






4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 140905位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的O(n2)复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
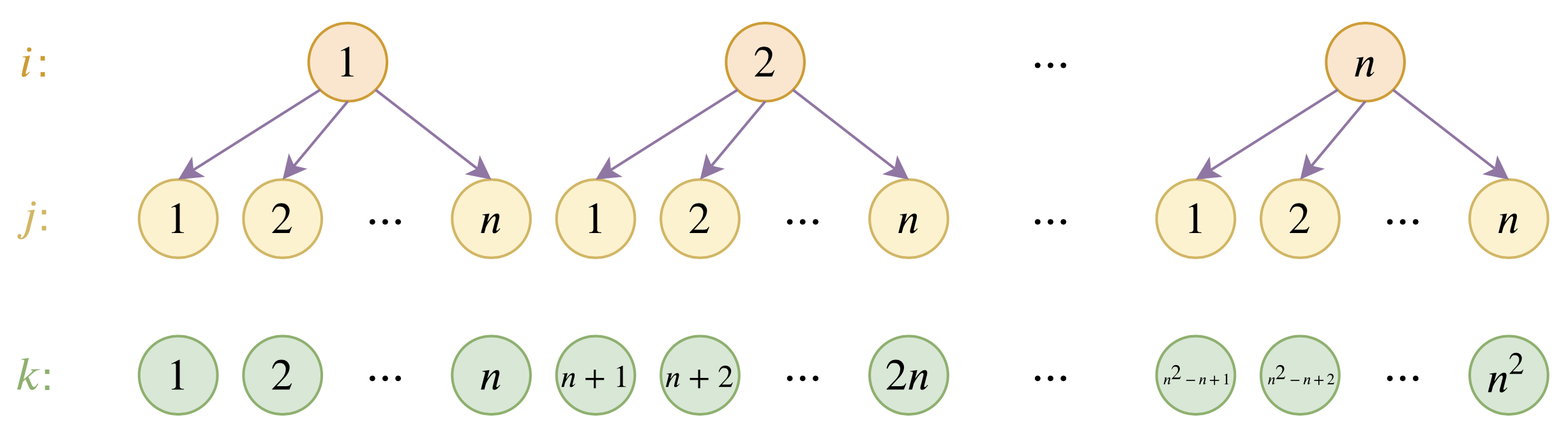
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。
3
Feb
让研究人员绞尽脑汁的Transformer位置编码
By 苏剑林 | 2021-02-03 | 240343位读者 | 引用不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:1、想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;2、想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第k个向量\boldsymbol{x}_k中加入位置向量\boldsymbol{p}_k变为\boldsymbol{x}_k + \boldsymbol{p}_k,其中\boldsymbol{p}_k只依赖于位置编号k。
8
Mar
Transformer升级之路:1、Sinusoidal位置编码追根溯源
By 苏剑林 | 2021-03-08 | 172038位读者 | 引用最近笔者做了一些理解和改进Transformer的尝试,得到了一些似乎还有价值的经验和结论,遂开一个专题总结一下,命名为“Transformer升级之路”,既代表理解上的深入,也代表结果上的改进。
作为该专题的第一篇文章,笔者将会介绍自己对Google在《Attention is All You Need》中提出来的Sinusoidal位置编码
\begin{equation}\left\{\begin{aligned}&\boldsymbol{p}_{k,2i}=\sin\Big(k/10000^{2i/d}\Big)\\
&\boldsymbol{p}_{k, 2i+1}=\cos\Big(k/10000^{2i/d}\Big)
\end{aligned}\right.\label{eq:sin}\end{equation}
的新理解,其中\boldsymbol{p}_{k,2i},\boldsymbol{p}_{k,2i+1}分别是位置k的编码向量的第2i,2i+1个分量,d是向量维度。
作为位置编码的一个显式解,Google在原论文中对它的描述却寥寥无几,只是简单提及了它可以表达相对位置信息,后来知乎等平台上也出现了一些解读,它的一些特点也逐步为大家所知,但总体而言比较零散。特别是对于“它是怎么想出来的”、“非得要这个形式不可吗”等原理性问题,还没有比较好的答案。
因此,本文主要围绕这些问题展开思考,可能在思考过程中读者会有跟笔者一样的感觉,即越思考越觉得这个设计之精妙漂亮,让人叹服~
23
Mar
Transformer升级之路:2、博采众长的旋转式位置编码
By 苏剑林 | 2021-03-23 | 373652位读者 | 引用上一篇文章中,我们对原始的Sinusoidal位置编码做了较为详细的推导和理解,总的感觉是Sinusoidal位置编码是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。
本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
10
May
Transformer升级之路:4、二维位置的旋转式位置编码
By 苏剑林 | 2021-05-10 | 130465位读者 | 引用在之前的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中我们提出了旋转式位置编码RoPE以及对应的Transformer模型RoFormer。由于笔者主要研究的领域还是NLP,所以本来这个事情对于笔者来说已经完了。但是最近一段时间,Transformer模型在视觉领域也大火,各种Vision Transformer(ViT)层出不穷,于是就有了问题:二维情形的RoPE应该是怎样的呢?
