






31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 111631位读者 |CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介 #
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
文本分类 #
首先是IFLYTEK和TNEWS两个任务,它们是普通的文本分类问题,所以做法很简单,就是常规的“[CLS]+句子+[SEP]“传入到BERT中,然后取出[CLS]的hidden向量做分类就行。
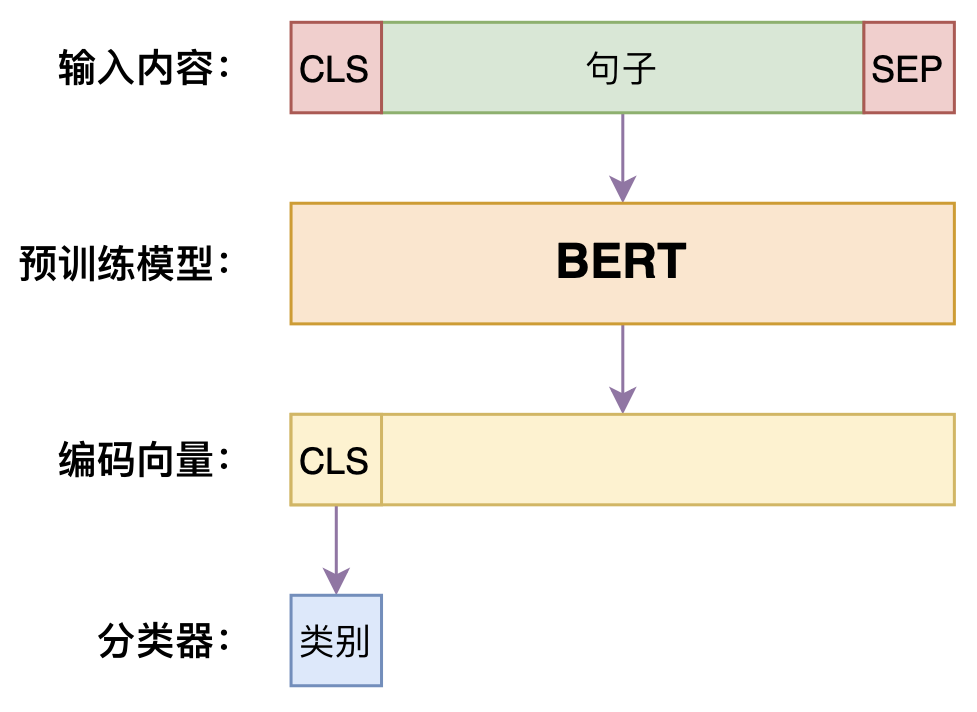
文本分类模型示意图
另外,代词消歧任务WSC也可以转化为单文本分类任务,原任务是判断一个句子中的两个片段(其中一个是代词)是否指代同一个对象,baseline的做法是在文本中用不同的符号标记出这两个片段,然后就直接将这个标记后的文本传入BERT进行二分类。
文本匹配 #
接下来,AFQMC、CMNLI、OCNLI是三个文本匹配任务。所谓文本匹配,简单理解就是句子对的分类任务,比如相似匹配是判断两个句子是否相似;自然语言推理是判断两个句子之间的逻辑关系(蕴含、中立、矛盾)等。在预训练时代,句子匹配任务的标准做法就是将两个句子用[SEP]连接起来,然后当成单文本分类任务来做。
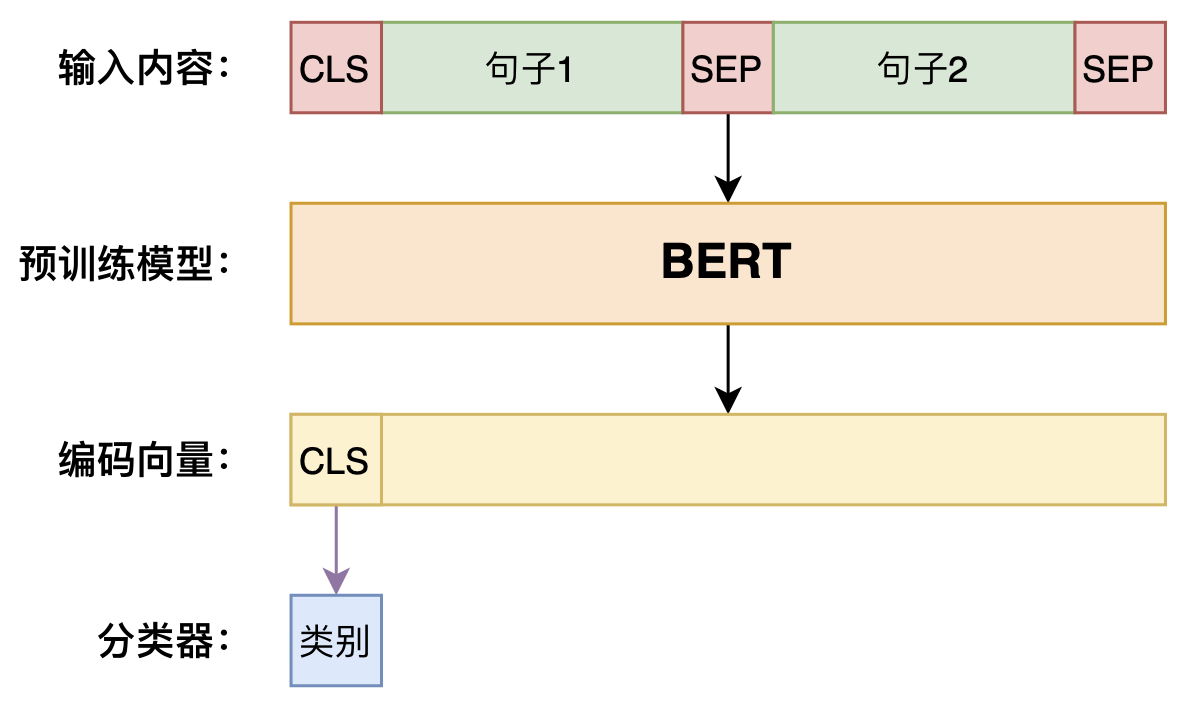
文本匹配模型示意图
需要指出的是,在原始的BERT中,两个句子的SegmentID(原始代码叫做token type id)是不一样的,但这里考虑到像RoBERTa这样的模型没有NSP任务,编号为1的SegmentID可能没有被预训练过,所以这里的实现中SegmentID都是用全0。实验结果显示,这样处理并不会降低文本匹配的效果。
类似地,CSL这个任务,是判断摘要描述与所给的4个关键词是否匹配,我们将4个关键词用分号“;”连接起来,作为一个句子对待,这样也就转换成了常规的文本匹配问题了。
阅读理解 #
