






27
Oct
什么时候多进程的加速比可以大于1?
By 苏剑林 | 2019-10-27 | 76193位读者 | 引用多进程或者多线程等并行加速目前已经不是什么难事了,相信很多读者都体验过。一般来说,我们会有这样的结论:多进程的加速比很难达到1。换句话说,当你用10进程去并行跑一个任务时,一般只能获得不到10倍的加速,而且进程越多,这个加速比往往就越低。
要注意,我们刚才说“很难达到1”,说明我们的潜意识里就觉得加速比最多也就是1。理论上确实是的,难不成用10进程还能获得20倍的加速?这不是天上掉馅饼吗?不过我前几天确实碰到了一个加速比远大于1的例子,所以在这里跟大家分享一下。
词频统计
我的原始任务是统计词频:我有很多文章,然后我们要对这些文章进行分词,最后汇总出一个词频表出来。一般的写法是这样的:
tokens = {}
for text in read_texts():
for token in tokenize(text):
tokens[token] = tokens.get(token, 0) + 1这种写法在我统计THUCNews全部文章的词频时,大概花了20分钟。
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
By 苏剑林 | 2019-10-19 | 215014位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)
11
Oct
BN究竟起了什么作用?一个闭门造车的分析
By 苏剑林 | 2019-10-11 | 171737位读者 | 引用BN,也就是Batch Normalization,是当前深度学习模型(尤其是视觉相关模型)的一个相当重要的技巧,它能加速训练,甚至有一定的抗过拟合作用,还允许我们用更大的学习率,总的来说颇多好处(前提是你跑得起较大的batch size)。
那BN究竟是怎么起作用呢?早期的解释主要是基于概率分布的,大概意思是将每一层的输入分布都归一化到$\mathcal{N}(0,1)$上,减少了所谓的Internal Covariate Shift,从而稳定乃至加速了训练。这种解释看上去没什么毛病,但细思之下其实有问题的:不管哪一层的输入都不可能严格满足正态分布,从而单纯地将均值方差标准化无法实现标准分布$\mathcal{N}(0,1)$;其次,就算能做到$\mathcal{N}(0,1)$,这种诠释也无法进一步解释其他归一化手段(如Instance Normalization、Layer Normalization)起作用的原因。
在去年的论文《How Does Batch Normalization Help Optimization?》里边,作者明确地提出了上述质疑,否定了原来的一些观点,并提出了自己关于BN的新理解:他们认为BN主要作用是使得整个损失函数的landscape更为平滑,从而使得我们可以更平稳地进行训练。
本博文主要也是分享这篇论文的结论,但论述方法是笔者“闭门造车”地构思的。窃认为原论文的论述过于晦涩了,尤其是数学部分太不好理解,所以本文试图尽可能直观地表达同样观点。
(注:阅读本文之前,请确保你已经清楚知道BN是什么,本文不再重复介绍BN的概念和流程。)
29
Sep
“让Keras更酷一些!”:层与模型的重用技巧
By 苏剑林 | 2019-09-29 | 151952位读者 | 引用今天我们继续来深挖Keras,再次体验Keras那无与伦比的优雅设计。这一次我们的焦点是“重用”,主要是层与模型的重复使用。
所谓重用,一般就是奔着两个目标去:一是为了共享权重,也就是说要两个层不仅作用一样,还要共享权重,同步更新;二是避免重写代码,比如我们已经搭建好了一个模型,然后我们想拆解这个模型,构建一些子模型等。
基础
事实上,Keras已经为我们考虑好了很多,所以很多情况下,掌握好基本用法,就已经能满足我们很多需求了。
层的重用
层的重用是最简单的,将层初始化好,存起来,然后反复调用即可:
x_in = Input(shape=(784,))
x = x_in
layer = Dense(784, activation='relu') # 初始化一个层,并存起来
x = layer(x) # 第一次调用
x = layer(x) # 再次调用
x = layer(x) # 再次调用
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 448688位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
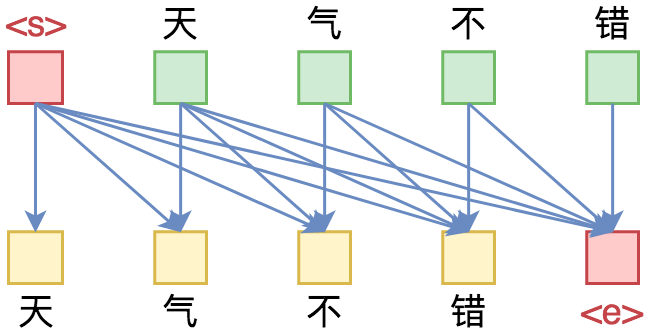
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 131392位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 110709位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
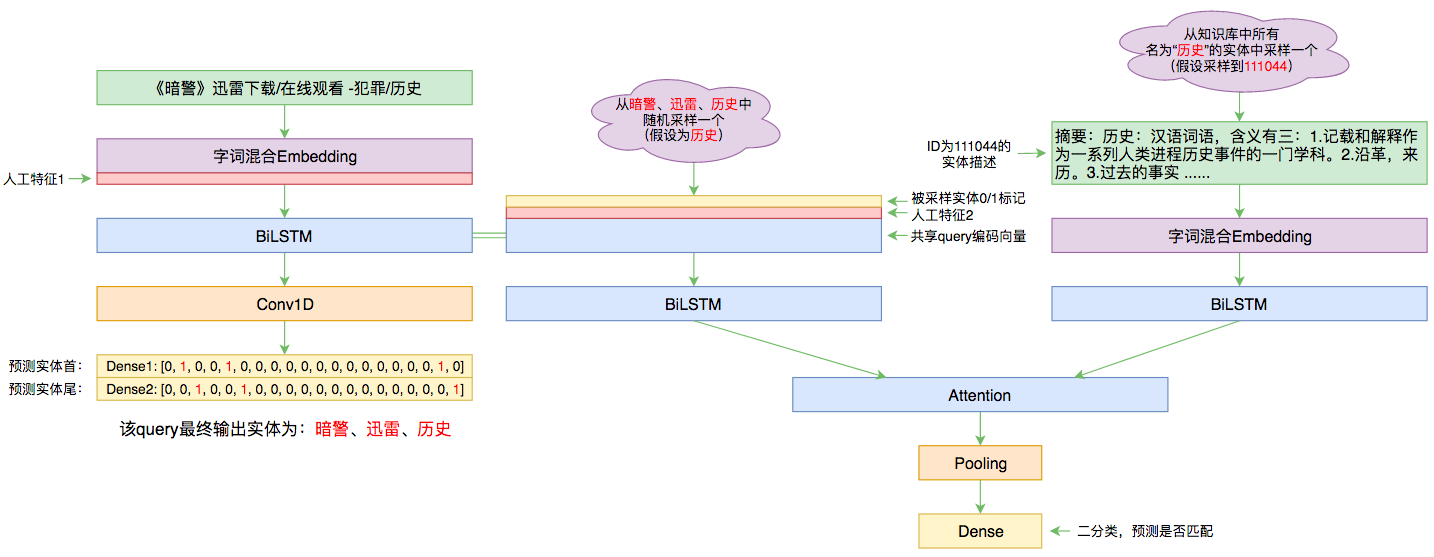
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
27
Aug
自己实现了一个bert4keras
By 苏剑林 | 2019-08-27 | 232043位读者 | 引用分享个人实现的bert4keras:
关于站长
智能搜索
支持整句搜索!网站自动使用结巴分词进行分词,并结合ngrams排序算法给出合理的搜索结果。

最近评论