






22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 53525位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。
8
Nov
模型优化漫谈:BERT的初始标准差为什么是0.02?
By 苏剑林 | 2021-11-08 | 69695位读者 | 引用前几天在群里大家讨论到了“Transformer如何解决梯度消失”这个问题,答案有提到残差的,也有提到LN(Layer Norm)的。这些是否都是正确答案呢?事实上这是一个非常有趣而综合的问题,它其实关联到挺多模型细节,比如“BERT为什么要warmup?”、“BERT的初始化标准差为什么是0.02?”、“BERT做MLM预测之前为什么还要多加一层Dense?”,等等。本文就来集中讨论一下这些问题。
梯度消失说的是什么意思?
在文章《也来谈谈RNN的梯度消失/爆炸问题》中,我们曾讨论过RNN的梯度消失问题。事实上,一般模型的梯度消失现象也是类似,它指的是(主要是在模型的初始阶段)越靠近输入的层梯度越小,趋于零甚至等于零,而我们主要用的是基于梯度的优化器,所以梯度消失意味着我们没有很好的信号去调整优化前面的层。
18
Oct
初始化方法中非方阵的维度平均策略思考
By 苏剑林 | 2021-10-18 | 27108位读者 | 引用在《从几何视角来理解模型参数的初始化策略》、《浅谈Transformer的初始化、参数化与标准化》等文章,我们讨论过模型的初始化方法,大致的思路是:如果一个$n\times n$的方阵用均值为0、方差为$1/n$的独立同分布初始化,那么近似于一个正交矩阵,使得数据二阶矩(或方差)在传播过程中大致保持不变。
那如果是$m\times n$的非方阵呢?常见的思路(Xavier初始化)是综合考虑前向传播和反向传播,所以使用均值为0、方差为$2/(m+n)$的独立同分布初始化。但这个平均更多是“拍脑袋”的,本文就来探究一下有没有更好的平均方案。
基础回顾
Xavier初始化是考虑如下的全连接层(设输入节点数为$m$,输出节点数为$n$)
\begin{equation} y_j = b_j + \sum_i x_i w_{i,j}\end{equation}
24
Aug
隐藏在动量中的梯度累积:少更新几步,效果反而更好?
By 苏剑林 | 2021-08-24 | 27675位读者 | 引用我们知道,梯度累积是在有限显存下实现大batch_size训练的常用技巧。在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们就简单介绍过梯度累积的实现,大致的思路是新增一组参数来缓存梯度,最后用缓存的梯度来更新模型。美中不足的是,新增一组参数会带来额外的显存占用。
这几天笔者在思考优化器的时候,突然意识到:梯度累积其实可以内置在带动量的优化器中!带着这个思路,笔者对优化了进行了一些推导和实验,最后还得到一个有意思但又有点反直觉的结论:少更新几步参数,模型最终效果可能会变好!
注:本文下面的结果,几乎原封不动且没有引用地出现在Google的论文《Combined Scaling for Zero-shot Transfer Learning》中,在此不做过多评价,请读者自行品评。
SGDM
在正式讨论之前,我们定义函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
也就是说,$t$是一个整数,当它是$k$的倍数时,$\chi_{t/k}=1$,否则$\chi_{t/k}=0$,这其实就是一个$t$能否被$k$整除的示性函数。在后面的讨论中,我们将反复用到这个函数。
17
Aug
浅谈Transformer的初始化、参数化与标准化
By 苏剑林 | 2021-08-17 | 123462位读者 | 引用前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候$\boldsymbol{Q}\boldsymbol{K}^{\top}$之后忘记除以$\sqrt{d}$了,于是重新温习了一下为什么除以$\sqrt{d}$如此重要的原因。当然,Google的T5确实是没有除以$\sqrt{d}$的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。
藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。
采样分布
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。
17
Jun
对比学习可以使用梯度累积吗?
