






7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 117404位读者 |不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾 #
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
这个形式导致了一个有意思的问题:如果我们预训练的时候尽量将样本整理成同一长度(比如512),那么在预训练阶段$n$几乎一直就是512,也就是说$n$相当于一个常数,如果我们将它用于其他长度(比如64、128)微调,那么这个$n$究竟要自动改为样本长度,还是保持为512呢?
直觉应该是等于样本长度更加自适应一些,但答案很反直觉:$n$固定为512的微调效果比$n$取样本长度的效果要明显好!这就引人深思了......
问题定位 #
如果单看GAU的预训练效果,它是优于标准Attention的,所以GAU本身的拟合能力应该是没问题的,只是$\frac{1}{n}\text{relu}^2(\cdot)$在样本长度方面的迁移能力不好。为了确认这一点,笔者也尝试了混合不同长度的样本来做GAU的预训练,发现结果会有明显的改善。
那么,可能是GAU的什么地方出了问题呢?其实这不难猜测,GAU的整体运算可以简写成$\boldsymbol{O}=(\boldsymbol{U}\odot\boldsymbol{A}\boldsymbol{V})\boldsymbol{W}_o$,其中$\boldsymbol{U},\boldsymbol{V},\boldsymbol{W}_o$都是token-wise的,也就是说它们根本不会受到长度变化的影响,所以问题只能是出现在$\boldsymbol{A}$中。
以前我们用标准的Attention时,并没有出现类似的问题,以至于我们以前都无意识地觉得这是一个“理所当然”的性质。所以,我们需要从GAU的Attention与标准Attention的差异中发现问题。前面说了,两者不同的地方有两点,其一是多头Attention变成单头Attention,但是这顶多会让效果有一定波动,而我们测出来的结果是大幅下降,所以问题就只能出现在另一点,也就是归一化方式上,即Attention的$softmax$换成$\frac{1}{n}\text{relu}^2(\cdot)$所带来的。
验证这个猜测很简单,笔者将GAU中Attention的归一化方式换回Softmax后重新训练一个GAU模型,然后微调测试不同长度的任务,发现其效果比$\frac{1}{n}\text{relu}^2(\cdot)$时明显要好。所以,我们得出结论:Attention还是与Softmax更配~
原因分析 #
为什么更符合直觉的、自适应长度的$n$反而表现不如固定的$n$呢?既然我们已经以往用Softmax是没有这个问题的,所以我们不妨从Softmax出发找找灵感。Softmax的操作是:
\begin{equation}a_{i,j} = \frac{1}{Z_i}\exp\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right),\quad Z_i = \sum_{j=1}^n \exp\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right)\end{equation}
一个直接的问题就是:$Z_i$跟$n$的关系是怎样的呢?如果真有$Z_i=\mathcal{O}(n)$,那么理论上将$Z_i$换成$n$应该能取得相近的效果,至少不会是特别差的那种。
然而,我们知道注意力的重点是“注意”,它应该有能力“聚焦”到它认为比较重要的几个token上。同时,以往关于高效Transformer的一些实验结果显示,把标准Attention换成Local Attention后结果并不会明显下降,所以我们可以预计位置为$i$的Attention基本上就聚焦在$i$附近的若干token上,超出一定距离后就基本为0了。事实上,也有很多事后的可视化结果显示训练好的Attention矩阵其实是很稀疏的。
