






6
Oct
中国香港“光纤之父”获2009诺贝尔物理学奖!
By 苏剑林 | 2009-10-06 | 32294位读者 | 引用中国网10月6日电,据诺贝尔基金会官方网站报道,瑞典皇家科学院诺贝尔奖委员会宣布,将2009年度诺贝尔物理学奖授予一名中国香港科学家高琨(Charles K. Kao)和两名美国科学家博伊尔(Willard S. Boyle)和乔治-E-史密斯(George E. Smith)。科学家Charles K. Kao 因为“在光学通信领域中光的传输的开创性成就” 而获奖,科学家因博伊尔和乔治-E-史密斯因“发明了成像半导体电路——电荷藕合器件图像传感器CCD” 获此殊荣。

2009年诺贝尔物理学奖获得者高锟、博伊尔和史密斯(从左至右)
2009年诺贝尔物理学奖获得者高锟、博伊尔和史密斯(从左至右)
8
Oct
《哈勃太空望远镜超高清原始片源》VeryCD资源
By 苏剑林 | 2009-10-08 | 35568位读者 | 引用
8
Oct
【NASA每日一图】撞击目标:凯布斯月球坑
By 苏剑林 | 2009-10-08 | 19359位读者 | 引用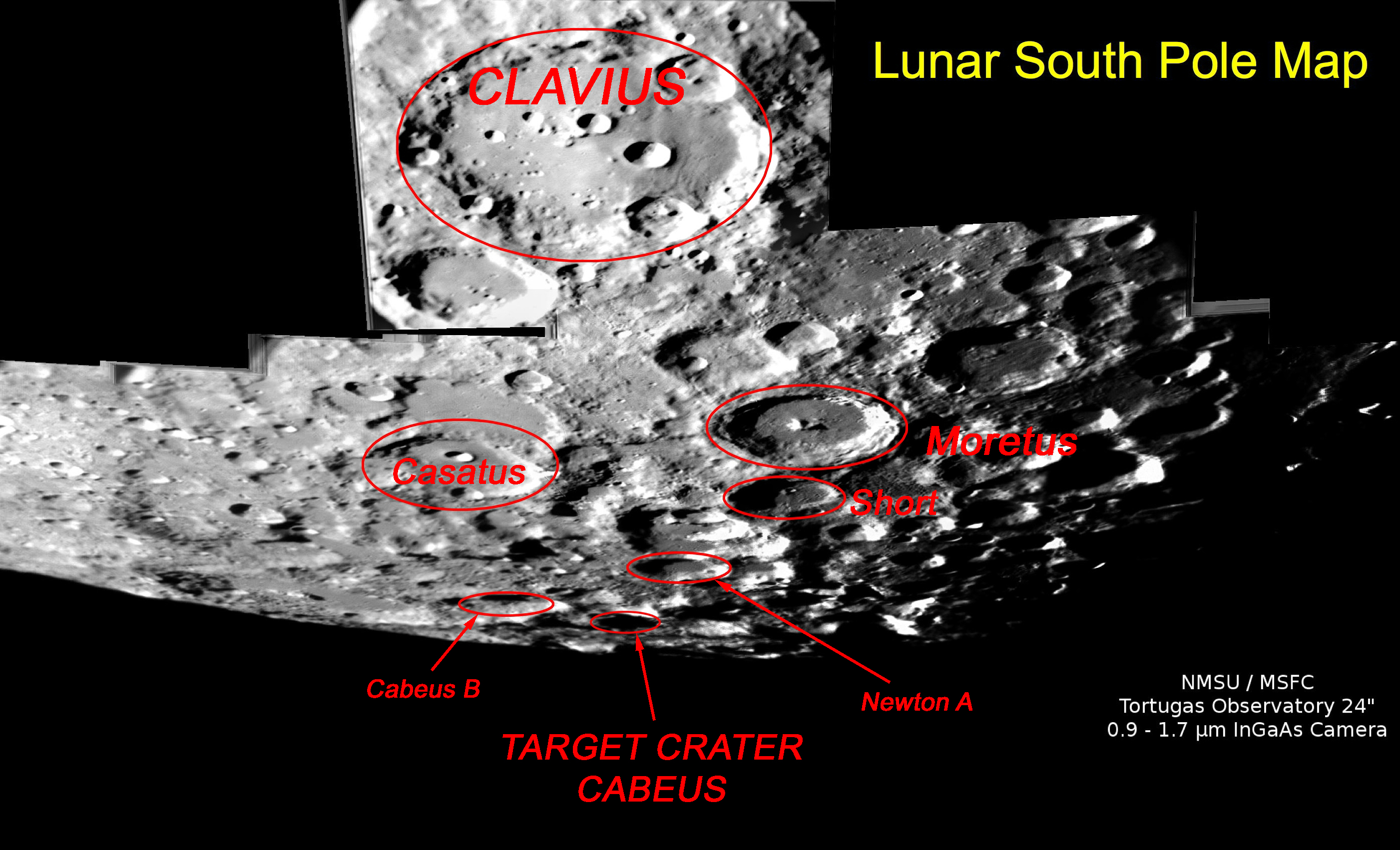
13
Oct
两名美国经济学家同获2009年诺贝尔经济学奖
By 苏剑林 | 2009-10-13 | 18434位读者 | 引用
31
Oct
沉痛,默哀!中国科学巨星钱学森逝世
By 苏剑林 | 2009-10-31 | 25232位读者 | 引用
1
Nov
本站域名Spaces.Ac.Cn的PR为2了
By 苏剑林 | 2009-11-01 | 26316位读者 | 引用
30
Oct


最近评论