






5
Jun
msign算子的Newton-Schulz迭代(下)
By 苏剑林 | 2025-06-05 | 21390位读者 | 引用在上文《msign算子的Newton-Schulz迭代(上)》中,我们试图为$\mathop{\text{msign}}$算子寻找更好的Newton-Schulz迭代,以期在有限迭代步数内能达到尽可能高的近似程度,这一过程又可以转化为标量函数$\mathop{\text{sign}}(x)$寻找同样形式的多项式迭代。当时,我们的求解思路是用Adam优化器端到端地求一个局部最优解,虽然有效但稍显粗暴。
而在几天前,arXiv新出了一篇论文《The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm》,作者运用了一系列精妙的数学结论,以优雅且硬核的方式给出了更漂亮的答案。本文让我们一起欣赏和学习一番这篇精彩的论文。
问题描述
相关背景和转化过程我们就不再重复了,直接给出我们要求解的问题是
\begin{equation}\mathop{\text{argmin}}_f d(f(x),1)\end{equation}
11
May
msign算子的Newton-Schulz迭代(上)
By 苏剑林 | 2025-05-11 | 28951位读者 | 引用在之前的《Muon优化器赏析:从向量到矩阵的本质跨越》、《Muon续集:为什么我们选择尝试Muon?》等文章中,我们介绍了一个极具潜力、有望替代Adam的新兴优化器——“Muon”。随着相关研究的不断深入,Muon优化器受到的关注度也在日益增加。
了解过Muon的读者都知道,Muon的核心运算是$\newcommand{msign}{\mathop{\text{msign}}}\msign$算子,为其寻找更高效的计算方法是学术社区的一个持续目标。本文将总结一下它的最新进展。
写在前面
$\msign$的定义跟SVD密切相关。假设矩阵$\boldsymbol{M}\in\mathbb{R}^{n\times m}$,那么
\begin{equation}\boldsymbol{U},\boldsymbol{\Sigma},\boldsymbol{V}^{\top} = \text{SVD}(\boldsymbol{M}) \quad\Rightarrow\quad \msign(\boldsymbol{M}) = \boldsymbol{U}_{[:,:r]}\boldsymbol{V}_{[:,:r]}^{\top}\end{equation}
其中$\boldsymbol{U}\in\mathbb{R}^{n\times n},\boldsymbol{\Sigma}\in\mathbb{R}^{n\times m},\boldsymbol{V}\in\mathbb{R}^{m\times m}$,$r$是$\boldsymbol{M}$的秩。简单来说,$\msign$就是把矩阵的所有非零奇异值都变成1后所得的新矩阵。
24
Mar
高阶MuP:更简明但更高明的谱条件缩放
By 苏剑林 | 2025-03-24 | 39407位读者 | 引用在文章《初探MuP:超参数的跨模型尺度迁移规律》中,我们基于前向传播、反向传播、损失增量和特征变化的尺度不变性推导了MuP(Maximal Update Parametrization)。可能对于部分读者来说,这一过程还是显得有些繁琐,但实际上它比原始论文已经明显简化。要知道,我们是在单篇文章内相对完整地介绍的MuP,而MuP的论文实际上是作者Tensor Programs系列论文的第5篇!
