






3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 351377位读者 |在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
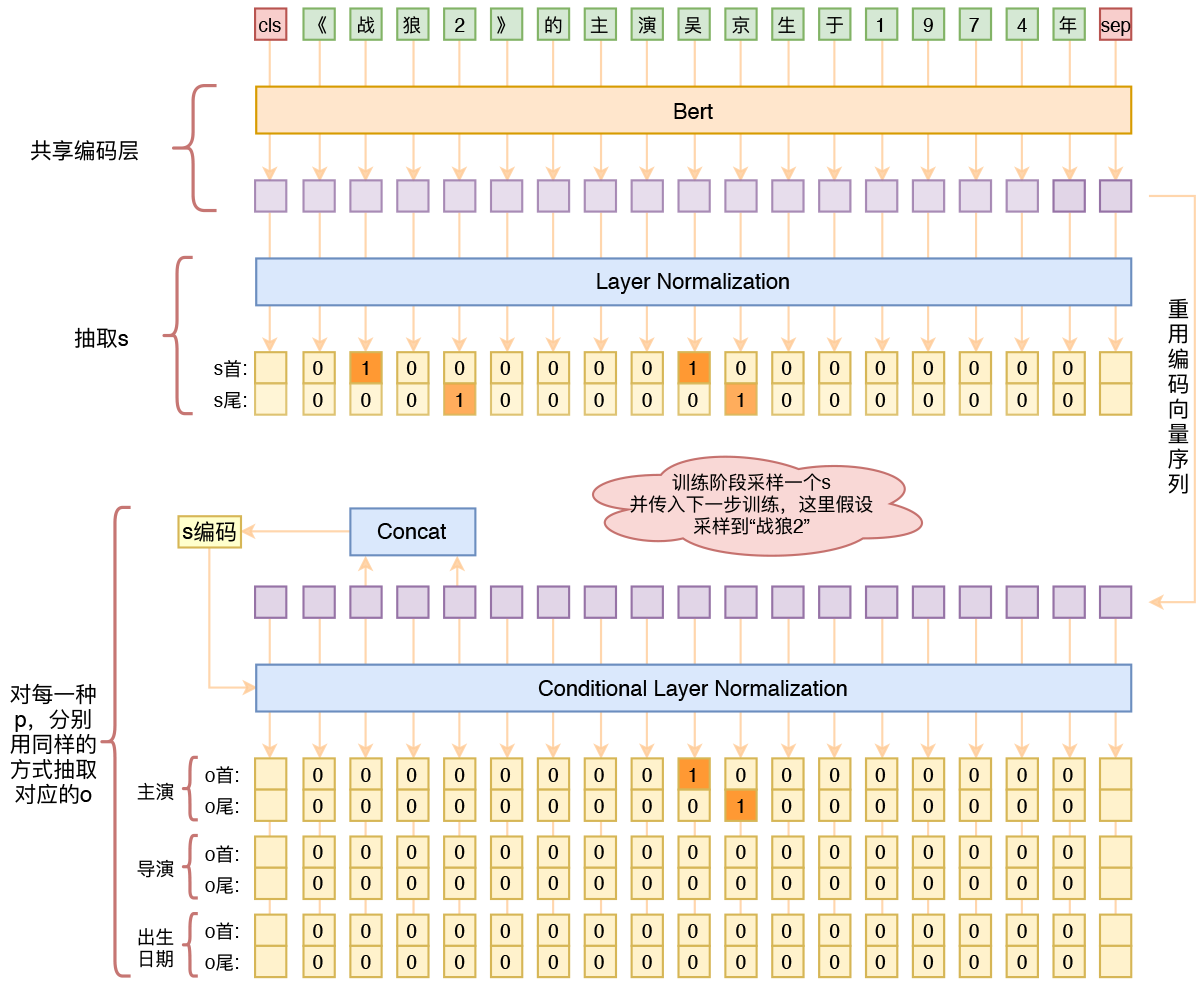
基于Bert的三元组抽取模型结构示意图
模型简介 #
关于数据格式和模型的基本思路,在《基于DGCNN和概率图的轻量级信息抽取模型》一文中已经详细介绍过了,在此不再重复。数据集百度已经公开了,在这里就可以下载。
跟之前的策略一样,模型依然是基于“半指针-半标注”的方式来做抽取,顺序是先抽取s,然后传入s来抽取o、p,不同的只是将模型的整体架构换成了bert:
1、原始序列转id后,传入bert的编码器,得到编码序列;
2、编码序列接两个二分类器,预测s;
3、根据传入的s,从编码序列中抽取出s的首和尾对应的编码向量;
4、以s的编码向量作为条件,对编码序列做一次条件Layer Norm;
5、条件Layer Norm后的序列来预测该s对应的o、p。
类别失衡 #
不难想到,用“半指针-半标注”结构做实体抽取时,会面临类别不均衡的问题,因为通常来说目标实体词比非目标词要少得多,所以标签1会比标签0少得多。常规的处理不平衡的方法都可以用,比如focal loss或者人工调节类权重,但这些方法用了之后,阈值就不大好取了。我这里用了一种自以为比较恰当的方法:将概率值做$n$次方。
具体来说,原来输出一个概率值$p$,代表类别1的概率是$p$,我现在将它变为$p^n$,也就是认为类别1的概率是$p^n$,除此之外不变,loss还是用正常的二分类交叉熵loss。由于原来就有$0\leq p \leq 1$,所以$p^n$整体会更接近于0,因此初始状态就符合目标分布了,所以最终能加速收敛。
从loss角度也可以比较两者的差异,假设标签为$t\in\{0, 1\}$,那么原来的loss是:
\begin{equation}- t \log p - (1 - t) \log (1 - p)\end{equation}
而$n$次方之后的loss就变成了
\begin{equation}- t \log p^n - (1 - t) \log (1 - p^n)\end{equation}
注意到$- t \log p^n = -nt \log p$,所以当标签为1时,相当于放大了loss的权重,而标签为0时,$(1 - p^n)$更接近于1,所以对应的loss $\log(1 - p^n)$更小(梯度也更小)。因此,这算是一种自适应调节loss权重(梯度权重)的思路了。
相比于focal loss或人工调节类权重,这种方法的好处是不改变原来内积($p$通常是内积加sigmoid得到的)的分布就能使得分布更加贴近目标,而不改变内积分布通常来说对优化更加友好。
源码效果 #
Github:task_relation_extraction.py
在没有任何前处理和后处理的情况下,最终在验证集上的f1为0.822,基本上比之前的DGCNN模型都要好。注意这是没有任何前后处理的,如果加上一些前后处理,估计可以f1达到0.83。
同时,我们可以发现训练集和验证集的标注有不少错漏之处,而当初我们做比赛的时候,线上测试集的标注质量比训练集和验证集都要高(更规范、更完整),所以当时提交测试的f1基本上要比线下验证集的f1高4%~5%,也就是说,加上一些规则修正后,这个结果如果提交到当时的排行榜上,单模型估计有0.87的f1。
值得注意 #
开头已经提到了,之前用keras-bert就写过一个用bert来抽三元组的例子了,而这里主要谈谈本文模型跟之前的例子不同之处以及一些值得注意的地方。
第一个不同之处是,当时仅仅是简单的尝试,所以仅仅是将s的向量加到编码序列中,然后做o、p的预测,而不是像本文一样用到条件Layer Norm;条件Layer Norm的方案有更好的表达能力,效果略微有提升。
第二个不同之处,也是值得留意的地方,就是本文的模型用的是标准的bert的tokenizer,而之前的例子是直接按字切分。标准的tokenizer出来的序列,并不是简单地按字切分的,尤其是函数英文和数字的情况下,输出的分词结果跟原始序列的字并非对齐的,所以在构建训练样本和输出结果时,都要格外留意这一点。