阅读理解是指CMRC2018任务,这是一个格式跟SQUAD一样的抽取式阅读理解任务,一个段落会配有多个问题,每个问题必然有答案并且答案是段落的一个片段。一般的做法是将问题与段落用[SEP]拼接之后传入到BERT中,然后用两个全连接层分别预测首尾的位置。这样做的问题是割裂了首尾之间的联系,而且使得训练和预测的行为不一致。
这里的baseline使用GlobalPointer作为输出结构,它将首尾组合作为一个整体来进行分类,具体细节可以看《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。使用GlobalPointer能使得训练和预测的行为完全一致,并明显提高解码速度。
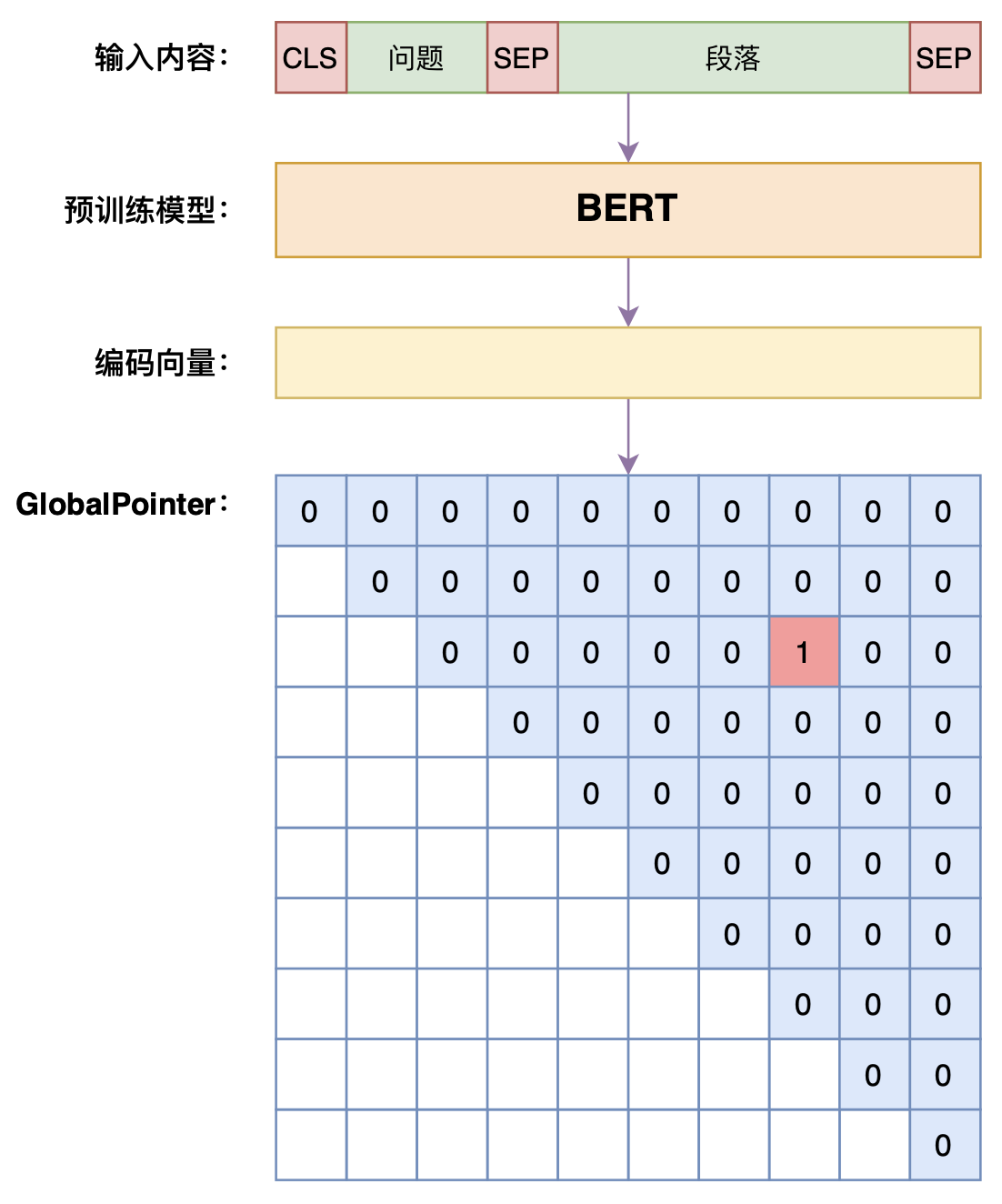
抽取式阅读理解模型示意图
此外,不管是SQUAD还是CMRC2018,段落长度多数是明显超过512的,并且有些问题的答案确实在比较后的位置,直接截断前面的部分可能就没有答案了。如果用NEZHA、RoFormer这样的模型,可以直接处理超过512的文本,但像BERT这样的模型就不好处理。为了保持代码的通用性,这里沿用了BERT原始basleine的滑窗设计,即以128为步长将段落分割为多个子段落,每个段落逐一与问题组合传入到模型中。这样分割之后,那么就允许某些段落对于问题来说是“无答案”的,这时候直接将答案指向[CLS]位置$(0,0)$。在预测阶段,长段落也是用同样的方法进行分割,然后逐一回答同一个问题,最后取分数最高的答案。
单项选择 #
这里的单项选择指的是C3任务,它也算是一种阅读理解任务,同样是一个段落提了多个问题,问题的答案是4个所给的候选答案之一,但不一定是段落中的片段。这种多项选择的baseline做法可能会出乎很多人的意料,它相当于转化为文本匹配问题,将每个候选答案与段落、问题进行匹配,然后预测时取分数最高的那个。
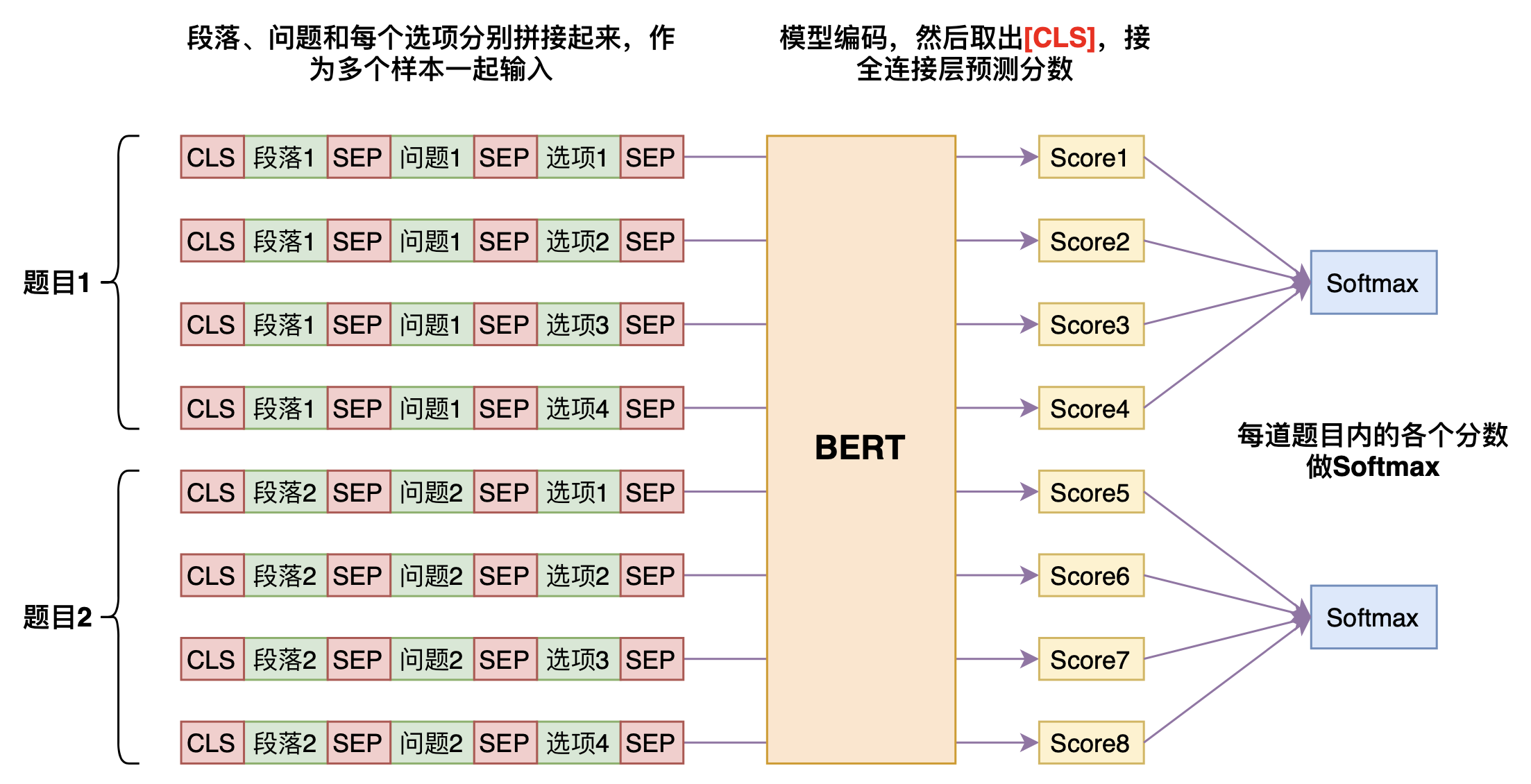
单项选择模型示意图
这样一来,原来的一个问题就需要拆分为4个样本来处理,需要预测4次才能做出答案,大大增加了计算量。但让人惊奇的是,这种做法是基本是所有直观想到的baseline中效果最好的,比将所有候选答案拼在一起然后做4分类要好得多。英文领域类似的任务是DREAM,其榜单上的模型基本上都是这个思路的变种。