不过好消息是,作者在后续的研究《A Spectral Condition for Feature Learning》中,发现了一种新的理解方式(下称“谱条件”),它比MuP的原始推导和笔者的推导都更加直观和简洁,但却能得到比MuP更丰富的结果,可谓MuP的高阶版本,简明且不失高明的代表作。
准备工作
顾名思义,谱条件(Spectral Condition)跟谱范数(Spectral Norm)相关,它的出发点是谱范数的一个基本不等式:
\begin{equation}\Vert\boldsymbol{x}\boldsymbol{W}\Vert_2\leq \Vert\boldsymbol{x}\Vert_2 \Vert\boldsymbol{W}\Vert_2\label{neq:spec-2}\end{equation}
13
Mar
初探MuP:超参数的跨模型尺度迁移规律
By 苏剑林 | 2025-03-13 | 40269位读者 | 引用众所周知,完整训练一次大型LLM的成本是昂贵的,这就决定了我们不可能直接在大型LLM上反复测试超参数。一个很自然的想法是希望可以在同结构的小模型上仔细搜索超参数,找到最优组合后直接迁移到大模型上。尽管这个想法很朴素,但要实现它并不平凡,它需要我们了解常见的超参数与模型尺度之间的缩放规律,而MuP正是这个想法的一个实践。
MuP,有时也写$\mu P$,全名是Maximal Update Parametrization,出自论文《Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer》,随着LLM训练的普及,它逐渐已经成为了科学炼丹的事实标配之一。
方法大意
在接入主题之前,必须先吐槽一下MuP原论文写得实在太过晦涩,并且结论的表达也不够清晰,平白增加了不少理解难度,所以接下来笔者尽量以一种(自认为)简明扼要的方式来复现MuP的结论。
27
Feb
Muon续集:为什么我们选择尝试Muon?
By 苏剑林 | 2025-02-27 | 90568位读者 | 引用本文解读一下我们最新的技术报告《Muon is Scalable for LLM Training》,里边分享了我们之前在《Muon优化器赏析:从向量到矩阵的本质跨越》介绍过的Muon优化器的一次较大规模的实践,并开源了相应的模型(我们称之为“Moonlight”,目前是一个3B/16B的MoE模型)。我们发现了一个比较惊人的结论:在我们的实验设置下,Muon相比Adam能够达到将近2倍的训练效率。

Muon的Scaling Law及Moonlight的MMLU表现
优化器的工作说多不多,但说少也不少,为什么我们会选择Muon来作为新的尝试方向呢?已经调好超参的Adam优化器,怎么快速切换到Muon上进行尝试呢?模型Scale上去之后,Muon与Adam的性能效果差异如何?接下来将分享我们的思考过程。
2
Jan
为什么梯度裁剪的默认模长是1?
By 苏剑林 | 2025-01-02 | 84208位读者 | 引用我们知道,梯度裁剪(Gradient Clipping)是让模型训练更加平稳的常用技巧。常用的梯度裁剪是根据所有参数的梯度总模长来对梯度进行裁剪,其运算可以表示为
\begin{equation}\text{clip}(\boldsymbol{g},\tau)=\left\{\begin{aligned}&\boldsymbol{g}, &\Vert\boldsymbol{g}\Vert\leq \tau \\
&\frac{\tau}{\Vert\boldsymbol{g}\Vert}\boldsymbol{g},&\Vert\boldsymbol{g}\Vert > \tau
\end{aligned}\right.\end{equation}
这样一来,$\text{clip}(\boldsymbol{g},\tau)$保持跟$\boldsymbol{g}$相同的方向,但模长不超过$\tau$。注意这里的$\Vert\boldsymbol{g}\Vert$是整个模型所有的参数梯度放在一起视为单个向量所算的模长,也就是所谓的Global Gradient Norm。
不知道大家有没有留意到一个细节:不管是数百万参数还是数百亿参数的模型,$\tau$的取值在很多时候都是1。这意味着什么呢?是单纯地复用默认值,还是背后隐含着什么深刻的原理呢?
25
Dec
从谱范数梯度到新式权重衰减的思考
By 苏剑林 | 2024-12-25 | 31648位读者 | 引用在文章《Muon优化器赏析:从向量到矩阵的本质跨越》中,我们介绍了一个名为“Muon”的新优化器,其中一个理解视角是作为谱范数正则下的最速梯度下降,这似乎揭示了矩阵参数的更本质的优化方向。众所周知,对于矩阵参数我们经常也会加权重衰减(Weight Decay),它可以理解为$F$范数平方的梯度,那么从Muon的视角看,通过谱范数平方的梯度来构建新的权重衰减,会不会能起到更好的效果呢?
