






23
Mar
Transformer升级之路:2、博采众长的旋转式位置编码
By 苏剑林 | 2021-03-23 | 570382位读者 |上一篇文章中,我们对原始的Sinusoidal位置编码做了较为详细的推导和理解,总的感觉是Sinusoidal位置编码是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。
本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
基本思路 #
在之前的文章《让研究人员绞尽脑汁的Transformer位置编码》中我们就简要介绍过RoPE,当时称之为“融合式”,本文则更加详细地介绍它的来源与性质。在RoPE中,我们的出发点就是“通过绝对位置编码的方式实现相对位置编码”,这样做既有理论上的优雅之处,也有实践上的实用之处,比如它可以拓展到线性Attention中就是主要因为这一点。
为了达到这个目的,我们假设通过下述运算来给$\boldsymbol{q},\boldsymbol{k}$添加绝对位置信息:
\begin{equation}\tilde{\boldsymbol{q}}_m = \boldsymbol{f}(\boldsymbol{q}, m), \quad\tilde{\boldsymbol{k}}_n = \boldsymbol{f}(\boldsymbol{k}, n)\end{equation}
也就是说,我们分别为$\boldsymbol{q},\boldsymbol{k}$设计操作$\boldsymbol{f}(\cdot, m),\boldsymbol{f}(\cdot, n)$,使得经过该操作后,$\tilde{\boldsymbol{q}}_m,\tilde{\boldsymbol{k}}_n$就带有了位置$m,n$的绝对位置信息。Attention的核心运算是内积,所以我们希望的内积的结果带有相对位置信息,因此假设存在恒等关系:
\begin{equation}\langle\boldsymbol{f}(\boldsymbol{q}, m), \boldsymbol{f}(\boldsymbol{k}, n)\rangle = g(\boldsymbol{q},\boldsymbol{k},m-n)\end{equation}
所以我们要求出该恒等式的一个(尽可能简单的)解。求解过程还需要一些初始条件,显然我们可以合理地设$\boldsymbol{f}(\boldsymbol{q}, 0)=\boldsymbol{q}$和$\boldsymbol{f}(\boldsymbol{k}, 0)=\boldsymbol{k}$。
求解过程 #
同上一篇思路一样,我们先考虑二维情形,然后借助复数来求解。在复数中有$\langle\boldsymbol{q},\boldsymbol{k}\rangle=\text{Re}[\boldsymbol{q}\boldsymbol{k}^*]$,$\text{Re}[]$代表复数的实部,所以我们有
\begin{equation}\text{Re}[\boldsymbol{f}(\boldsymbol{q}, m)\boldsymbol{f}^*(\boldsymbol{k}, n)] = g(\boldsymbol{q},\boldsymbol{k},m-n)\end{equation}
简单起见,我们假设存在复数$\boldsymbol{g}(\boldsymbol{q},\boldsymbol{k},m-n)$,使得$\boldsymbol{f}(\boldsymbol{q}, m)\boldsymbol{f}^*(\boldsymbol{k}, n) = \boldsymbol{g}(\boldsymbol{q},\boldsymbol{k},m-n)$,然后我们用复数的指数形式,设
\begin{equation}\begin{aligned}
\boldsymbol{f}(\boldsymbol{q}, m) =&\, R_f (\boldsymbol{q}, m)e^{\text{i}\Theta_f(\boldsymbol{q}, m)} \\
\boldsymbol{f}(\boldsymbol{k}, n) =&\, R_f (\boldsymbol{k}, n)e^{\text{i}\Theta_f(\boldsymbol{k}, n)} \\
\boldsymbol{g}(\boldsymbol{q}, \boldsymbol{k}, m-n) =&\, R_g (\boldsymbol{q}, \boldsymbol{k}, m-n)e^{\text{i}\Theta_g(\boldsymbol{q}, \boldsymbol{k}, m-n)} \\
