






13
Apr
突破瓶颈,打造更强大的Transformer
By 苏剑林 | 2020-04-13 | 191860位读者 | 引用自《Attention is All You Need》一文发布后,基于Multi-Head Attention的Transformer模型开始流行起来,而去年发布的BERT模型更是将Transformer模型的热度推上了又一个高峰。当然,技术的探索是无止境的,改进的工作也相继涌现:有改进预训练任务的,比如XLNET的PLM、ALBERT的SOP等;有改进归一化的,比如Post-Norm向Pre-Norm的改变,以及T5中去掉了Layer Norm里边的beta参数等;也有改进模型结构的,比如Transformer-XL等;有改进训练方式的,比如ALBERT的参数共享等;...
以上的这些改动,都是在Attention外部进行改动的,也就是说它们都默认了Attention的合理性,没有对Attention本身进行改动。而本文我们则介绍关于两个新结果:它们针对Multi-Head Attention中可能存在建模瓶颈,提出了不同的方案来改进Multi-Head Attention。两篇论文都来自Google,并且做了相当充分的实验,因此结果应该是相当有说服力的了。
再小也不能小key_size
第一个结果来自文章《Low-Rank Bottleneck in Multi-head Attention Models》,它明确地指出了Multi-Head Attention里边的表达能力瓶颈,并提出通过增大key_size的方法来缓解这个瓶颈。
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 253278位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
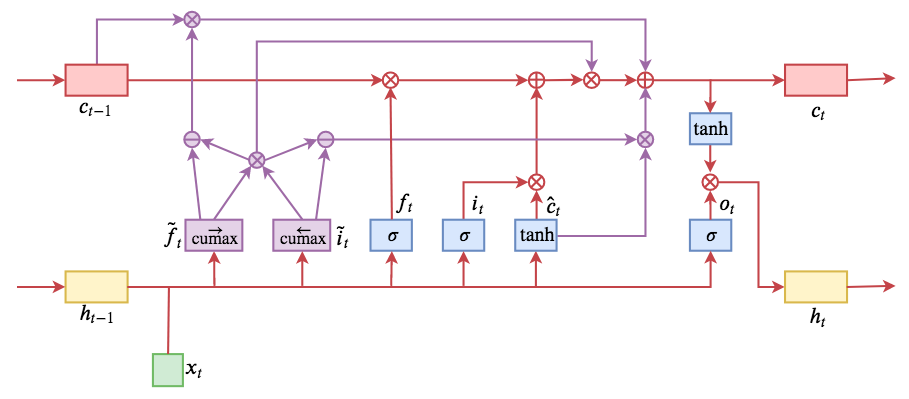
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~
6
Aug
“让Keras更酷一些!”:精巧的层与花式的回调
By 苏剑林 | 2018-08-06 | 209007位读者 | 引用Keras伴我走来
回想起进入机器学习领域的这两三年来,Keras是一直陪伴在笔者的身边。要不是当初刚掉进这个坑时碰到了Keras这个这么易用的框架,能快速实现我的想法,我也不确定我是否能有毅力坚持下来,毕竟当初是theano、pylearn、caffe、torch等的天下,哪怕在今天它们对我来说仍然像天书一般。
后来为了拓展视野,我也去学习了一段时间的tensorflow,用纯tensorflow写过若干程序,但不管怎样,仍然无法割舍Keras。随着对Keras的了解的深入,尤其是花了一点时间研究过Keras的源码后,我发现Keras并没有大家诟病的那样“欠缺灵活性”。事实上,Keras那精巧的封装,可以让我们轻松实现很多复杂的功能。我越来越感觉,Keras像是一件非常精美的艺术品,充分体现了Keras的开发者们深厚的创作功力。
本文介绍Keras中自定义模型的一些内容,相对而言,这属于Keras进阶的内容,刚入门的朋友请暂时忽略。
层的自定义
这里介绍Keras中自定义层及其一些运用技巧,在这之中我们可以看到Keras层的精巧之处。
18
Jul
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
By 苏剑林 | 2018-07-18 | 456007位读者 | 引用前言:我小学开始就喜欢纯数学,后来也喜欢上物理,还学习过一段时间的理论物理,直到本科毕业时,我才慢慢进入机器学习领域。所以,哪怕在机器学习领域中,我的研究习惯还保留着数学和物理的风格:企图从最少的原理出发,理解、推导尽可能多的东西。这篇文章是我这个理念的结果之一,试图以变分推断作为出发点,来统一地理解深度学习中的各种模型,尤其是各种让人眼花缭乱的GAN。本文已经挂到arxiv上,需要读英文原稿的可以移步到《Variational Inference: A Unified Framework of Generative Models and Some Revelations》。
下面是文章的介绍。其实,中文版的信息可能还比英文版要稍微丰富一些,原谅我这蹩脚的英语...