成语理解 #
成语阅读理解任务CHID,本质上也是一个单项选择阅读理解问题,但它形式上复杂不少,所以单独拿出来介绍。
具体来说,CHID的每个样本有10个候选成语,以及由若干道题目,每道题目有若干个空位,我们就是要决定这些空位最适合填入哪个候选成语。如果每道题只有一个空位,那么就直接套用上一节的单项选择做法就行了;但这里每道题是可能有多个空位的,而用单项选择的做法,每次只能识别一个空位,所以我们用[unused0]代替我们要识别的空位,而没被识别的空位(如果有的话)直接用4个[MASK]代替,比如:
[CLS] “这其实是个荒唐的闹剧,苹果发现iPad大陆商标的拥有人不属于台湾唯冠而是深圳唯冠后,开始着急了并 [unused1] 。”肖才元表示。事实上,两个戏剧性的因素让该案更显得 [MASK] [MASK] [MASK] [MASK] 。苹果在香港法院提起的诉讼案件中,所提交的材料显示,IPADL公司实为苹果公司律师操作下成立的具有特殊目的的,旨在用于收购唯冠手中i-Pad商标权的公司。 [SEP] 一锤定音 [SEP]
也就是说,一道有多个空位的题目将会被拆开为多道小题,而按照前述单项选择的做法,每道小题都需要跟候选答案拼接来预测,所以每道小题的计算成本都相当于普通分类的10个样本了,这确实有点费劲,但为了效果没办法了。为了达到更大的batch_size效果,通常需要用到梯度累积。另外,有些题目还是比较长的,我们仍然需要截断,截断的方式是以当前要识别的空位为中心,尽量向左向右都延伸同样的距离。
最后,根据题目的设计,每个样本有若干道题目,每道题目的每个空位都共用10个候选成语,但每个空位的答案是不会重复的。如果预测的时候每个空位直接独立地取最大值的答案,那么就可能出现重复的预测结果,与问题设计相违背。
为了使得预测结果不重复,我们需要用到“匈牙利算法”:假设有$m$个空位,每个空位有$n > m$个候选答案,那么我们将得到$m\times n$的打分句子,我们要为每个空位选择不一样的答案,并且使得总分最大,这在数学上被称为“指派问题”,标准解法就是“匈牙利算法”,我们直接用scipy.optimize.linear_sum_assignment求解就行了。这样的后处理算法比直接逐项取最大(可能导致重复答案)能提升6%左右的准确率。