\end{aligned}\end{equation}
那么代入方程后就得到方程组
\begin{equation}\begin{aligned}
R_f (\boldsymbol{q}, m) R_f (\boldsymbol{k}, n) =&\, R_g (\boldsymbol{q}, \boldsymbol{k}, m-n) \\
\Theta_f (\boldsymbol{q}, m) - \Theta_f (\boldsymbol{k}, n) =&\, \Theta_g (\boldsymbol{q}, \boldsymbol{k}, m-n)
\end{aligned}\end{equation}
对于第一个方程,代入$m=n$得到
\begin{equation}R_f (\boldsymbol{q}, m) R_f (\boldsymbol{k}, m) = R_g (\boldsymbol{q}, \boldsymbol{k}, 0) = R_f (\boldsymbol{q}, 0) R_f (\boldsymbol{k}, 0) = \Vert \boldsymbol{q}\Vert \Vert \boldsymbol{k}\Vert\end{equation}
最后一个等号源于初始条件$\boldsymbol{f}(\boldsymbol{q}, 0)=\boldsymbol{q}$和$\boldsymbol{f}(\boldsymbol{k}, 0)=\boldsymbol{k}$。所以现在我们可以很简单地设$R_f (\boldsymbol{q}, m)=\Vert \boldsymbol{q}\Vert, R_f (\boldsymbol{k}, m)=\Vert \boldsymbol{k}\Vert$,即它不依赖于$m$。至于第二个方程,同样代入$m=n$得到
\begin{equation}\Theta_f (\boldsymbol{q}, m) - \Theta_f (\boldsymbol{k}, m) = \Theta_g (\boldsymbol{q}, \boldsymbol{k}, 0) = \Theta_f (\boldsymbol{q}, 0) - \Theta_f (\boldsymbol{k}, 0) = \Theta (\boldsymbol{q}) - \Theta (\boldsymbol{k})\end{equation}
这里的$\Theta (\boldsymbol{q}),\Theta (\boldsymbol{k})$是$\boldsymbol{q},\boldsymbol{k}$本身的幅角,最后一个等号同样源于初始条件。根据上式得到$\Theta_f (\boldsymbol{q}, m) - \Theta (\boldsymbol{q}) = \Theta_f (\boldsymbol{k}, m) - \Theta (\boldsymbol{k})$,所以$\Theta_f (\boldsymbol{q}, m) - \Theta (\boldsymbol{q})$应该是一个只与$m$相关、跟$\boldsymbol{q}$无关的函数,记为$\varphi(m)$,即$\Theta_f (\boldsymbol{q}, m) = \Theta (\boldsymbol{q}) + \varphi(m)$。接着代入$n=m-1$,整理得到
\begin{equation}\varphi(m) - \varphi(m-1) = \Theta_g (\boldsymbol{q}, \boldsymbol{k}, 1) + \Theta (\boldsymbol{k}) - \Theta (\boldsymbol{q})\end{equation}
即$\{\varphi(m)\}$是等差数列,设右端为$\theta$,那么就解得$\varphi(m)=m\theta$。
编码形式 #
综上,我们得到二维情况下用复数表示的RoPE:
\begin{equation}
\boldsymbol{f}(\boldsymbol{q}, m) = R_f (\boldsymbol{q}, m)e^{\text{i}\Theta_f(\boldsymbol{q}, m)}
= \Vert q\Vert e^{\text{i}(\Theta(\boldsymbol{q}) + m\theta)} = \boldsymbol{q} e^{\text{i}m\theta}\end{equation}
根据复数乘法的几何意义,该变换实际上对应着向量的旋转,所以我们称之为“旋转式位置编码”,它还可以写成矩阵形式:
\begin{equation}
