






18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 422129位读者 |前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM #
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
换句话说,[CLS] 你 想 吃 啥 [SEP]这几个token之间是双向的Attention,而白 切 鸡 [SEP]这几个token则是单向Attention,从而允许递归地预测白 切 鸡 [SEP]这几个token,所以它具备文本生成能力。
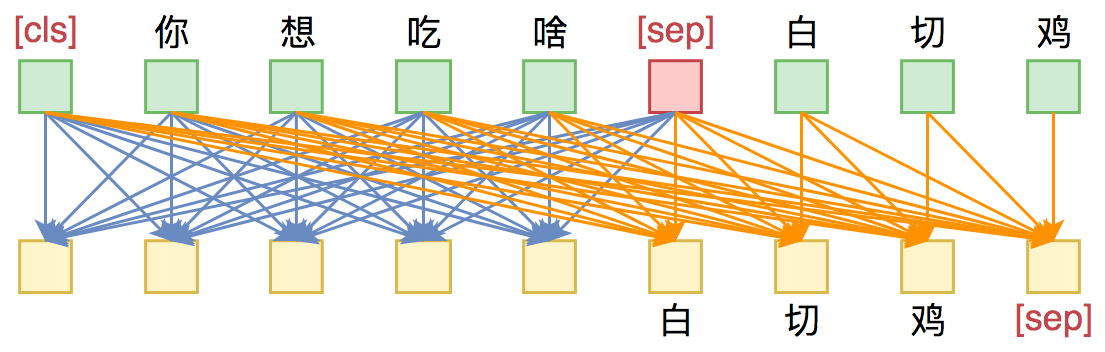
UNILM做Seq2Seq模型图示。输入部分内部可做双向Attention,输出部分只做单向Attention。
Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有[CLS] 你 想 吃 啥 [SEP]时的编码结果,如果[CLS]的向量代表着句向量,那么它就是你 想 吃 啥的句向量,而不是加上白 切 鸡后的句向量。
由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。
SimBERT #
理解了UniLM后,其实就不难理解SimBERT训练方式了。SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图:
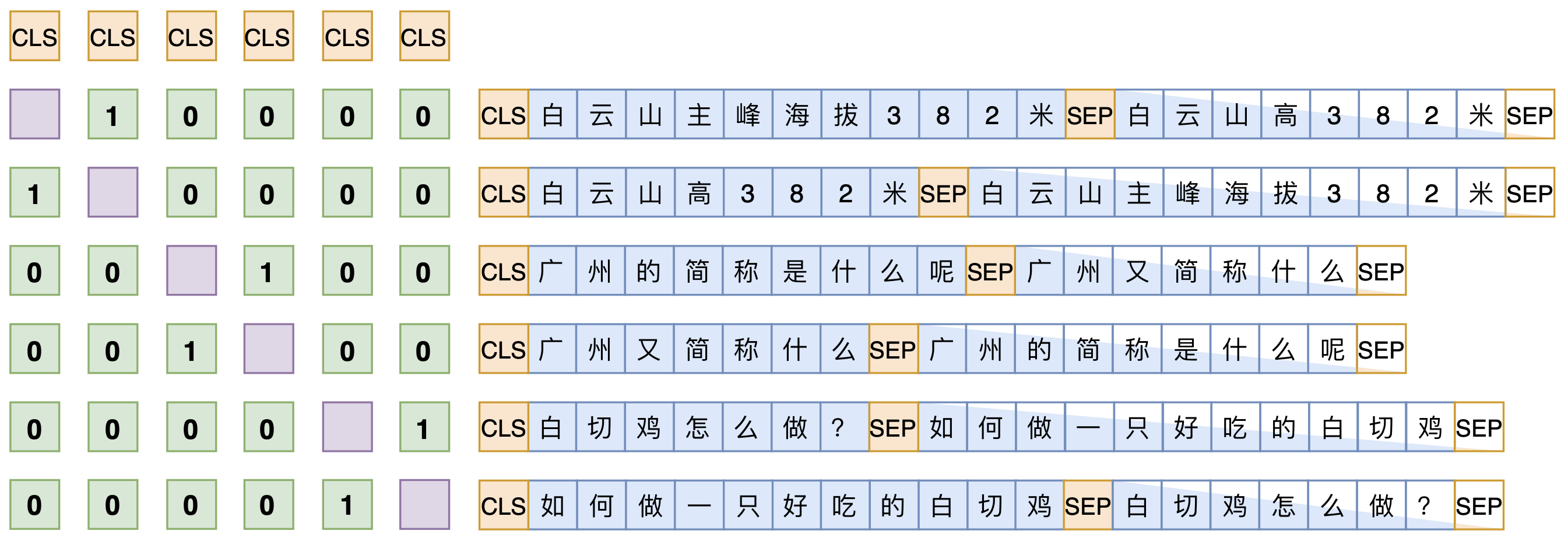
SimBERT训练方式示意图
假设SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
另一方面,把整个batch内的[CLS]向量都拿出来,得到一个句向量矩阵$\boldsymbol{V}\in\mathbb{R}^{b\times d}$($b$是batch_size,$d$是hidden_size),然后对$d$维度做$l_2$归一化,得到$\tilde{\boldsymbol{V}}$,然后两两做内积,得到$b\times b$的相似度矩阵$\tilde{\boldsymbol{V}}\tilde{\boldsymbol{V}}^{\top}$,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
说到底,关键就是“[CLS]的向量事实上就代表着输入的句向量”,所以可以用它来做一些NLU相关的事情。最后的loss是Seq2Seq和相似句分类两部分loss之和。
其他细节 #
由于已经开放源码,所以更多的训练细节大家可以自行阅读源码。模型使用keras + bert4keras实现,代码还是很清晰的,所以很多疑惑应该都可以通过阅读源码解决。
效果演示:
>>> gen_synonyms(u'微信和支付宝哪个好?')
[
u'微信和支付宝,哪个好?',
u'微信和支付宝哪个好',
u'支付宝和微信哪个好',
u'支付宝和微信哪个好啊',
u'微信和支付宝那个好用?',
u'微信和支付宝哪个好用',
u'支付宝和微信那个更好',
u'支付宝和微信哪个好用',
u'微信和支付宝用起来哪个好?',
u'微信和支付宝选哪个好',
u'微信好还是支付宝比较用',
u'微信与支付宝哪个',
u'支付宝和微信哪个好用一点?',
u'支付宝好还是微信',
u'微信支付宝究竟哪个好',
u'支付宝和微信哪个实用性更好',
