






26
Sep
利用“熄火保护 + 通断器”实现燃气灶智能关火
By 苏剑林 | 2024-09-26 | 19806位读者 | 引用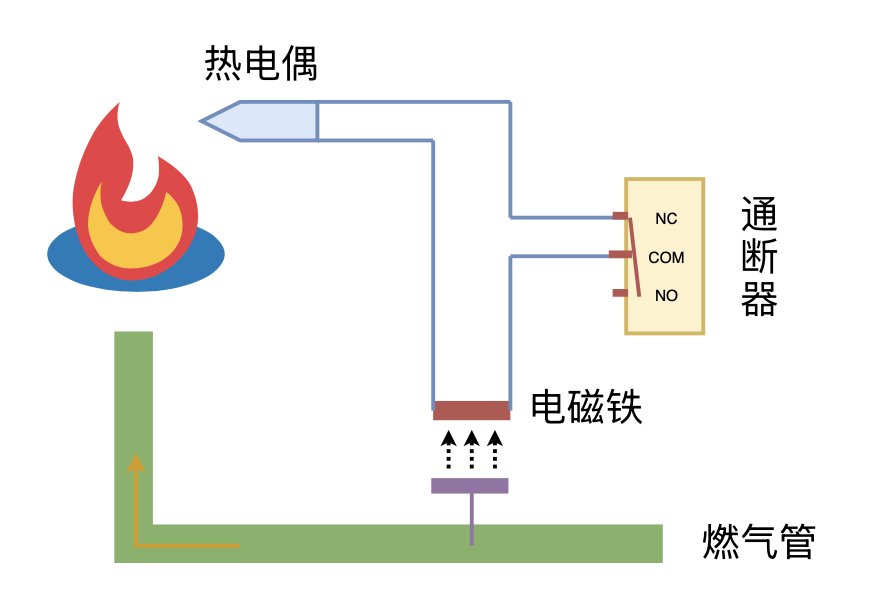
15
Oct
让MathJax的数学公式随窗口大小自动缩放
By 苏剑林 | 2024-10-15 | 18255位读者 | 引用随着MathJax的出现和流行,在网页上显示数学公式便逐渐有了标准答案。然而,MathJax(包括其竞品KaTeX)只是负责将网页LaTeX代码转化为数学公式,对于自适应分辨率方面依然没有太好的办法。像本站一些数学文章,因为是在PC端排版好的,所以在PC端浏览效果尚可,但转到手机上看就可能有点难以入目了。
经过测试,笔者得到了一个方案,让MathJax的数学公式也能像图片一样,随着窗口大小而自适应缩放,从而尽量保证移动端的显示效果,在此跟大家分享一波。
背景思路
这个问题的起源是,即便在PC端进行排版,有时候也会遇到一些单行公式的长度超出了网页宽度,但又不大好换行的情况,这时候一个解决方案是用HTML代码手动调整一下公式的字体大小,比如
<span style="font-size:90%">
\begin{equation}一个超长的数学公式\end{equation}
</span>
15
Dec
生成扩散模型漫谈(二十七):将步长作为条件输入
By 苏剑林 | 2024-12-15 | 28247位读者 | 引用这篇文章我们再次聚焦于扩散模型的采样加速。众所周知,扩散模型的采样加速主要有两种思路,一是开发更高效的求解器,二是事后蒸馏。然而,据笔者观察,除了上两篇文章介绍过的SiD外,这两种方案都鲜有能将生成步数降低到一步的结果。虽然SiD能做到单步生成,但它需要额外的蒸馏成本,并且蒸馏过程中用到了类似GAN的交替训练过程,总让人感觉差点意思。
本文要介绍的是《One Step Diffusion via Shortcut Models》,其突破性思想是将生成步长也作为扩散模型的条件输入,然后往训练目标中加入了一个直观的正则项,这样就能直接稳定训练出可以单步生成模型,可谓简单有效的经典之作。
ODE扩散
原论文的结论是基于ODE式扩散模型的,而对于ODE式扩散的理论基础,我们在本系列的(六)、(十二)、(十四)、(十五)、(十七)等博客中已经多次介绍,其中最简单的一种理解方式大概是(十七)中的ReFlow视角,下面我们简单重复一下。
18
Dec
生成扩散模型漫谈(二十八):分步理解一致性模型
By 苏剑林 | 2024-12-18 | 28166位读者 | 引用书接上文,在《生成扩散模型漫谈(二十七):将步长作为条件输入》中,我们介绍了加速采样的Shortcut模型,其对比的模型之一就是“一致性模型(Consistency Models)”。事实上,早在《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》介绍ReFlow时,就有读者提到了一致性模型,但笔者总感觉它更像是实践上的Trick,理论方面略显单薄,所以兴趣寥寥。
不过,既然我们开始关注扩散模型加速采样方面的进展,那么一致性模型就是一个绕不开的工作。因此,趁着这个机会,笔者在这里分享一下自己对一致性模型的理解。
熟悉配方
还是熟悉的配方,我们的出发点依旧是ReFlow,因为它大概是ODE式扩散最简单的理解方式。设\boldsymbol{x}_0\sim p_0(\boldsymbol{x}_0)是目标分布的真实样本,\boldsymbol{x}_1\sim p_1(\boldsymbol{x}_1)是先验分布的随机噪声,\boldsymbol{x}_t = (1-t)\boldsymbol{x}_0 + t\boldsymbol{x}_1是加噪样本,那么ReFlow的训练目标是:
14
Feb
生成扩散模型漫谈(二十九):用DDPM来离散编码
By 苏剑林 | 2025-02-14 | 21507位读者 | 引用笔者前两天在arXiv刷到了一篇新论文《Compressed Image Generation with Denoising Diffusion Codebook Models》,实在为作者的天马行空所叹服,忍不住来跟大家分享一番。
如本文标题所述,作者提出了一个叫DDCM(Denoising Diffusion Codebook Models)的脑洞,它把DDPM的噪声采样限制在一个有限的集合上,然后就可以实现一些很奇妙的效果,比如像VQVAE一样将样本编码为离散的ID序列并重构回来。注意这些操作都是在预训练好的DDPM上进行的,无需额外的训练。
有限集合
由于DDCM只需要用到一个预训练好的DDPM模型来执行采样,所以这里我们就不重复介绍DDPM的模型细节了,对DDPM还不大了解的读者可以回顾我们《生成扩散模型漫谈》系列的(一)、(二)、(三)篇。
21
Feb
MoE环游记:2、不患寡而患不均
By 苏剑林 | 2025-02-21 | 22237位读者 | 引用在上一篇文章《MoE环游记:1、从几何意义出发》中,我们介绍了MoE的一个几何诠释,旨在通过Dense模型的最佳逼近出发来推导和理解MoE。同时在文末我们也说了,给出MoE的计算公式仅仅是开始,训练一个实际有效的MoE模型还有很多细节补,比如本文要讨论的负载均衡(Load Balance)问题。
负载均衡,即“不患寡而患不均”,说白了就是让每个Expert都在干活,并且都在干尽可能一样多的活,避免某些Expert浪费算力。负载均衡既是充分利用训练算力的需求,也是尽可能发挥MoE大参数量潜力的需求。
需求分析
我们知道,MoE的基本形式是
\begin{equation}\boldsymbol{y} = \sum_{i\in \mathop{\text{argtop}}_k \boldsymbol{\rho}} \rho_i \boldsymbol{e}_i\end{equation}
27
Feb
Muon续集:为什么我们选择尝试Muon?
By 苏剑林 | 2025-02-27 | 18679位读者 | 引用本文解读一下我们最新的技术报告《Muon is Scalable for LLM Training》,里边分享了我们之前在《Muon优化器赏析:从向量到矩阵的本质跨越》介绍过的Muon优化器的一次较大规模的实践,并开源了相应的模型(我们称之为“Moonlight”,目前是一个3B/16B的MoE模型)。我们发现了一个比较惊人的结论:在我们的实验设置下,Muon相比Adam能够达到将近2倍的训练效率。

