






6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 56252位读者 | 引用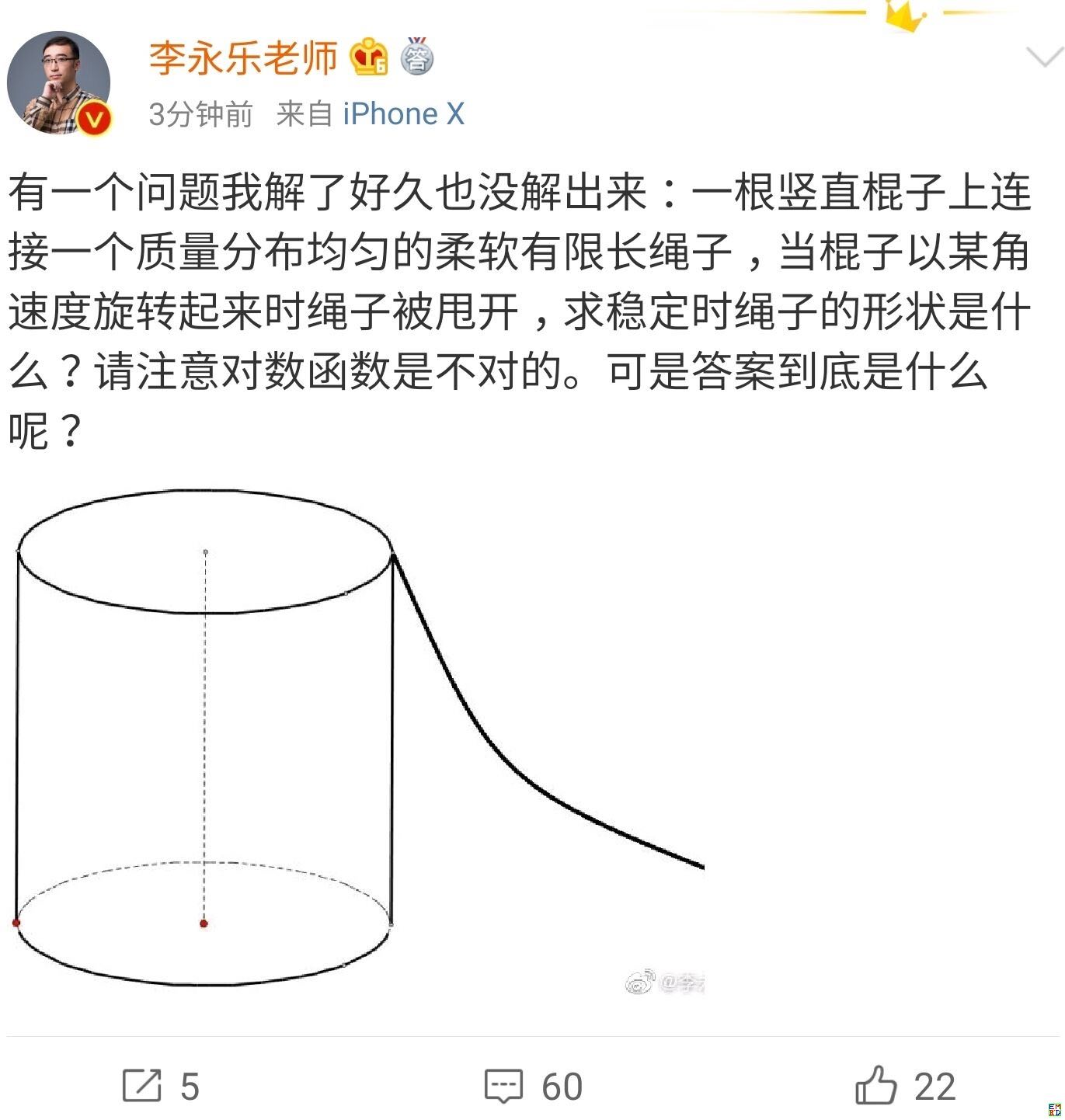

22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 103258位读者 | 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~
14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 39861位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于−log0+=∞),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。
28
Jan
三个球的交点坐标(三球交会定位)
By 苏剑林 | 2025-01-28 | 19411位读者 | 引用前几天笔者在思考一个问题时,联想到了三球交点问题,即给定三个球的球心坐标和半径,求这三个球的交点坐标。按理说这是一个定义清晰且简明的问题,并且具有鲜明的应用背景(比如卫星定位),应该早已有人给出“标准答案”才对。但笔者搜了一圈,发现不管是英文资料还是中文资料,都没有找到标准的求解流程。
当然,这并不是说这个问题有多难以至于没人能求解出来,事实上这是个早已被人解决的经典问题,笔者只是意外于似乎没有人以一种可读性比较好的方式将求解过程写到网上,所以本文试图补充这一点。
特殊情形
首先,设三个球的方程分别是
\begin{align}
&\text{球1:}\quad (\boldsymbol{x} - \boldsymbol{o}_1)^2 = r_1^2 \label{eq:s1} \\
&\text{球2:}\quad (\boldsymbol{x} - \boldsymbol{o}_2)^2 = r_2^2 \label{eq:s2} \\
&\text{球3:}\quad (\boldsymbol{x} - \boldsymbol{o}_3)^2 = r_3^2 \label{eq:s3} \\
\end{align}
20
Aug


最近评论