综合这些结果,我们可以得出,存在某个常数$k$,使得$|j-i|\geq k$时$\exp\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right)$都相当接近于0,这样一来$Z_i$应该更接近$\mathcal{O}(k)$而不是$\mathcal{O}(n)$,这就意味着$Z_i$很可能跟$n$是无关的,或者说跟$n$的数量级关系至少是小于$\mathcal{O}(n)$的!因此,我们如果要将$Z_i$替换成别的东西,那应该是一个比$n$的一次方更低阶的函数,甚至是一个常数。
现在回看GAU,它的激活函数换成了$\text{relu}^2(\cdot)$时,其Attention情况是类似的,甚至会更稀疏。这是因为$\text{relu}$操作有直接置零的作用,不像$\exp(\cdot)$总是正的,同时GAU“标配”旋转位置编码RoPE,在《Transformer升级之路:2、博采众长的旋转式位置编码》中我们就推导过,RoPE本身自带一定的远程衰减的能力。综合这些条件,GAU的归一化因子也应该是低于$\mathcal{O}(n)$的阶甚至是常数级别的。
熵不变性 #
由此,我们可以总结出GAU的三个解决方案,一是预训练和微调都用同一个固定的$n$;二是依然使用动态的样本长度$n$,但是预训练时需要用不同长度的样本来混合训练,不能只使用单一长度的样本;三就是像Softmax那样补充上一个归一化因子,让模型自己去学:
\begin{equation}a_{i,j} = \frac{1}{Z_i}\text{relu}^2\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right),\quad Z_i = \sum_{i=1}^n \text{relu}^2\left(\frac{\boldsymbol{q}_i\cdot\boldsymbol{k}_j}{\sqrt{d}}\right)\end{equation}
既然存在这些解决方案,那为什么我们还说“Attention与Softmax更配”呢?GAU的$\text{relu}^2(\cdot)$哪里不够配呢?首先,我们看GAU原论文的消融实验,显示出$\text{relu}^2(\cdot)$换成Softmax,效果基本是一致的:
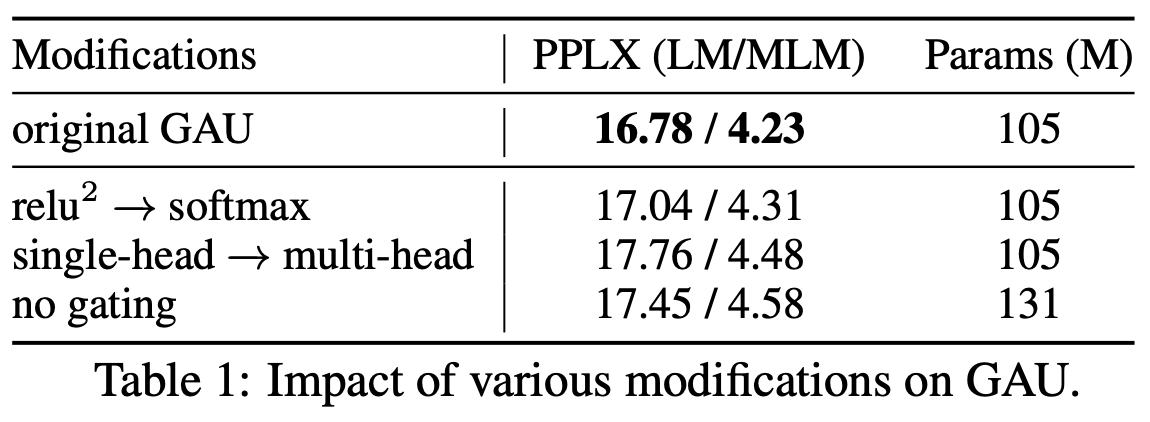
GAU的squared_relu换成softmax效果是相近的
有了这个基本保证之后,我们就可以看Softmax比$\text{relu}^2(\cdot)$好在哪里了。我们看刚才提到的GAU三个解决方案,方案一总让人感觉不够自适应,方案二必须用多种长度训练显得不够优雅,至于方案三补充了归一化因子后形式上相比Softmax反而显得“臃肿”了。所以,总体来说还是用Softmax显得更为优雅有效。
此外,泛化能力可以简单分为“内插”和“外推”两种,在这里内插(外推)指的是测试长度小于(大于)训练长度。我们刚才说归一化因子是常数量级,更多是在内插范围内说的。对于外推来说,如果长度足够长,$\boldsymbol{q}_i,\boldsymbol{k}_j$都“挤”在一起,所以很难保持距离超过某个范围就很接近于0的特性。而如果我们用Softmax的话,就是它可以推导出一个“熵不变性”的版本,来增强模型的外推能力:
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\log_{512} n}{\sqrt{d}}QK^{\top}\right)V\end{equation}
在《从熵不变性看Attention的Scale操作》中我们做过简单的对比实验,显示该版本确实能提高模型在超出训练长度外的效果。
那么,$\text{relu}^2(\cdot)$能否推一个“熵不变性”的版本呢?答案是不能,因为它相当于是通过温度参数来调节分布的熵,这要求激活函数不能是具备正齐次性,比如对于幂函数有$(\lambda \boldsymbol{q}_i\cdot\boldsymbol{k}_j)^n=\lambda^n (\boldsymbol{q}_i\cdot\boldsymbol{k}_j)^n$,归一化后$\lambda^n$就抵消了,不起作用。激活函数最好比幂函数高一阶,才比较好实现这个调控,而比幂函数高阶的函数,最常见就是指数函数了,而指数归一化正好就是Softmax。
本文小结 #