By 苏剑林 | 2021-06-17 | 42426位读者 | 引用在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们介绍过“梯度累积”,它是在有限显存下实现大batch_size效果的一种技巧。一般来说,梯度累积适用的是loss是独立同分布的场景,换言之每个样本单独计算loss,然后总loss是所有单个loss的平均或求和。然而,并不是所有任务都满足这个条件的,比如最近比较热门的对比学习,每个样本的loss还跟其他样本有关。
那么,在对比学习场景,我们还可以使用梯度累积来达到大batch_size的效果吗?本文就来分析这个问题。
简介
一般情况下,对比学习的loss可以写为
\begin{equation}\mathcal{L}=-\sum_{i,j=1}^b t_{i,j}\log p_{i,j} = -\sum_{i,j=1}^b t_{i,j}\log \frac{e^{s_{i,j}}}{\sum\limits_j e^{s_{i,j}}}=-\sum_{i,j=1}^b t_{i,j}s_{i,j} + \sum_{i=1}^b \log\sum_{j=1}^b e^{s_{i,j}}\label{eq:loss}\end{equation}
这里的$b$是batch_size;$t_{i,j}$是事先给定的标签,满足$t_{i,j}=t_{j,i}$,它是一个one hot矩阵,每一列只有一个1,其余都为0;而$s_{i,j}$是样本$i$和样本$j$的相似度,满足$s_{i,j}=s_{j,i}$,一般情况下还有个温度参数,这里假设温度参数已经整合到$s_{i,j}$中,从而简化记号。模型参数存在于$s_{i,j}$中,假设为$\theta$。
24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 65809位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
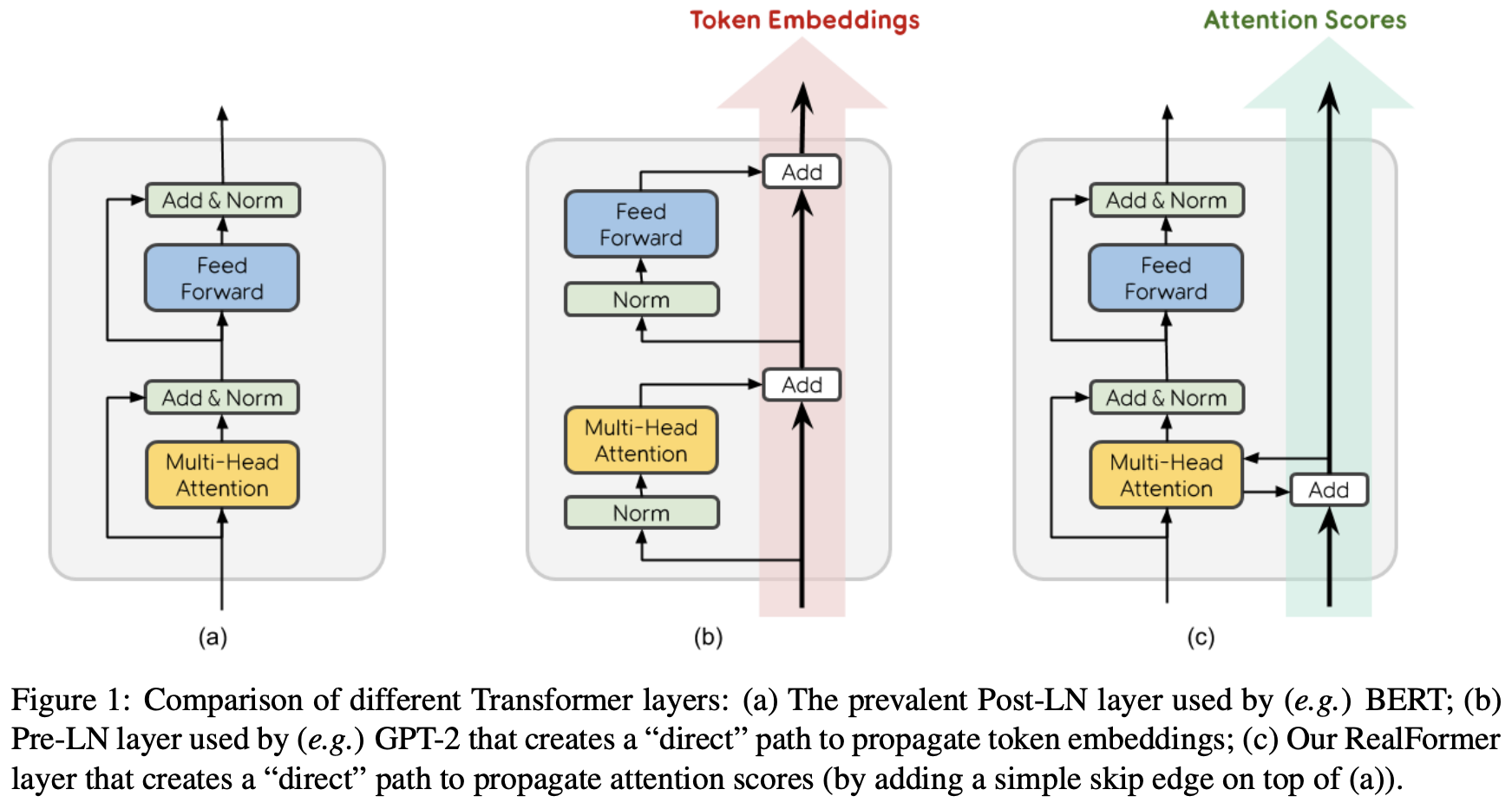
PostLN、PreLN和RealFormer结构示意图
13
Nov
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 71060位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
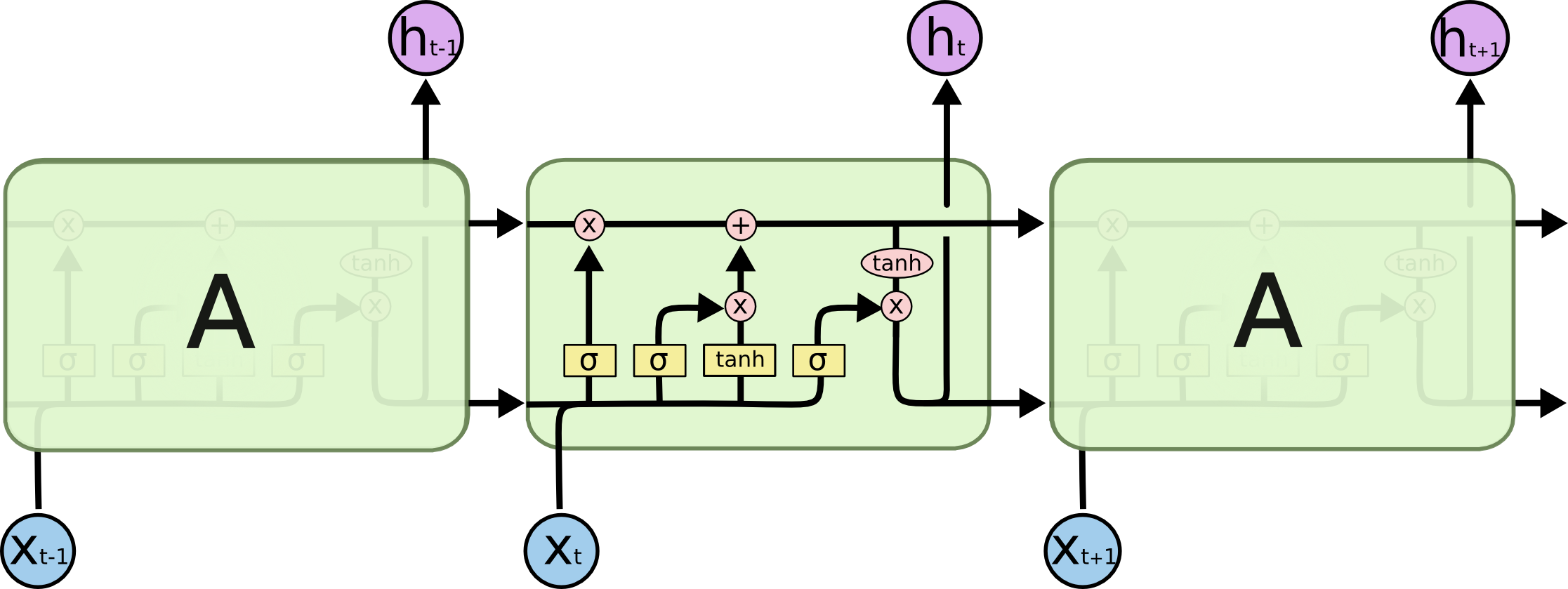
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。

最近评论