那么问题来了,谱范数的梯度或者说导数长啥样呢?用它来设计的新权重衰减又是什么样的?接下来我们围绕这些问题展开。
基础回顾
谱范数(Spectral Norm),又称“$2$范数”,是最常用的矩阵范数之一,相比更简单的$F$范数(Frobenius Norm),它往往能揭示一些与矩阵乘法相关的更本质的信号,这是因为它定义上就跟矩阵乘法相关:对于矩阵参数$\boldsymbol{W}\in\mathbb{R}^{n\times m}$,它的谱范数定义为
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 125200位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
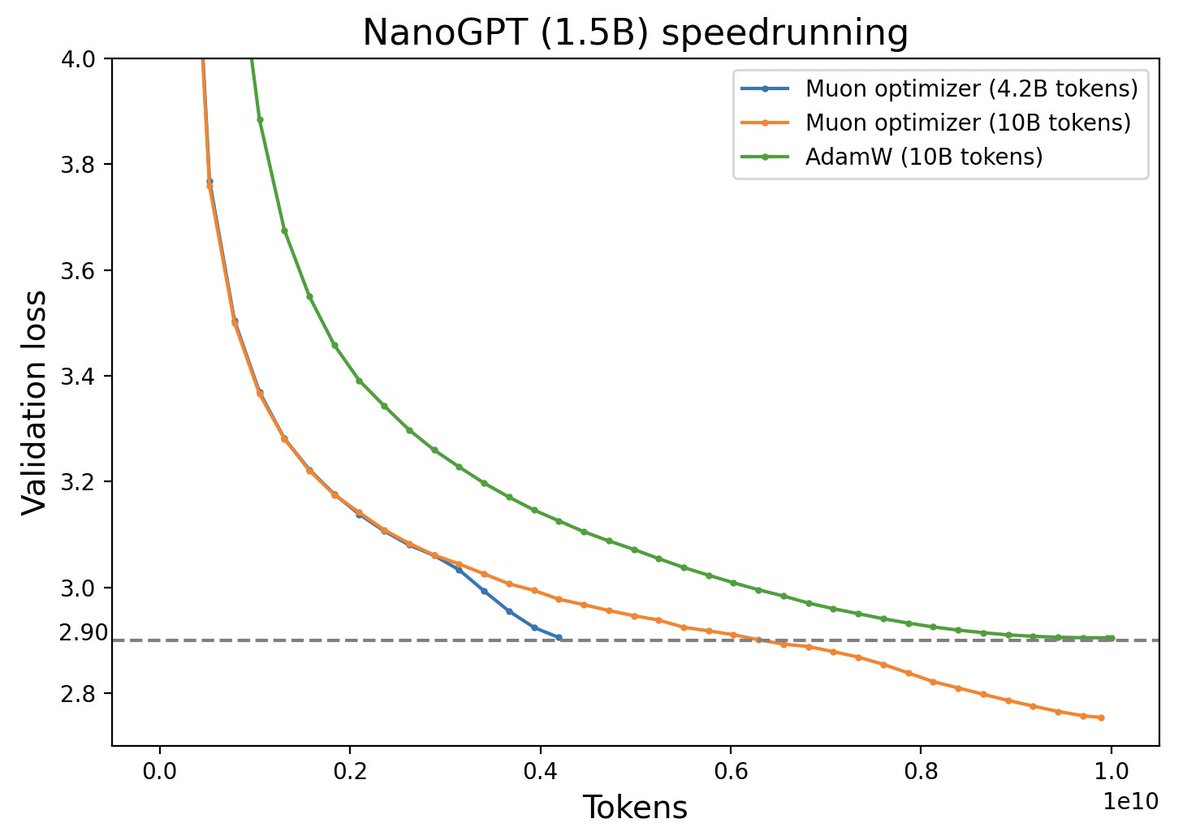
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)

最近评论