本文分析了GAU在微调效果不佳的原因,发现Attention的归一化因子应该是接近常数量级的,所以GAU用$n$或者$n^2$做归一化因子会表现不佳。总的来说,笔者认为Attention还是跟Softmax更配,它是一个不错的基准,并且还可以通过“熵不变性”的拓展来进一步增强外推能力。
转载到请包括本文地址:https://spaces.ac.cn/archives/9019
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 07, 2022). 《听说Attention与Softmax更配哦~ 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/9019
@online{kexuefm-9019,
title={听说Attention与Softmax更配哦~},
author={苏剑林},
year={2022},
month={Apr},
url={\url{https://spaces.ac.cn/archives/9019}},
}

April 7th, 2022
现在回看GAU,它的激活函数换成了relu2(⋅)时,其Attention情况是类似的,甚至会更稀疏。
虽然没实验比较过,但个人感觉relu方的attn矩阵不会比softmax更稀疏,毕竟relu方没有经过归一化。反倒是因为softmax因为有归一化,qk又经过了指数函数的增幅,所以必然会更稀疏到注意力集中在极少点上。所以标准transformer才必配多头增加多样性。相对的relu方因为没有归一化,所以结果肯定没softmax那么稀疏,不需要多头来进一步增加多样性。
首先,稀疏是相对值的比较,跟有没有归一化没关系,比如$[100, 1, 1]$就比$[0.3, 0.3, 0.4]$更稀疏了。
然后,$\text{relu}^2(x)$在正方向是$x^2$,这部分的阶是不如指数函数,但是在负方向是$0$,这部分的阶是远远高于指数函数的(因为指数函数严格上都到不了0),所以$\text{relu}^2(x)$是可能比softmax更稀疏的。
最后,GAU用了RoPE,RoPE具有一定的远程衰减功能,在相对距离足够大时,即便是初始阶段经过RoPE之后的内积结果平均来说至少有一半是负的,所以经过$\text{relu}^2(\cdot)$之后的Attention矩阵平均来说至少有一半是0(绝对等于0),这是softmax出来的Attention矩阵很难具备的。
April 8th, 2022
上一个博客中回复过您,关于用原生Flash效果比较差,尤其是自适应长度n的话;
后来也测试了将relu**2换成了softmax,结果要好不少。 感谢苏神的理论讲解;标题很赞
谢谢哈。欢迎更多此类讨论~
我的最后实验结论是熵不变版本的Softmax(本文公式$(4)$)效果是最佳的,欢迎尝试~
按谷歌论文relu方的话单头效果甚至好过多头,换softmax的话难道也是如此?如果是的话有些不可思议。
单头好于多头是配合GAU来说的,并非普通的Self Attention的结果,这个跟$\text{relu}^2$还是$softmax$应该没啥关联。
Hi 苏神,share下在Flash模型在序列建模上测试的结果哈:
- 熵不变版本的softmax 效果要好于 原生的softmax,二者在训练阶段效果很类似,基本拉不开差距,但是在测试集上,熵不变版本要比softmax要好一些,大概差0.1个点。
- 多次测试,发现Flash对 归一化因子的选择,的确是非常敏感。。效果方差很大。可能直接无法训练,不收敛
PS: 我是在这个lucidrains开源的线性复杂度的FLASH上修改的:https://github.com/lucidrains/FLASH-pytorch/blob/main/flash_pytorch/flash_pytorch.py#L314 加入归一化因子的
线性的FLASH我没试过,觉得没有GAU漂亮。我在训练一个纯GAU+熵不变softmax的MLM模型,当前效果显示比Self Attention+FFN的要好,过几天训练完成后放出。
期待~
GAU的确很优雅,不过我们会有长序列建模的需求,之前是在bigbird/longformer尝试的,打算换为线性的Flash。
