






23
Jan
【龟猫记】家里多了几只小动物
By 苏剑林 | 2010-01-23 | 19790位读者 | 引用
21
Mar
地球“黑暗”的一小时
By 苏剑林 | 2010-03-21 | 30073位读者 | 引用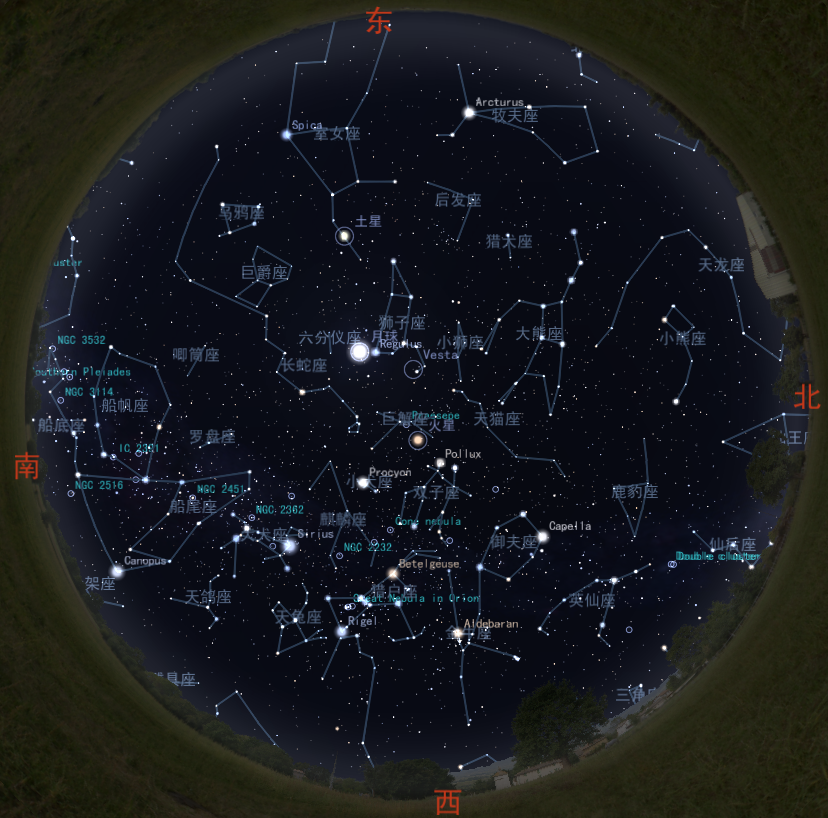
1
May
我们打算飞到小行星上——但是,哪一颗好呢?
By 苏剑林 | 2010-05-01 | 37138位读者 | 引用
漫游在太空的小行星
站长:已经很久没有翻译过科普文章了。现在再来尝试一下,依旧是“Google+金山+搜索+理解”的模式,依旧是那么烂的水平,依旧是那么差的文采,呵呵。有任何意见欢迎提出。 4月15日,美国总统巴拉克·奥巴马视察了位于佛罗里达州的肯尼迪航天中心并发表演讲,提出美国航天新计划:美国未来航天的目的地是火星和小行星,终止布什政府提出的国家载人航天飞行项目。他强有力地回击了其政策的批评者,同时呼吁私营企业铺设飞往火星的创新之路,而不是以国家之力展示美国的优势。 众所周知,载人登小行星比载人登月难多了。除了苛刻的技术条件外,适合登录的小行星也不多,奥巴马的新方案真的可行吗?让我们拭目以待!
8
Jul
一道比较函数大小的题目
By 苏剑林 | 2011-07-08 | 22722位读者 | 引用
18
Mar
指数函数及其展开式孰大孰小?
By 苏剑林 | 2012-03-18 | 31445位读者 | 引用
25
Dec
矩阵化简二次型(无穷小近似处理抛物型)
By 苏剑林 | 2012-12-25 | 26890位读者 | 引用(阅读本文最好有一定的线性代数基础,至少对线性代数里边的基本概念有所了解。)
这学期已经接近尾声了,我们的《解析几何》已经讲到化简二次曲线了。可是,对于没有线性代数的其他同学们,直接用转轴和移轴这个计算公式来变换,那计算量会让我们很崩溃的;虽然那个“不变量”方法计算上有些简单,却总让人感到很诡异,总觉得不知从何而来,而且又要记一堆公式。事实上,如果有线性代数的基础,这些东西变得相当好理解的。我追求用统一的方法求解同一种问题,即用统一的方式处理所有的二次型,当然也希望计算量简单一点。
一般的模型
一般的二次型可以写成
xTAx+2bTx+c=0
其中x,b都是n维列向量(各元素为xi和bi),A是n阶方阵(各元素为aij),c是常数。在这里,我们只讨论n=2和n=3的情况。化简二次型的过程,可以归结为A矩阵的简化。
本文我们来探讨下列积分的极值曲线:
S=∫f(x,y)√dx2+dy2=∫f(x,y)ds
这本质上也是一个短程线问题。但是它形式比较简答,物理含义也更加明显。比如,如果f(x,y)是势函数的话,那么这就是一个求势能最小的二维问题;如果f(x,y)是摩擦力函数,那么这就是寻找摩擦力最小的路径问题。不管是哪一种,该问题都有相当的实用价值。下面将其变分:
δS=∫δ[f(x,y)√dx2+dy2]=∫[dsδf(x,y)+f(x,y)δ(dx2+dy2)2ds]=∫ds(∂f∂xδx+∂∂yδy)+fdxd(δx)+dyd(δy)ds=∫ds(∂f∂xδx+∂∂yδy)+fdxdsd(δx)+dydsd(δy)

最近评论