摘要:本文从一种新的视角阐述了变分推断,并证明了EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。其中,论文也表明了标准的GAN的优化目标是不完备的,这可以解释为什么GAN的训练需要谨慎地选择各个超参数。最后,文中给出了一个可以改善这种不完备性的正则项,实验表明该正则项能增强GAN训练的稳定性。
近年来,深度生成模型,尤其是GAN,取得了巨大的成功。现在我们已经可以找到数十个乃至上百个GAN的变种。然而,其中的大部分都是凭着经验改进的,鲜有比较完备的理论指导。
本文的目标是通过变分推断来给这些生成模型建立一个统一的框架。首先,本文先介绍了变分推断的一个新形式,这个新形式其实在博客以前的文章中就已经介绍过,它可以让我们在几行字之内导出变分自编码器(VAE)和EM算法。然后,利用这个新形式,我们能直接导出GAN,并且发现标准GAN的loss实则是不完备的,缺少了一个正则项。如果没有这个正则项,我们就需要谨慎地调整超参数,才能使得模型收敛。
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 556677位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 268768位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
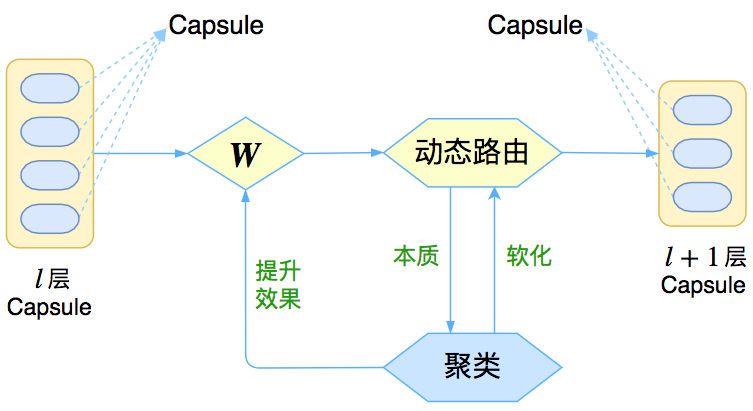
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
12
Feb
再来一顿贺岁宴:从K-Means到Capsule
By 苏剑林 | 2018-02-12 | 277974位读者 | 引用在本文中,我们再次对Capsule进行一次分析。
整体上来看,Capsule算法的细节不是很复杂,对照着它的流程把Capsule用框架实现它基本是没问题的。所以,困难的问题是理解Capsule究竟做了什么,以及为什么要这样做,尤其是Dynamic Routing那几步。
为什么我要反复对Capsule进行分析?这并非单纯的“炒冷饭”,而是为了得到对Capsule原理的理解。众所周知,Capsule给人的感觉就是“有太多人为约定的内容”,没有一种“虽然我不懂,但我相信应该就是这样”的直观感受。我希望尽可能将Capsule的来龙去脉思考清楚,使我们能觉得Capsule是一个自然、流畅的模型,甚至对它举一反三。
在《揭开迷雾,来一顿美味的Capsule盛宴》中,笔者先分析了动态路由的结果,然后指出输出是输入的某种聚类,这个“从结果到原因”的过程多多少少有些望文生义的猜测成分;这次则反过来,直接确认输出是输入的聚类,然后反推动态路由应该是怎样的,其中含糊的成分大大减少。两篇文章之间有一定的互补作用。
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 544208位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。

最近评论