用线性FLASH序列长度起码要5000吧?不然感觉没太大用的必要。
感谢苏神回复哈~ 现在序列token长度4000左右,所以才用bigbird/longformer/线性Flash之类的模型。
另外苏神,请教个问题,关于中文word粒度的字典大小一般取多少比较合适呢? 我在 https://kexue.fm/archives/7758 这个里面,看到对语料jieba分词之后,取了Top20k,这个数量是不是有些少呢。毕竟中文里面,词相比字稀疏太多了。
想听下苏神的看法。
感谢
@shomy|comment-18975
那个链接的是初次尝试,后面我们训练RoFormer的时候,词表大小是50K,感觉这个量级比较适中。
苏神,你从零训练用的熵不变softmax还是选用以512为底的log吗?
是的,这个值改动的意义也不是特别大了,固定一个标准就好。
lucidrains的FLASH实现方案中用了一个token shift的方案:https://github.com/lucidrains/FLASH-pytorch/blob/8e0d2fd7925c0de9703d666ea2cc004327f6e544/flash_pytorch/flash_pytorch.py#L270,苏神有兴趣测试一下不。看这操作的意思,可能是改善了分组带来的性能损失,那直接用在GAU上不知道效果怎么样。
@Jaheim李|comment-18964
这个我听说了,据说对单向语言模型都有帮助。
请问一下,你的seq2seq测试,是decoder部分也进行替换FLASH或者GAU吗?还是说只替换了encoder部分?
June 7th, 2022
苏神,请问一下公式(2)中求和符号的下标是不是应该是j=1呀
是的,已修正,谢谢。
May 9th, 2023
如果用一個 1-lipschitz non-negative gated activation function 來取代 Softmax,或許效果會比 Square ReLU 要好。
拍脑袋的想法有很多,建议有兴趣多验证一下哈。
从 Dirichlet energy 的角度,可以推出 $E(\sigma(x)) \le E(x)$,其中 $\sigma(\cdot)$ 代表 1-lipschitz activation function。因爲需要滿足 attention matrix 是非負矩陣,所以可以進一步推出 1-lipschitz non-negative activation function。又因爲 gated activation function 例如 SiLU 或 GELU 可以增大矩陣的 rank,所以可以進一步推出 1-lipschitz non-negative gated activation function。
其他好理解,那Dirichlet energy或者1-lipschitz activation function的出发点又是什么呢?
Dirichlet energy for a graph: $\mathbf{E}_{\text{D}} = \frac{1}{2}\sum_{u\in\mathbf{V}}\lVert{\nabla_{u}\mathbf{x}}\rVert_{2}^{2}
= \frac{1}{2}\sum_{(u,v)\in\mathbf{E}}\mathbf{A}(u,v)\lVert{\mathbf{x}(u)-\mathbf{x}(v)}\rVert_{2}^{2}$.
給定一個 1-lipschitz activation function $\sigma(\cdot)$,易證 $\mathbf{E}(\mathbf{x}) \ge \mathbf{E}(\sigma(\mathbf{x}))$。
Dirichlet energy 可以用於衡量一張圖的光滑程度。Transformers 也會遇到和 GNNs 一樣的 over-smoothing issue$~$[]。
Reference:
1. Zhou, D., Kang, B., Jin, X., Yang, L., Lian, X., Jiang, Z., … Feng, J. (2021). DeepViT: Towards Deeper Vision Transformer. ArXiv Preprint ArXiv: Arxiv-2103. 11886.
