






27
Mar
海伦公式的一个别致的物理推导
By 苏剑林 | 2015-03-27 | 55729位读者 | 引用海伦公式是已知三角形三边的长度a,b,c来求面积S的公式,是一个相当漂亮的公式,它不算复杂,同时它关于a,b,c是对称的,充分体现了三边的同等地位。可是,这样具有对称美的公式推导,往往要经过一个不对称的过程,比如维基百科上的证明,这未免有点美中不足。本文的目的,就是想为此补充一个对称的推导。本文题目为“物理推导”,关键在于“推导”而不是“证明”,同时这里的“物理”并非是通过物理类比而来,而是推导的思想和方法很具有“物理味道”。
√p(p−a)(p−b)(p−c)
在推导开始之前,笔者给出一个评论:海伦公式似乎是由三边长求三角形面积的所有可能的公式之中最简单的一个。
5
Oct
2015诺贝尔医学奖:中国人在内
By 苏剑林 | 2015-10-05 | 25666位读者 | 引用
3
Aug
运动相机测试:家乡的星空
By 苏剑林 | 2016-08-03 | 40859位读者 | 引用记得很早之前就想尝试一下拍星空,无奈一直都没有设备。以前只知道单反可以拍星空,因此,一直以来的想法就是有钱了就去买台单反。因为各种原因一拖再拖,最后慢慢觉得,对于我这种三分钟热度的人来说,单反的意义还真的不是很大。
这两年,在小米的鼓吹下,小蚁运动相机在国内算是慢慢掀起了一股运动相机潮。这种相机的特点是小巧、灵活,价格也不贵(相比单反)。灵活不仅仅是说它便于携带,而且还是功能上的灵活,比如一代小蚁还支持编程拍摄!(写程序控制快门、ISO、拍摄间隔,并实现定时拍摄等)这样当然很快就吸引了我,在小蚁2代众筹之时,我也咬咬牙,入了一台。
前两天回到家,刚好晴夜,马上就试了一下拍星空的效果。下面是在我家楼顶拍的,用ISO400曝光30秒的效果:

家乡的星空
20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 34745位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
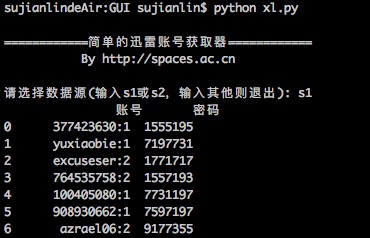
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 44412位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
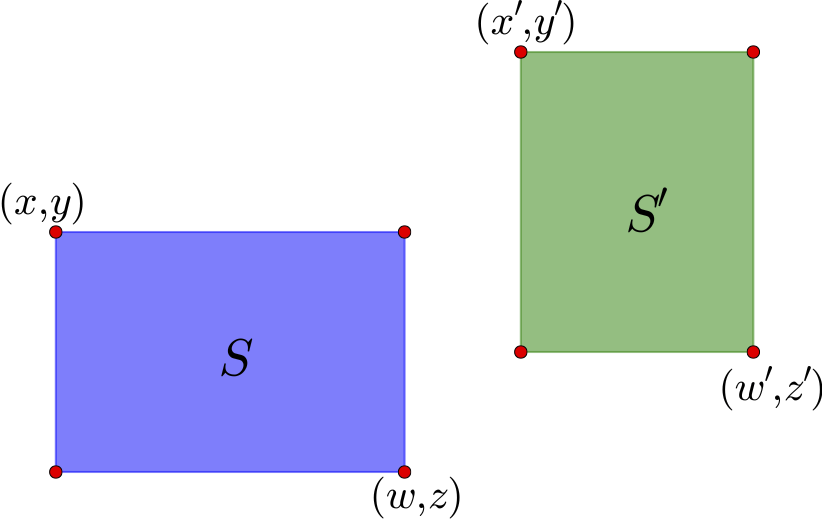
图14 两个示例区域
如上图,通过左上角坐标(x,y)和右下角坐标(z,w)就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是(x+w2,y+z2). 对于图中的两个区域S和S′,可以计算它们的中心向量差
(xc,yc)=(x′+w′2−x+w2,y′+z′2−y+z2)
如果直接使用√x2c+y2c作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
(x′c,y′c)=(xc−w−x2−w′−x′2,yc−z−y2−z′−y′2)
距离定义为
d(S,S′)=[max
至于方向,由(x_c,y_c)的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域
24
Jun
OCR技术浅探:5. 文本切割
By 苏剑林 | 2016-06-24 | 50330位读者 | 引用

14
Mar
泰迪杯赛前培训之数据挖掘与建模“慢谈”
By 苏剑林 | 2017-03-14 | 34706位读者 | 引用
泰迪杯赛前培训
应广州泰迪科技公司之邀,给泰迪杯数据挖掘竞赛录制了赛前培训视频,内容基本上是各种常见的数学模型及入门用法,以一种比较独特的思路,将朴素贝叶斯、HMM、逻辑回归、组合模型、神经网络、深度学习等等串了起来。视频讲解难度为入门级,当然,真的要融合贯通所有内容,恐怕要骨灰级。
不管怎么样,简单分享一下,欢迎大家留言讨论、建议甚至批评。
PPT下载:泰迪杯赛前培训ppt.zip
24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 99122位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。

最近评论