\boldsymbol{f}(\boldsymbol{q}, m) =\begin{pmatrix}\cos m\theta & -\sin m\theta\\ \sin m\theta & \cos m\theta\end{pmatrix} \begin{pmatrix}q_0 \\ q_1\end{pmatrix}\end{equation}
由于内积满足线性叠加性,因此任意偶数维的RoPE,我们都可以表示为二维情形的拼接,即
\begin{equation}\scriptsize{\underbrace{\begin{pmatrix}
\cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
\sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\
0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\
0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2-1} & -\sin m\theta_{d/2-1} \\
0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2-1} & \cos m\theta_{d/2-1} \\
\end{pmatrix}}_{\boldsymbol{\mathcal{R}}_m} \begin{pmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}\end{pmatrix}}\end{equation}
也就是说,给位置为$m$的向量$\boldsymbol{q}$乘上矩阵$\boldsymbol{\mathcal{R}}_m$、位置为$n$的向量$\boldsymbol{k}$乘上矩阵$\boldsymbol{\mathcal{R}}_n$,用变换后的$\boldsymbol{Q},\boldsymbol{K}$序列做Attention,那么Attention就自动包含相对位置信息了,因为成立恒等式:
\begin{equation}(\boldsymbol{\mathcal{R}}_m \boldsymbol{q})^{\top}(\boldsymbol{\mathcal{R}}_n \boldsymbol{k}) = \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n \boldsymbol{k} = \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k}\end{equation}
值得指出的是,$\boldsymbol{\mathcal{R}}_m$是一个正交矩阵,它不会改变向量的模长,因此通常来说它不会改变原模型的稳定性。
由于$\boldsymbol{\mathcal{R}}_m$的稀疏性,所以直接用矩阵乘法来实现会很浪费算力,推荐通过下述方式来实现RoPE:
\begin{equation}\begin{pmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}
\end{pmatrix}\otimes\begin{pmatrix}\cos m\theta_0 \\ \cos m\theta_0 \\ \cos m\theta_1 \\ \cos m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_{d/2-1}
\end{pmatrix} + \begin{pmatrix}-q_1 \\ q_0 \\ -q_3 \\ q_2 \\ \vdots \\ -q_{d-1} \\ q_{d-2}
\end{pmatrix}\otimes\begin{pmatrix}\sin m\theta_0 \\ \sin m\theta_0 \\ \sin m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_{d/2-1}
\end{pmatrix}\end{equation}
其中$\otimes$是逐位对应相乘,即Numpy、Tensorflow等计算框架中的$*$运算。从这个实现也可以看到,RoPE可以视为是乘性位置编码的变体。
远程衰减 #
可以看到,RoPE形式上和Sinusoidal位置编码有点相似,只不过Sinusoidal位置编码是加性的,而RoPE可以视为乘性的。在$\theta_i$的选择上,我们同样沿用了Sinusoidal位置编码的方案,即$\theta_i = 10000^{-2i/d}$,它可以带来一定的远程衰减性。