读者可能会疑问:那为什么不用回原来的按字切分的方式呢?笔者觉得,既然用了bert,应该按照bert的tokenizer,就算不对齐其实也有办法处理好的;而之前的按字切分,只是笔者当时还不够熟悉bert所导致的不规范用法,是不值得提倡的;遵循bert的tokenizer,还有可能比自己强行按字切分获得更好的finetune效果。
此外,笔者还发现一个有点意外的事实,就是中文bert所带的字表(vocab.txt)是不全的,比如“符箓”的“箓”字就不在bert的vocab.txt里边,所以要输出最终结果的时候,最好别用tokenizer自带的decode方法,而是直接对应到原始序列,在原始序列中切片输出。
最后,这一版模型的训练还加入了权重滑动平均,它可以稳定模型的训练,甚至能轻微提升模型的效果。关于权重滑动平均的相关介绍,可以参考这里。
文章小结 #
本文给出了用bert4keras来做三元组抽取的一个例子,并且指出了一些值得注意的事情,欢迎大家参考试用。
转载到请包括本文地址:https://spaces.ac.cn/archives/7161
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jan. 03, 2020). 《用bert4keras做三元组抽取 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7161
@online{kexuefm-7161,
title={用bert4keras做三元组抽取},
author={苏剑林},
year={2020},
month={Jan},
url={\url{https://spaces.ac.cn/archives/7161}},
}

March 31st, 2022
win上安装默认版本bert4keras和tensorflow会冲突,请问这俩相匹配的版本是啥啊
理想推荐:tensorflow 1.15
September 15th, 2022
[...]基于主实体感知的层叠式抽取网络,思路来源于苏神的科学空间,此思路还发表在ACL2020 ,见论文CasRel[...]
September 26th, 2022
[...]本文采用文章用bert4keras做三元组抽取中给出的关系抽取模型进行模型训练,其中训练集数据:测试集数据=8:2。模型的参数设置为maxlen=200, batch_size=16, epoch=20, 使用预训练模型为 哈工大的中文Robertaj[...]
February 17th, 2023
请问,图中结构示意图用什么工具画的,谢谢。
draw.io
February 24th, 2023
为啥我训练f1都是0,准确率都是1,召回率都是0
环境不对,或者没有训练足够多的步数。
March 13th, 2023
[...]基于主实体感知的层叠式抽取网络,思路来源于苏神的科学空间,此思路还发表在ACL2020 ,见论文CasRel[...]
March 22nd, 2023
AttributeError: module 'keras.engine.base_layer' has no attribute 'Node'这个报错怎么解决呀?呜呜呜
试试keras 2.3.1 + tf 1.15
April 3rd, 2023
你好,苏神。
为什么我的bert4keras运行不起来呢
tensorflow==1.14.0
keras==2.3.1
报错如下:
AttributeError: module 'tensorflow._api.v1.compat.v2.compat' has no attribute 'v1'
按道理不会有问题。试试tf 1.15?
June 25th, 2023
苏佬您好,我想请教一个问题,查了半个月没有找到答案,这个问题长久困扰着我,bert4keras里面支不支持对于输入位有填充,输出直接会忽略填充位计算?输入的填充位对应的输出为什么不是0?不是0的话合理吗?
有padding mask,防止attention到padding token。但是让padding部分输出为0是没有意义的(或者你说有什么意义?)