是同理的,所以这篇新论文算是填补了前面那篇论文的空白。
经过学习,笔者发现该论文确实有不少可圈可点之处,值得一读。笔者对原论文中的分析过程做了一些精简、修正和推广,将结果记录成此文,供大家参考。此外,抛开问题背景不讲,读者也可以将本文当成一节矩阵分析习题课,供大家复习线性代数哈~
22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 124645位读者 | Kimi 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~

最近评论