具体证明如下:将$\boldsymbol{q},\boldsymbol{k}$两两分组后,它们加上RoPE后的内积可以用复数乘法表示为
\begin{equation}
(\boldsymbol{\mathcal{R}}_m \boldsymbol{q})^{\top}(\boldsymbol{\mathcal{R}}_n \boldsymbol{k}) = \text{Re}\left[\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i}\right]\end{equation}
记$h_i = \boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^*, S_j = \sum\limits_{i=0}^{j-1} e^{\text{i}(m-n)\theta_i}$,并约定$h_{d/2}=0,S_0=0$,那么由Abel变换(分部求和法)可以得到:
\begin{equation}\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i} = \sum_{i=0}^{d/2-1} h_i (S_{i
+1} - S_i) = -\sum_{i=0}^{d/2-1} S_{i+1}(h_{i+1} - h_i)\end{equation}
所以
\begin{equation}\begin{aligned}
\left|\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i}\right| =&\, \left|\sum_{i=0}^{d/2-1} S_{i+1}(h_{i+1} - h_i)\right| \\
\leq&\, \sum_{i=0}^{d/2-1} |S_{i+1}| |h_{i+1} - h_i| \\
\leq&\, \left(\max_i |h_{i+1} - h_i|\right)\sum_{i=0}^{d/2-1} |S_{i+1}|
\end{aligned}\end{equation}
因此我们可以考察$\frac{1}{d/2}\sum\limits_{i=1}^{d/2} |S_i|$随着相对距离的变化情况来作为衰减性的体现,Mathematica代码如下:
d = 128;
\[Theta][t_] = 10000^(-2*t/d);
f[m_] = Sum[
Norm[Sum[Exp[I*m*\[Theta][i]], {i, 0, j}]], {j, 0, d/2 - 1}]/(d/2);
Plot[f[m], {m, 0, 256}, AxesLabel -> {相对距离, 相对大小}]结果如下图:
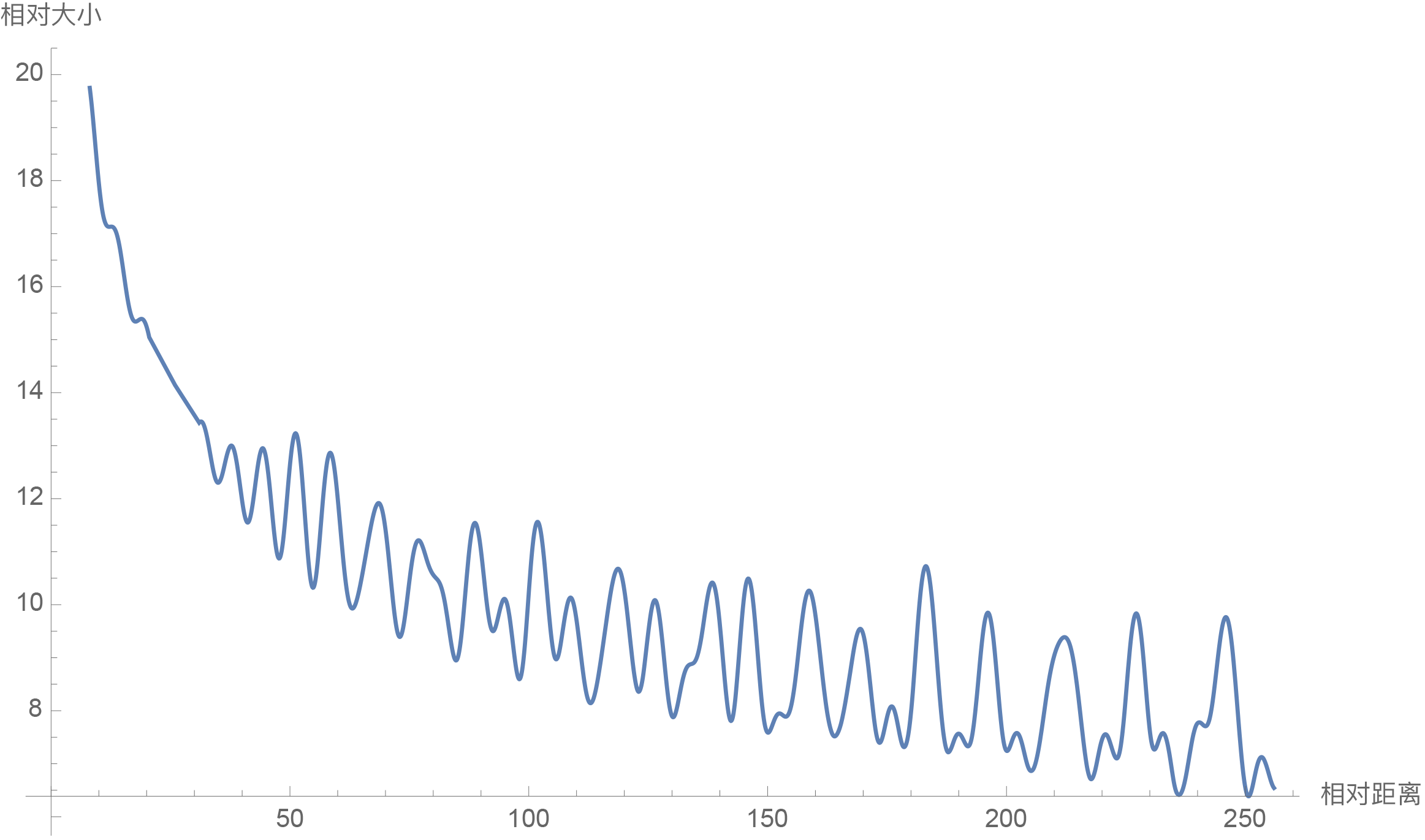
RoPE的远程衰减性(d=128)
从图中我们可以可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择$\theta_i = 10000^{-2i/d}$,确实能带来一定的远程衰减性。当然,同上一篇文章说的一样,能带来远程衰减性的不止这个选择,几乎任意的光滑单调函数都可以,这里只是沿用了已有的选择而已。笔者还试过以$\theta_i = 10000^{-2i/d}$为初始化,将$\theta_i$视为可训练参数,然后训练一段时间后发现$\theta_i$并没有显著更新,因此干脆就直接固定$\theta_i = 10000^{-2i/d}$了。
线性场景 #
最后,我们指出,RoPE是目前唯一一种可以用于线性Attention的相对位置编码。这是因为其他的相对位置编码,都是直接基于Attention矩阵进行操作的,但是线性Attention并没有事先算出Attention矩阵,因此也就不存在操作Attention矩阵的做法,所以其他的方案无法应用到线性Attention中。而对于RoPE来说,它是用绝对位置编码的方式来实现相对位置编码,不需要操作Attention矩阵,因此有了应用到线性Attention的可能性。
关于线性Attention的介绍,这里不再重复,有需要的读者请参考《线性Attention的探索:Attention必须有个Softmax吗?》。线性Attention的常见形式是:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
其中$\phi,\varphi$是值域非负的激活函数。可以看到,线性Attention也是基于内积的,所以很自然的想法是可以将RoPE插入到内积中:
