






10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 81832位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
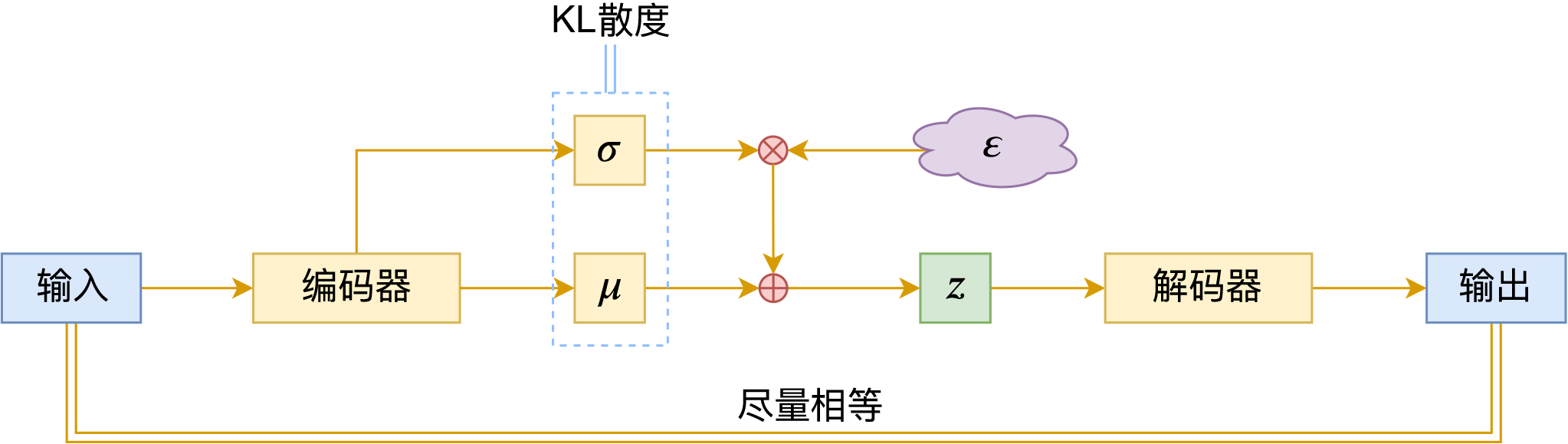
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
15
Jan
SVD分解(一):自编码器与人工智能
By 苏剑林 | 2017-01-15 | 55401位读者 | 引用
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 232378位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
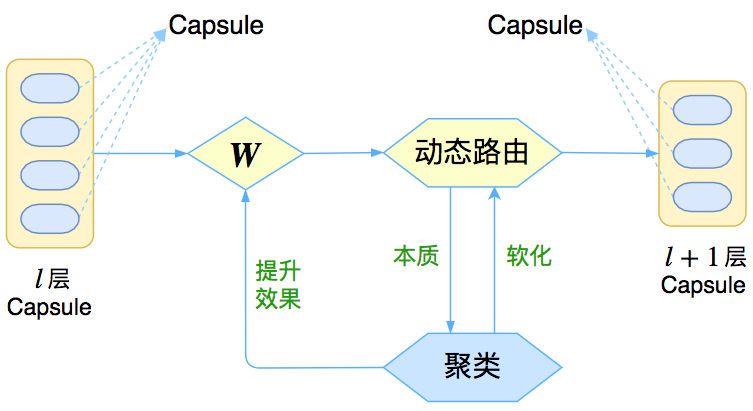
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
11
Aug
细水长flow之NICE:流模型的基本概念与实现
By 苏剑林 | 2018-08-11 | 316837位读者 | 引用前言:自从在机器之心上看到了glow模型之后(请看《下一个GAN?OpenAI提出可逆生成模型Glow》),我就一直对其念念不忘。现在机器学习模型层出不穷,我也经常关注一些新模型动态,但很少像glow模型那样让我怦然心动,有种“就是它了”的感觉。更意外的是,这个效果看起来如此好的模型,居然是我以前完全没有听说过的。于是我翻来覆去阅读了好几天,越读越觉得有意思,感觉通过它能将我之前的很多想法都关联起来。在此,先来个阶段总结。
背景
本文主要是《NICE: Non-linear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。
艰难的分布
众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。

glow模型生成的高清人脸
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 306004位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
27
Nov
从变分编码、信息瓶颈到正态分布:论遗忘的重要性
By 苏剑林 | 2018-11-27 | 177225位读者 | 引用这是一篇“散文”,我们来谈一下有着千丝万缕联系的三个东西:变分自编码器、信息瓶颈、正态分布。
众所周知,变分自编码器是一个很经典的生成模型,但实际上它有着超越生成模型的含义;而对于信息瓶颈,大家也许相对陌生一些,然而事实上信息瓶颈在去年也热闹了一阵子;至于正态分布,那就不用说了,它几乎跟所有机器学习领域都有或多或少的联系。
那么,当它们三个碰撞在一块时,又有什么样的故事可说呢?它们跟“遗忘”又有什么关系呢?
变分自编码器
在本博客你可以搜索到若干几篇介绍VAE的文章。下面简单回顾一下。
理论形式回顾
简单来说,VAE的优化目标是:
KL(˜p(x)p(z|x)‖
其中q(z)是标准正态分布,p(z|x),q(x|z)是条件正态分布,分别对应编码器、解码器。具体细节可以参考《变分自编码器(二):从贝叶斯观点出发》。
3
Feb
让研究人员绞尽脑汁的Transformer位置编码
By 苏剑林 | 2021-02-03 | 243035位读者 | 引用不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:1、想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;2、想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第k个向量\boldsymbol{x}_k中加入位置向量\boldsymbol{p}_k变为\boldsymbol{x}_k + \boldsymbol{p}_k,其中\boldsymbol{p}_k只依赖于位置编号k。
8
Mar
Transformer升级之路:1、Sinusoidal位置编码追根溯源
By 苏剑林 | 2021-03-08 | 174370位读者 | 引用最近笔者做了一些理解和改进Transformer的尝试,得到了一些似乎还有价值的经验和结论,遂开一个专题总结一下,命名为“Transformer升级之路”,既代表理解上的深入,也代表结果上的改进。
作为该专题的第一篇文章,笔者将会介绍自己对Google在《Attention is All You Need》中提出来的Sinusoidal位置编码
\begin{equation}\left\{\begin{aligned}&\boldsymbol{p}_{k,2i}=\sin\Big(k/10000^{2i/d}\Big)\\
&\boldsymbol{p}_{k, 2i+1}=\cos\Big(k/10000^{2i/d}\Big)
\end{aligned}\right.\label{eq:sin}\end{equation}
的新理解,其中\boldsymbol{p}_{k,2i},\boldsymbol{p}_{k,2i+1}分别是位置k的编码向量的第2i,2i+1个分量,d是向量维度。
作为位置编码的一个显式解,Google在原论文中对它的描述却寥寥无几,只是简单提及了它可以表达相对位置信息,后来知乎等平台上也出现了一些解读,它的一些特点也逐步为大家所知,但总体而言比较零散。特别是对于“它是怎么想出来的”、“非得要这个形式不可吗”等原理性问题,还没有比较好的答案。
因此,本文主要围绕这些问题展开思考,可能在思考过程中读者会有跟笔者一样的感觉,即越思考越觉得这个设计之精妙漂亮,让人叹服~

最近评论