实体识别 #
最后一个任务是CLUENER,常规的非嵌套命名实体识别任务。常见的baseline是BERT+Softmax或者BERT+CRF,这里用的则是BERT+GlobalPointer,同样可以参考《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。当GlobalPointer用于NER时,可以统一处理嵌套和非嵌套情况。笔者的多次实验显示,在非嵌套情形,GlobalPointer完全可以取得跟CRF相媲美的效果,并且训练和预测速度都更快。所以用GlobalPointer作为NER的baseline是顺理成章的。
效果对比 #
在CLUE的测试集上,各任务效果比较如下表,其中标$_{\text{-old}}$的是从CLUE官方找到的结果,标$_{\text{-our}}$的是本套代码的复现结果。这里的BERT和RoBERTa都是base版,BERT是Google最开始放出的中文BERT,RoBERTa是哈工大开源的RoBERTa_wwm_ext,large版本有算力有时间再测~
$$\begin{array}{c}
\text{分类任务} \\
{\begin{array}{c|ccccccc}
\hline
& \text{IFLYTEK} & \text{TNEWS} & \text{AFQMC} & \text{CMNLI} & \text{OCNLI} & \text{WSC} & \text{CSL} \\
\hline
\text{BERT}_{\text{-old}} & 60.29 & 57.42 & 73.70 & 79.69 & 72.20 & 74.60 & 80.36\\
\text{BERT}_{\text{-our}} & 61.19 & 56.29 & 73.37 & 79.37 & 71.73 & 73.85 & 84.03 \\
\hline