\begin{equation}\frac{\sum\limits_{j=1}^n [\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]\boldsymbol{v}_j}{\sum\limits_{j=1}^n [\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]}\end{equation}
但这样存在的问题是,内积$[\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]$可能为负数,因此它不再是常规的概率注意力,而且分母有为0的风险,可能会带来优化上的不稳定。考虑到$\boldsymbol{\mathcal{R}}_i,\boldsymbol{\mathcal{R}}_j$都是正交矩阵,它不改变向量的模长,因此我们可以抛弃常规的概率归一化要求,使用如下运算作为一种新的线性Attention:
\begin{equation}\frac{\sum\limits_{j=1}^n [\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
也就是说,RoPE只插入分子中,而分母则不改变,这样的注意力不再是基于概率的(注意力矩阵不再满足非负归一性),但它某种意义上来说也是一个归一化方案,而且也没有证据表明非概率式的注意力就不好(比如Nyströmformer也算是没有严格依据概率分布的方式构建注意力),所以我们将它作为候选方案之一进行实验,而我们初步的实验结果显示这样的线性Attention也是有效的。
此外,笔者在《线性Attention的探索:Attention必须有个Softmax吗?》中还提出过另外一种线性Attention方案:$\text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j) = 1 + \left( \frac{\boldsymbol{q}_i}{\Vert \boldsymbol{q}_i\Vert}\right)^{\top}\left(\frac{\boldsymbol{k}_j}{\Vert \boldsymbol{k}_j\Vert}\right)$,它不依赖于值域的非负性,而RoPE也不改变模长,因此RoPE可以直接应用于此类线性Attention,并且不改变它的概率意义。
模型开源 #
RoFormer的第一版模型,我们已经完成训练并开源到了Github中:
简单来说,RoFormer是一个绝对位置编码替换为RoPE的WoBERT模型,它跟其他模型的结构对比如下:
\begin{array}{c|cccc}
\hline
& \text{BERT} & \text{WoBERT} & \text{NEZHA} & \text{RoFormer} \\
\hline
\text{token单位} & \text{字} & \text{词} & \text{字} & \text{词} & \\
\text{位置编码} & \text{绝对位置} & \text{绝对位置} & \text{经典式相对位置} & \text{RoPE}\\
\hline
\end{array}
在预训练上,我们以WoBERT Plus为基础,采用了多个长度和batch size交替训练的方式,让模型能提前适应不同的训练场景:
\begin{array}{c|ccccc}
\hline
& \text{maxlen} & \text{batch size} & \text{训练步数} & \text{最终loss} & \text{最终acc}\\
\hline
1 & 512 & 256 & 20\text{万} & 1.73 & 65.0\%\\
2 & 1536 & 256 & 1.25\text{万} & 1.61 & 66.8\%\\
3 & 256 & 256 & 12\text{万} & 1.75 & 64.6\%\\
4 & 128 & 512 & 8\text{万} & 1.83 & 63.4\%\\
5 & 1536 & 256 & 1\text{万} & 1.58 & 67.4\%\\
6 & 512 & 512 & 3\text{万} & 1.66 & 66.2\%\\
\hline
\end{array}
从表格还可以看到,增大序列长度,预训练的准确率反而有所提升,这侧面体现了RoFormer长文本语义的处理效果,也体现了RoPE具有良好的外推能力。在短文本任务上,RoFormer与WoBERT的表现类似,RoFormer的主要特点是可以直接处理任意长的文本。下面是我们在CAIL2019-SCM任务上的实验结果:
\begin{array}{c|cc}
\hline
& \text{验证集} & \text{测试集} \\
\hline