Muon的Scaling Law及Moonlight的MMLU表现
优化器的工作说多不多,但说少也不少,为什么我们会选择Muon来作为新的尝试方向呢?已经调好超参的Adam优化器,怎么快速切换到Muon上进行尝试呢?模型Scale上去之后,Muon与Adam的性能效果差异如何?接下来将分享我们的思考过程。
13
Mar
初探muP:超参数的跨模型尺度迁移规律
By 苏剑林 | 2025-03-13 | 10919位读者 | 引用众所周知,完整训练一次大型LLM的成本是昂贵的,这就决定了我们不可能直接在大型LLM上反复测试超参数。一个很自然的想法是希望可以在同结构的小模型上仔细搜索超参数,找到最优组合后直接迁移到大模型上。尽管这个想法很朴素,但要实现它并不平凡,它需要我们了解常见的超参数与模型尺度之间的缩放规律,而muP正是这个想法的一个实践。
muP,有时也写\mu P,全名是Maximal Update Parametrization,出自论文《Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer》,随着LLM训练的普及,它逐渐已经成为了科学炼丹的事实标配之一。
方法大意
在接入主题之前,必须先吐槽一下muP原论文写得实在太过晦涩,并且结论的表达也不够清晰,平白增加了不少理解难度,所以接下来笔者尽量以一种(自认为)简明扼要的方式来复现muP的结论。

最近评论