\text{RoBERTa}_{\text{-old}} & 60.31 & \text{-} & 74.04 & 80.51 & \text{-} & \text{-} & 81.00\\
\text{RoBERTa}_{\text{-our}} & 61.12 & 58.35 & 73.61 & 80.81 & 74.27 & 82.28 & 85.33\\
\hline
\end{array}}
\end{array}$$
$$\begin{array}{c}
\text{阅读理解和NER任务} \\
{\begin{array}{c|cccc}
\hline
& \text{CMRC2018} & \text{C3} & \text{CHID} & \text{CLUENER} \\
\hline
\text{BERT}_{\text{-old}} & 71.60 & 64.50 & 82.04 & 78.82\\
\text{BERT}_{\text{-our}} & 72.10 & 61.33 & 85.13 & 78.68\\
\hline
\text{RoBERTa}_{\text{-old}} & 75.20 & 66.50 & 83.62 & \text{-}\\
\text{RoBERTa}_{\text{-our}} & 75.40 & 67.11 & 86.04 & 79.38\\
\hline
\end{array}}
\end{array}$$
注:这里TNEWS和WSC为空,是因为它们后来更新了测试集,但是官方Github并没有及时更新它们在RoBERTa上的测试结果;而OCNLI和CLUENER为空则是因为官方只测了BERT base和RoBERTa large的结果,RoBERTa base的结果也没有给出。
文章小结 #
本文分享了笔者基于bert4keras构建的CLUE评测基准代码,以及简单介绍了每类任务的建模思路。该套baseline代码有着简单清晰、易于迁移的特点,并且基本能达到CLUE官方宣称的基准成绩,部分任务还更优,因此算是上是及格的基准代码了。
转载到请包括本文地址:https://spaces.ac.cn/archives/8739