u'好,支付宝和微信哪个更安全?',
u'微信支付宝哪个好用?有什么区别',
u'微信和支付宝有什么区别?谁比较好用',
u'支付宝和微信哪个好玩'
]
>>> most_similar(u'怎么开初婚未育证明', 20)
[
(u'开初婚未育证明怎么弄?', 0.9728098),
(u'初婚未育情况证明怎么开?', 0.9612292),
(u'到哪里开初婚未育证明?', 0.94987774),
(u'初婚未育证明在哪里开?', 0.9476072),
(u'男方也要开初婚证明吗?', 0.7712214),
(u'初婚证明除了村里开,单位可以开吗?', 0.63224965),
(u'生孩子怎么发', 0.40672967),
(u'是需要您到当地公安局开具变更证明的', 0.39978087),
(u'淘宝开店认证未通过怎么办', 0.39477515),
(u'您好,是需要当地公安局开具的变更证明的', 0.39288986),
(u'没有工作证明,怎么办信用卡', 0.37745982),
(u'未成年小孩还没办身份证怎么买高铁车票', 0.36504325),
(u'烟草证不给办,应该怎么办呢?', 0.35596085),
(u'怎么生孩子', 0.3493368),
(u'怎么开福利彩票站', 0.34158638),
(u'沈阳烟草证怎么办?好办不?', 0.33718678),
(u'男性不孕不育有哪些特征', 0.33530876),
(u'结婚证丢了一本怎么办离婚', 0.33166665),
(u'怎样到地税局开发票?', 0.33079252),
(u'男性不孕不育检查要注意什么?', 0.3274408)
]大家可能比较关心训练数据的问题,这里统一回答:关于训练数据,不方便公开,私下分享也不方便,所以就不要问数据的事情了,数据来源就是爬取百度知道推荐的相似问,然后经过简单算法过滤。如果读者手头上本身有很多问句,那么其实也可以通过常见的检索算法检索出一些相似句,作为训练数据用。总而言之,训练数据没有特别严格要求,理论上有一定的相似性都可以。
至于训练硬件,开源的模型是在一张TITAN RTX(22G显存,batch_size=128)上训练了4天左右,显存和时间其实也没有硬性要求,视实际情况而定,如果显存没那么大,那么适当降低batch_size即可,如果语料本身不是很多,那么训练时间也不用那么长(大概是能完整遍历几遍数据集即可)。
暂时就只能想到这些了,还有啥问题欢迎留言讨论。
文章小结 #
本文介绍了早先我们放出来的SimBERT模型的训练原理,并开源了训练代码。SimBERT通过基于UniLM思想进行训练,同时具备检索和生成的能力,欢迎大家使用测试~
转载到请包括本文地址:https://spaces.ac.cn/archives/7427
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 18, 2020). 《鱼与熊掌兼得:融合检索和生成的SimBERT模型 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7427
@online{kexuefm-7427,
title={鱼与熊掌兼得:融合检索和生成的SimBERT模型},
author={苏剑林},
year={2020},
month={May},
url={\url{https://spaces.ac.cn/archives/7427}},
}

July 7th, 2021
苏神,请问这个网络的accuracy怎么算啊?
