






25
May
从重参数的角度看离散概率分布的构建
By 苏剑林 | 2022-05-25 | 19052位读者 | 引用一般来说,神经网络的输出都是无约束的,也就是值域为R,而为了得到有约束的输出,通常是采用加激活函数的方式。例如,如果我们想要输出一个概率分布来代表每个类别的概率,那么通常在最后加上Softmax作为激活函数。那么一个紧接着的疑问就是:除了Softmax,还有什么别的操作能生成一个概率分布吗?
在《漫谈重参数:从正态分布到Gumbel Softmax》中,我们介绍了Softmax的重参数操作,本文将这个过程反过来,即先定义重参数操作,然后去反推对应的概率分布,从而得到一个理解概率分布构建的新视角。
问题定义
假设模型的输出向量为\boldsymbol{\mu}=[\mu_1,\cdots,\mu_n]\in\mathbb{R}^n,不失一般性,这里假设\mu_i两两不等。我们希望通过某个变换\mathcal{T}将\boldsymbol{\mu}转换为n元概率分布\boldsymbol{p}=[p_1,\cdots,p_n],并保持一定的性质。比如,最基本的要求是:
\begin{equation}{\color{red}1.}\,p_i\geq 0 \qquad {\color{red}2.}\,\sum_i p_i = 1 \qquad {\color{red}3.}\,p_i \geq p_j \Leftrightarrow \mu_i \geq \mu_j\end{equation}
26
Oct
浅谈神经网络中激活函数的设计
By 苏剑林 | 2017-10-26 | 51497位读者 | 引用激活函数是神经网络中非线性的来源,因为如果去掉这些函数,那么整个网络就只剩下线性运算,线性运算的复合还是线性运算的,最终的效果只相当于单层的线性模型。
那么,常见的激活函数有哪些呢?或者说,激活函数的选择有哪些指导原则呢?是不是任意的非线性函数都可以做激活函数呢?
这里探究的激活函数是中间层的激活函数,而不是输出的激活函数。最后的输出一般会有特定的激活函数,不能随意改变,比如二分类一般用sigmoid函数激活,多分类一般用softmax激活,等等;相比之下,中间层的激活函数选择余地更大一些。
浮点误差都行!
理论上来说,只要是非线性函数,都有做激活函数的可能性,一个很有说服力的例子是,最近OpenAI成功地利用了浮点误差来做激活函数,其中的细节,请阅读OpenAI的博客:
https://blog.openai.com/nonlinear-computation-in-linear-networks/
或者阅读机器之心的介绍:
https://mp.weixin.qq.com/s/PBRzS4Ol_Zst35XKrEpxdw
20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 139474位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到\text{argmax}等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是\max操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 86579位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 121658位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在\mathbb{R}^n上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 24927位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。
26
Mar
GELU的两个初等函数近似是怎么来的
By 苏剑林 | 2020-03-26 | 61720位读者 | 引用GELU,全称为Gaussian Error Linear Unit,也算是RELU的变种,是一个非初等函数形式的激活函数。它由论文《Gaussian Error Linear Units (GELUs)》提出,后来被用到了GPT中,再后来被用在了BERT中,再再后来的不少预训练语言模型也跟着用到了它。随着BERT等预训练语言模型的兴起,GELU也跟着水涨船高,莫名其妙地就成了热门的激活函数了。
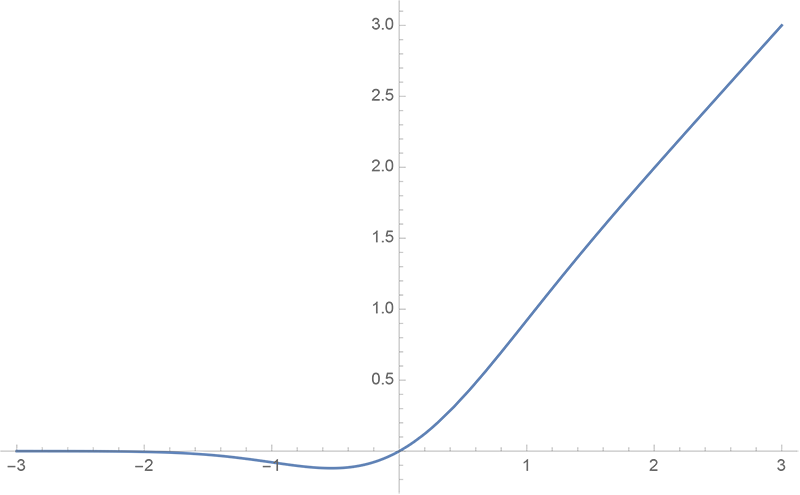
gelu函数图像
在GELU的原始论文中,作者不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式,本文来讨论它们是怎么得到的。
10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 267045位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现(f(z)对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于z的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号z换成y或者c。

最近评论