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Oct. 31, 2021). 《bert4keras在手,baseline我有:CLUE基准代码 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8739
@online{kexuefm-8739,
title={bert4keras在手,baseline我有:CLUE基准代码},
author={苏剑林},
year={2021},
month={Oct},
url={\url{https://spaces.ac.cn/archives/8739}},
}

November 2nd, 2021
苏神您好,请问bert4keras model在inference的时候打开dropout呢?
在加载模型之前,执行K.set_learning_phase(1)试试。
November 24th, 2021
苏神,ocnli自然语言推理的训练数据,为什么segment采用的是全零,而不是tokenizer出来的segment_ids
batch_segment_ids.append([0] * len(segment_ids))
是我不仔细看博客了。。
December 1st, 2021
想问下苏神在公司里模型开发一般用哪个环境?
指的是什么环境?
August 8th, 2022
请问下苏神 我在运行cluener的时候报错显示"Output tensors to a Model must be the output of a Keras `Layer`" 报错语句是"model = keras.models.Model(base.model.input, output)" 不知道错在哪里 请指教
完全没改过模型代码?
对的 完全没改过 报错信息里有“Found: < bert4keras.layers.GlobalPointer object at 0x000001D578B97208 >” 所以我想问题是不是出在GlobalPointer里面?
keras和tf版本分别是多少?