如果你说的是检索模型的分数,可以用现成的相似度数据来算。
https://kexue.fm/archives/8321
我指的是gen_synonyms(u'微信和支付宝哪个好?')
这个函数生成的输出,怎么判断生成的句子是否相似呢,有什么好一点的评价标准么,还是说靠人工判断。现成的相似度数据是指encoder.predict的输出么
才发现有链接... 谢谢苏神!
生成相似句的质量,一般只能靠目测
July 19th, 2021
请问哪儿体现了对比学习?没有理解了
拉近相似句的距离,增加batch内非相似句的距离。
这里的拉近相似句距离,莫不是就是代码里的用softmax一层?希望让非相似的为0,相似的为1?
是
September 14th, 2021
chinese_simbert_L-4_H-312_A-12转成pytorch版失败,怎么办?
我不知道
September 16th, 2021
那如果想把generator中的bert4keras用transformers替换掉,该怎么办?transformers中有那些对应的api,encoder和seq2seq该怎么改写?麻烦大神看看
pytorch请自便,爱莫能助~
September 20th, 2021
苏神,有点跟不上大佬的思路,
请问对d维度做l2归一化,得到V~,然后两两做内积这段中
1.l2归一化是什么操作?
2.两两做内积是哪两个做内积哈,
3.还有mask对角线,左边的语义相似度1,0不知道怎么来的?
谢谢
你是还没入门机器学习/NLP?
1、l2归一化的含义请自行搜索;
2、两两内积指batch内的句向量两两内积;
3、0/1是根据图示来的。
October 14th, 2021
用开源的模型试了一下,我输入的陈述句但是模型比较倾向于生成问句
这个版本就是用问句训练的,所以会倾向于生成问句。如果要生成陈述句的相似句,可以用v2版本:https://kexue.fm/archives/8454
October 25th, 2021
您好,想用simbert模型训练一个垂直领域的相似问生成模型,使用您训练的预训练参数,目前训练集30000条,一般微调的话模型训练多少遍比较合适呢?
多保存几轮模型,事后逐一测效果就是了。就这个信息,我也不确定要多少遍。
October 27th, 2021
你好苏神,我想问一下simbert seq2seq的训练部分,是递归地预测第二个sequence的每个token;还是和uniLM里一样,随机mask掉一些token,预测这些masked token?
前者。
了解,谢谢苏神
October 31st, 2021
我有个问题,输入一个句子不是生成一个相似句吗?代码中是如何生生多个相似句的呢?我的代码没太看懂。哪位大神可以解释一下,谢谢。
随机采样能生成多个目标句子
December 10th, 2021
苏神,我有两个问题请教一下:
1.我想训练一个基于英文语料的simbert模型,通过你贴的这个代码库里面的simbert.py能否训练?
2.如果问题1可以训练,我大概需要准备多大规模的英文句子对,才能达到不错的效果?
谢谢!
1. 按道理可以
2. 需要具体实验测试,如果要生成效果的话,估计起码10万吧。