咋看上去,这个似乎应该只是一维情形的简单推广,但其中涉及到的推导和理解却远比我们想象中复杂,本文就对此做一个分析,从而深化我们对RoPE的理解。
二维RoPE
什么是二维位置?对应的二维RoPE又是怎样的?它的难度在哪里?在这一节中,我们先简单介绍二维位置,然后直接给出二维RoPE的结果和推导思路,在随后的几节中,我们再详细给出推导过程。
7
Jun
相对位置编码Transformer的一个理论缺陷与对策
By 苏剑林 | 2022-06-07 | 106305位读者 | 引用位置编码是Transformer中很重要的一环,在《让研究人员绞尽脑汁的Transformer位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将Transformer的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多NLP/CV的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在Softmax之前的Attention矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得Transformer无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。
简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射 \begin{equation}\begin{array}{lc} \text{输入:} & [0, 0, \cdots, 0, 0] \\ & \downarrow\\ \text{输出:} & [1, 2, \cdots, n-1, n] \end{array}\end{equation}
28
Dec
Transformer升级之路:6、旋转位置编码的完备性分析
By 苏剑林 | 2022-12-28 | 47853位读者 | 引用在去年的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE),当时的出发点只是觉得用绝对位置来实现相对位置是一件“很好玩的事情”,并没料到其实际效果还相当不错,并为大家所接受,不得不说这真是一个意外之喜。后来,在《Transformer升级之路:4、二维位置的旋转式位置编码》中,笔者讨论了二维形式的RoPE,并研究了用矩阵指数表示的RoPE的一般解。
既然有了一般解,那么自然就会引出一个问题:我们常用的RoPE,只是一个以二维旋转矩阵为基本单元的分块对角矩阵,如果换成一般解,理论上效果会不会更好呢?本文就来回答这个问题。
指数通解
在《Transformer升级之路:4、二维位置的旋转式位置编码》中,我们将RoPE抽象地定义为任意满足下式的方阵
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\label{eq:re}\end{equation}
29
Mar
Transformer升级之路:17、多模态位置编码的简单思考
By 苏剑林 | 2024-03-29 | 80369位读者 | 引用在这个系列的第二篇文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE)——通过绝对位置的形式实现相对位置编码的方案。一开始RoPE是针对一维序列如文本、音频等设计的(RoPE-1D),后来在《Transformer升级之路:4、二维位置的旋转式位置编码》中我们将它推广到了二维序列(RoPE-2D),这适用于图像的ViT。然而,不管是RoPE-1D还是RoPE-2D,它们的共同特点都是单一模态,即纯文本或者纯图像输入场景,那么对于多模态如图文混合输入场景,RoPE该做如何调整呢?
笔者搜了一下,发现鲜有工作讨论这个问题,主流的做法似乎都是直接展平所有输入,然后当作一维输入来应用RoPE-1D,因此连RoPE-2D都很少见。且不说这种做法会不会成为图像分辨率进一步提高时的效果瓶颈,它终究是显得不够优雅。所以,接下来我们试图探寻两者的一个自然结合。
旋转位置
RoPE名称中的“旋转”一词,来源于旋转矩阵\boldsymbol{\mathcal{R}}_n=\begin{pmatrix}\cos n\theta & -\sin n\theta\\ \sin n\theta & \cos n\theta\end{pmatrix},它满足
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\end{equation}

最近评论