2. Dong, Y., Cordonnier, J.-B., & Loukas, A. (07 2021). Attention is not all you need: pure attention loses rank doubly exponentially with depth. In M. Meila & T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning (pp. 2793–2803). PMLR.
3. Wang, P., Zheng, W., Chen, T., & Wang, Z. (2022). Anti-Oversmoothing in Deep Vision Transformers via the Fourier Domain Analysis: From Theory to Practice. International Conference on Learning Representations.
4. Shi, H., Gao, J., Xu, H., Liang, X., Li, Z., Kong, L., … Kwok, J. (2022). Revisiting Over-smoothing in BERT from the Perspective of Graph. International Conference on Learning Representations.
5. Guo, X., Wang, Y., Du, T., & Wang, Y. (2023). ContraNorm: A Contrastive Learning Perspective on Oversmoothing and Beyond. The Eleventh International Conference on Learning Representations.
受教了,获益良多,感谢推荐,我好好理解一下。(btw,评论区的编辑器确实比较简陋,毕竟不是BBS,难为大佬了)
我也沒測試過 1-lipschitz non-negative gated activation function 的效果。在我新的一篇論文中(還未發表),我是計畫使用 $LipSReLU(x) = 0.5x \ast \max(0,\ x)$ 來取代 square ReLU。
btw,這個評論回覆好難用啊…… 既不支持 \mathcal,也不支持修改或刪除評論。
May 20th, 2023
@hazdzz|comment-21680
重新开一楼吧。这个已经不是非负了,看上去就是把GLU的各种变体直接去掉可学习参数了~
這個函數確實是非負的,可以看作是 $0.5 * \mathrm{ReLU}^{2}(x)$。我稍微修改了一下,效果好了很多。
纯粹是square relu乘以0.5吗?这个0.5影响那么大?
這樣就能保證這個 activation function 是 1-Lipschitz 了。
我覺得 Hadamard product 滿神奇的。我沒找到相關的論文來解釋爲什麼一個 neural network 採用基於 Hadamard product 的 gated activation function,例如 GLU, GTU, GELU, SiLU,和 Mish,會比採用一般的 activation function 表現出來的結果要更好。
确实如此,这类self-gated的激活函数确实表现好得出奇。
關於 $1$-Lipschitz gated activation function,Residual Flows for Invertible Generative Modeling 這篇 paper 有一些「簡陋」的說明。
November 2nd, 2023
苏老师,lstm的内插能力您是怎么理解的,是不是RNN天生具有内插能力?
RNN的内插能力具体怎么定义?指的是对真正的时间序列的拟合能力么?
December 27th, 2023
苏神我有一计不知可否哈哈
既然relu能在负方向超越softmax,softmax在正方向又使无穷阶,那类似于swish(结合了relu和softmax),我们在attention归一化前,结合一下exp和relu,不就无敌了?
苏神怎么看?
我试了一下,使用softmax(att.masked_fill(att < 0, torch.finfo(att.dtype).min)),也就是对于< q,k >内积 < 0的直接mask掉,对MLM精度会有一丢丢提升(acc一个epoch提升大概0.1%)。
不过内积 < 0只是一个门限,是不是提高点门限就能显著降噪呢?
$\text{relu}(e^x - 1)$?主要是没想到很优雅的结合方式
February 1st, 2024
激活函数最好比幂函数高一阶,才比较好实现这个调控,而比幂函数高阶的函数,最常见就是指数函数了,而指数归一化正好就是Softmax。
sigmoid会是一个合适的激活函数吗
March 21st, 2025
请问苏神有试过直接加个normalization吗,效果如何?
你说的是$\text{Norm}(\text{relu}(QK^{\top})V)$之类的操作?确实还没试过。