






17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 24893位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。
11
Aug
细水长flow之NICE:流模型的基本概念与实现
By 苏剑林 | 2018-08-11 | 253224位读者 | 引用前言:自从在机器之心上看到了glow模型之后(请看《下一个GAN?OpenAI提出可逆生成模型Glow》),我就一直对其念念不忘。现在机器学习模型层出不穷,我也经常关注一些新模型动态,但很少像glow模型那样让我怦然心动,有种“就是它了”的感觉。更意外的是,这个效果看起来如此好的模型,居然是我以前完全没有听说过的。于是我翻来覆去阅读了好几天,越读越觉得有意思,感觉通过它能将我之前的很多想法都关联起来。在此,先来个阶段总结。
背景
本文主要是《NICE: Non-linear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。
艰难的分布
众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。

glow模型生成的高清人脸
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 289613位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
29
Sep
f-GAN简介:GAN模型的生产车间
By 苏剑林 | 2018-09-29 | 142237位读者 | 引用今天介绍一篇比较经典的工作,作者命名为f-GAN,他在文章中给出了通过一般的$f$散度来构造一般的GAN的方案。可以毫不夸张地说,这论文就是一个GAN模型的“生产车间”,它一般化的囊括了很多GAN变种,并且可以启发我们快速地构建新的GAN变种(当然有没有价值是另一回事,但理论上是这样)。
局部变分
整篇文章对$f$散度的处理事实上在机器学习中被称为“局部变分方法”,它是一种非常经典且有用的估算技巧。事实上本文将会花大部分篇幅介绍这种估算技巧在$f$散度中的应用结果。至于GAN,只不过是这个结果的基本应用而已。
f散度
首先我们还是对$f$散度进行基本的介绍。所谓$f$散度,是KL散度的一般化:
$$\begin{equation}\mathcal{D}_f(P\Vert Q) = \int q(x) f\left(\frac{p(x)}{q(x)}\right)dx\label{eq:f-div}\end{equation}$$
注意,按照通用的约定写法,括号内是$p/q$而不是$q/p$,大家不要自然而言地根据KL散度的形式以为是$q/p$。
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 123409位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
30
Jan
能量视角下的GAN模型(一):GAN=“挖坑”+“跳坑”
By 苏剑林 | 2019-01-30 | 87397位读者 | 引用
“看那挖坑的人,有啥不一样~”
在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
本视角直接受启发于Benjio团队的新作《Maximum Entropy Generators for Energy-Based Models》,这篇文章前几天出现在arxiv上。当然,能量模型与GAN的联系由来已久,并不是这篇文章的独创,只不过这篇文章做得仔细和完善一些。另外本文还补充了自己的一些理解和思考上去,力求更为易懂和完整。
作为第一篇文章,我们先来给出一个直白的类比推导:GAN实际上就是一场前仆后继(前挖后跳?)的“挖坑”与“跳坑”之旅~
总的来说,本文的大致内容如下:
1、给出了GAN/WGAN的清晰直观的能量图像;
2、讨论了判别器(能量函数)的训练情况和策略;
3、指出了梯度惩罚一个非常漂亮而直观的能量解释;
4、讨论了GAN中优化器的选择问题。
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 75692位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 305308位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
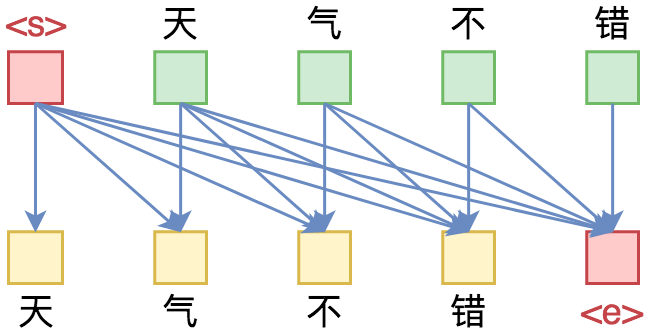
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。

最近评论