回苏神 keras=2.3.1 tf-gpu=2.2.0
@柏小琦|comment-19602
哪个文件哪一行出现的错误?我暂时还无法理解这个错误...
cluener文件的第106行,网上说这个报错原因是因为tf和keras混用,需要把一些tf语句用lambda修饰成tf.keras.layer形式。 我已经改了很多了,还是报错,我在想是不是我没找全或者没找到关键语句? 该怎么找全呢
如果qq群里提问的也是你,那么就是你自行改错了源码。认真对比你改的结果和原始文件的差异,就能发现问题了
December 15th, 2022
请问哪个版本的bert4keras支持tensorflow-gpu=2.7.0的使用
作者不对任何tf 2.x做主动支持。
February 19th, 2023
苏神你好,想问一下,您的代码针对CLUE这一系列下游任务进行评测时都是对bert进行重新训练的。如果想对一个预训练好的bert进行finetune应该怎么做呢?例如针对分类任务。(主要是想问一下finetune过程中,模型的参数是否是部分更新),谢谢苏神。
如果您之前的blog实现的demo有实现过finetune的,可以帮我找一下吗,我去详细了解一下。感谢!
我想明白了,我傻了。做的一直都是finetune,不是重头训练。是我了解不够清晰。---
我最后还是想问一下,按照我的理解,如上这个finetune的过程对整个bert模型的参数都进行了调整更新。但是对于下游任务微调的过程不应该是只更新和具体下游任务相关的最后的全连接层参数或者是附带上最后几层transformer-block的参数吗?
是的,原本就是finetune。一般情况下,为了效果,都是finetune全部参数,而不是部分参数。
明白了,谢谢苏神。我在看了CMRC任务的demo之后还有两点没相通的地方:
(1)对于阅读理解CMRC2018任务,您在博客写道:
一般的做法是将问题与段落用[SEP]拼接之后传入到BERT中,然后用两个全连接层分别预测首尾的位置。
在代码中您定义了一个CustomMasking类,注释为自定义mask(主要用于mask掉question部分)。我想了很久,但是还是不明白为什么对于这个任务需要把question给mask掉呢?
对于seq2seq类型的任务,用UniLM的mask形式进行处理我明白,但是想不通这里是为什么。
(2)并且在之前的demo中,例如在这篇文章[从语言模型到Seq2Seq:Transformer如戏,全靠Mask]提到的标题生成任务,就是用UniLM来做的,是根据segment_id来生成mask矩阵。而在CMRC任务的代码中的数据生成器部分构建了一个batch_masks,我不知道这个batch_masks的作用是什么?是通过它来生成mask矩阵吗?假设是这样的话,那和用segment_id来生成mask矩阵这两个方法是不是都可以?
我仔细又看了一下代码,捋通了。
(1)之所以把question给mask掉是在传入GP的时候mask掉的,因为GP解码的答案肯定是(2)batch_masks的作用就是为了在输入GP的时候把question给mask掉,而不是Bert内部的mask,所以上面我说的猜想是错的。是我把这两个mask搞混了。
想了很久没想通,后来又自己豁然开朗了。
恭喜恭喜,自己想通的收获是最大的。
March 17th, 2023
苏神您好!我在测试CMRC2018任务时(用的是哈工大的Roberta参数),发现globalpointer_accuracy能跑到0.76,但是验证集的val_acc却一直在0.5~0.6徘徊,感觉像是完全没训练过一样,请问可能是什么原因导致的呢?
你是不是对“完全没训练过”有什么误解?你觉得抽取式阅读理解随机蒙,准确率能有50%?也就是说你随机从一篇文章中抽一个片段,有50%的概率跟正确答案完全匹配?你这是天选之子的概率吧?
April 19th, 2023
苏神您好!还是CMRC2018任务的测试得分问题,因为硬件条件有限,我的batch_size参数只能设置成8,maxlen(512)stride(128)epochs(10)这些参数都没变,然后调参learning_rate(从e-5到e-4),得到的best_val_acc最高是到0.60+,距离博客中的robert分数差了十几个点,实在是没有头绪,只能向苏神请教了
0.6已经接近最优了。训练脚本报告的是acc(或者说em),而本文的表格报告的是f1+em的平均值,这个平均值需要提交到clue上才能获得。
原来如此,了解,感谢!