\text{BERT-512} & 64.13\% & 67.77\% \\
\text{WoBERT-512} & 64.07\% & 68.10\% \\
\text{RoFormer-512} & 64.13\% & 68.29\% \\
\text{RoFormer-1024} & \textbf{66.07%} & \textbf{69.79%} \\
\hline
\end{array}
其中$\text{-}$后面的参数是微调时截断的maxlen,可以看到RoFormer确实能较好地处理长文本语义,至于设备要求,在24G显存的卡上跑maxlen=1024,batch_size可以跑到8以上。目前中文任务中笔者也就找到这个任务比较适合作为长文本能力的测试,所以长文本方面只测了这个任务,欢迎读者进行测试或推荐其他评测任务。
当然,尽管理论上RoFormer能处理任意长度的序列,但目前RoFormer还是具有平方复杂度的,我们也正在训练基于线性Attention的RoFormer模型,实验完成后也会开源放出,请大家期待。
(注:RoPE和RoFormer已经整理成文《RoFormer: Enhanced Transformer with Rotary Position Embedding》提交到了Arxiv,欢迎使用和引用哈哈~)
文章小结 #
本文介绍了我们自研的旋转式位置编码RoPE以及对应的预训练模型RoFormer。从理论上来看,RoPE与Sinusoidal位置编码有些相通之处,但RoPE不依赖于泰勒展开,更具严谨性与可解释性;从预训练模型RoFormer的结果来看,RoPE具有良好的外推性,应用到Transformer中体现出较好的处理长文本的能力。此外,RoPE还是目前唯一一种可用于线性Attention的相对位置编码。
转载到请包括本文地址:https://spaces.ac.cn/archives/8265
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 23, 2021). 《Transformer升级之路:2、博采众长的旋转式位置编码 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8265
@online{kexuefm-8265,
title={Transformer升级之路:2、博采众长的旋转式位置编码},
author={苏剑林},
year={2021},
month={Mar},
url={\url{https://spaces.ac.cn/archives/8265}},
}

March 23rd, 2021
苏神您好~请问(5)(6)两式中第二个等号是怎么成立的呢?
$$ R_g(\pmb{q}, \pmb{k}, 0) = R_f(\pmb{q}, 0) R_f(\pmb{k}, 0) $$
$$ \Theta_g(\pmb{q}, \pmb{k}, 0) = \Theta_f(\pmb{q}, 0) - \Theta_f(\pmb{k}, 0) $$
不好意思(6)(7)两式
代入$m=n=0$不就得到了吗?
令$m=n$,有$R_f(\pmb{q}, m) R_f(\pmb{k}, m) = R_g(\pmb{q}, \pmb{k}, 0)$,但是不能得到$m=n=0$,也就是下一个等号成立吧?
令$m=n$,得到$R_f (\boldsymbol{q}, m) R_f (\boldsymbol{k}, m) = R_g (\boldsymbol{q}, \boldsymbol{k}, 0)$,又令$m=n=0$,得到$R_g (\boldsymbol{q}, \boldsymbol{k}, 0) = R_f (\boldsymbol{q}, 0) R_f (\boldsymbol{k}, 0)$,这些都是恒等式,它们的成立不依赖于$m=n$以及$m=n=0$,只是我们通过$m=n$以及$m=n=0$推导出它们来。所以
$$R_f (\boldsymbol{q}, m) R_f (\boldsymbol{k}, m) = R_g (\boldsymbol{q}, \boldsymbol{k}, 0) = R_f (\boldsymbol{q}, 0) R_f (\boldsymbol{k}, 0)$$
好的感谢苏神的详细回复!~~
或者(6)式前直接令$m = n = 0$
March 24th, 2021
这是一种配合Attention机制能达到“绝对位置编码的方式实现绝对位置编码”的设计应该是“绝对位置编码的方式实现相对位置编码”吧
哎呀,是的,谢谢指出,已修正
March 25th, 2021
但是看roformer实现的时候,还是用SinusoidalPositionEmbedding。并没有像(13)那样实现的?
