






26
Jan
SVD分解(二):为什么SVD意味着聚类?
By 苏剑林 | 2017-01-26 | 103882位读者 | 引用提前祝各位读者新年快乐,2017行好运~
这篇文章主要想回答两个“为什么”的问题:1、为啥我就对SVD感兴趣了?;2、为啥我说SVD是一个聚类过程?回答的内容纯粹个人思辨结果,暂无参考文献。
为什么要研究SVD?
从2015年接触深度学习到现在,已经研究了快两年的深度学习了,现在深度学习、数据科学等概念也遍地开花。为什么在深度学习火起来的时候,我反而要回去研究“古老”的SVD分解呢?我觉得,SVD作为一个矩阵分解算法,它的价值不仅仅体现在它广泛的应用,它背后还有更加深刻的内涵,即它的可解释性。在深度学习流行的今天,不少人还是觉得深度学习(神经网络)就是一个有效的“黑箱”模型。但是,仅用“黑箱”二字来解释深度学习的有效性显然不能让人满意。前面已经说过,SVD分解本质上与不带激活函数的三层自编码机等价,理解SVD分解,能够为神经网络模型寻求一个合理的概率解释。
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 76371位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
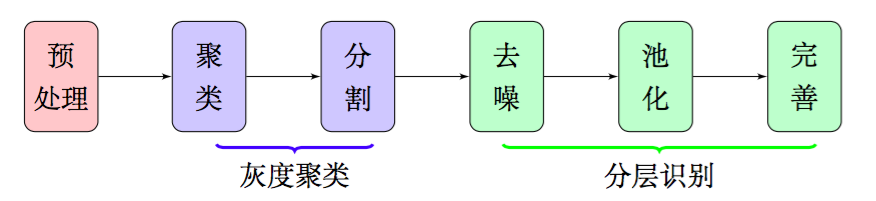
图2:特征提取大概流程

最近评论