bert4keras的roformer实现,就是用$(13)$式的,SinusoidalPositionEmbedding只负责返回$(13)$式的第2、4个向量,具体运算在MultiHeadAttention中,这是因为RoPE必须在Q、K执行,也就是说输入x传到MultiHeadAttention后,经过三个全连接层变成Q、K、V,必须在这一步后执行,不能直接在x执行,否则就不等价于相对位置编码了。
March 25th, 2021
苏神,公式(15)是不是最后结果少了个负号呀
对对,写糊涂了,已经修正,谢谢指出~
March 25th, 2021
有个疑问,想请教一下。$\varphi(m)=m\theta$的推导过程中,在$(8)$式里,$\theta$应该是与$q,k$相关的一个值,这里是进行了一部简化么。请问是否尝试过将$m\theta$设置为一个与$q,k,m$有关的可学习参数进行学习呢。
首先在上一步我们已经得出$\Theta_f (\boldsymbol{q}, m) = \Theta (\boldsymbol{q}) + \varphi(m)$,这里的$\varphi(m)$就是跟$\boldsymbol{q},\boldsymbol{k}$无关的,所以既然$(8)$式又成立,所以$(8)$式右端一定跟$\boldsymbol{q},\boldsymbol{k}$无关的,换句话说,$\Theta_g (\boldsymbol{q}, \boldsymbol{k}, 1)$一定是$\text{常数} - \Theta (\boldsymbol{k}) + \Theta (\boldsymbol{q})$的形式。
哦哦,明白了。谢谢苏神的耐心解答!
April 17th, 2021
你好!
我们是EleutherAI的独立研究者。我们看你的RoPE博客觉得很巧妙,而我们做过了一系列的实验,发现确实结果特别好。因此,我们现在正在写我们自己的博客,为了给说英语的研究者介绍这个概念和我们的实验结果。我们想确保正确的归功于你。你希望我们怎么引用你的博客?而且,你有没有计划任何关于RoPE的论文?我们不想跟你的论文有任何冲突。
多谢
你好,很荣幸能得到你们的关注和测试,尤其是“特别好”这个结果让我相当惊喜,也特别期待你们的博客。关于RoFormer和RoPE的英文论文,我们仍然在撰写中,估计还需要一两个星期才能提交到arxiv。如果你们的博文中需要引用,欢迎直接引用本博客链接,并简单注释一下paper coming soon之类的,格式可以参考 https://kexue.fm/archives/8265/comment-page-1#how_to_cite 并将中文部分简单翻译为英文。
再次感谢!
May 11th, 2021
苏老师你好,RoPE在模型加入一个CLS token做语义分类时该怎么处理?CLS应该是一个全局的token,它应该是放在任意位置上都不应该影响其提取结果的,若是按照RoPE的方式的话,好像就必须先有一固定的位置,这样的话不同的CLS位置好像就会不一样吧
不理解你的“若是按照RoPE的方式的话,好像就必须先有一固定的位置”这句话。
在我们的实验里,RoFormer直接取cls跟BERT取cls没什么区别。
May 11th, 2021
原理上,是把sinusoidal位置编码从相加式,改为相乘式,因为求 attention 毕竟是 q * k 的内积操作,相加式就会面临多项式的展开,相对位置信息分散在多项上的问题;直接改为相乘式,则显得更加直接。
直观上是可以这么理解,但是细节上来说,单纯加改乘还不足以达到“用相对位置信息表达绝对位置信息”的效果。
是的,细节的实现比sinusoidal做了很大的改进,分组复数乘融合位置信息 ,看完二维的RoPE,感觉数学知识有点跟不上了,目的单纯的“用相对位置信息表达绝对位置信息”,居然会涉及到各向同异性这么听起来很有道理,但是自己想估计怎么都无法脑补出来的性质。
写完二维RoPE后,我再思考了一下,感觉各向同性才是本质。简单来说,“正交性”、“可逆性”、“各向同性”三者就可以推出RoPE,“相对性”只是附加的。这样放弃了“用相对位置信息表达绝对位置信息”的出发点,那么我们就可以考虑把位置编码加在任意地方(比如输入端),而不单单是Q、K上。
May 14th, 2021
\begin{equation}\begin{aligned}
\Theta_f (\boldsymbol{q}, m) - \Theta_f (\boldsymbol{k}, n) =&\, \Theta_g (\boldsymbol{q}, \boldsymbol{k}, m-n)
\end{aligned}\end{equation}
苏神,请问一下(5)式的减号是怎么计算得到?辐角不应该是相加么
还有个共轭,取共轭后幅角变号
好的好的,谢谢苏神的解答
June 6th, 2021
请问加了这个编码和普通的训练式编码,效果上有哪些改进?我在做timesformer实验时修改编码,跑出来的结果数据没有丝毫变化,但训练时间缩短了一半,这个算是提升的效果吗?
没有丝毫变化不至于吧,随机波动都有呀~
加速收敛也是RoPE的一个明显作用,某些任务下则会有提升。
苏老师想问下您哈 为什么说会有加速收敛的作用呢
实验显示。