






6
Jun
通用爬虫探索(二):落实到论坛爬取上
By 苏剑林 | 2017-06-06 | 22225位读者 | 引用前述的方案,如果爬取的页面仅仅有单一的有效区域,如博客页、新闻页等,那么基本上来说已经足够了。但是,诸如像论坛这样的具有比较明显的层次划分的网站,我们需要进一步细分。因为经过上述步骤,我们虽然能够把有效文本提取出来,但结果是把所有文本放在一块了。
深度优先
而为了给内容进一步“分块”,我们还需要利用DOM树的位置信息。如上一篇的DOM树图,我们需要给每个节点和叶子都编号,即我们需要一个遍历DOM树的方式。这里我们采用“深度优先”的方案。
深度优先搜索算法(英语:Depth-First-Search,简称DFS)是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
7
Jun
通用爬虫探索(三):效果展示与代码
By 苏剑林 | 2017-06-07 | 46427位读者 | 引用
26
Oct
浅谈神经网络中激活函数的设计
By 苏剑林 | 2017-10-26 | 39810位读者 | 引用激活函数是神经网络中非线性的来源,因为如果去掉这些函数,那么整个网络就只剩下线性运算,线性运算的复合还是线性运算的,最终的效果只相当于单层的线性模型。
那么,常见的激活函数有哪些呢?或者说,激活函数的选择有哪些指导原则呢?是不是任意的非线性函数都可以做激活函数呢?
这里探究的激活函数是中间层的激活函数,而不是输出的激活函数。最后的输出一般会有特定的激活函数,不能随意改变,比如二分类一般用sigmoid函数激活,多分类一般用softmax激活,等等;相比之下,中间层的激活函数选择余地更大一些。
浮点误差都行!
理论上来说,只要是非线性函数,都有做激活函数的可能性,一个很有说服力的例子是,最近OpenAI成功地利用了浮点误差来做激活函数,其中的细节,请阅读OpenAI的博客:
https://blog.openai.com/nonlinear-computation-in-linear-networks/
或者阅读机器之心的介绍:
https://mp.weixin.qq.com/s/PBRzS4Ol_Zst35XKrEpxdw
19
Nov
更别致的词向量模型(一):simpler glove
By 苏剑林 | 2017-11-19 | 36750位读者 | 引用如果问我哪个是最方便、最好用的词向量模型,我觉得应该是word2vec,但如果问我哪个是最漂亮的词向量模型,我不知道,我觉得各个模型总有一些不足的地方。且不说试验效果好不好(这不过是评测指标的问题),就单看理论也没有一个模型称得上漂亮的。
本文讨论了一些大家比较关心的词向量的问题,很多结论基本上都是实验发现的,缺乏合理的解释,包括:
如果去构造一个词向量模型?
为什么用余弦值来做近义词搜索?向量的内积又是什么含义?
词向量的模长有什么特殊的含义?
为什么词向量具有词类比性质?(国王-男人+女人=女王)
得到词向量后怎么构建句向量?词向量求和作为简单的句向量的依据是什么?
这些讨论既有其针对性,也有它的一般性,有些解释也许可以直接迁移到对glove模型和skip gram模型的词向量性质的诠释中,读者可以自行尝试。
围绕着这些问题的讨论,本文提出了一个新的类似glove的词向量模型,这里称之为simpler glove,并基于斯坦福的glove源码进行修改,给出了本文的实现,具体代码在Github上。
19
Nov
更别致的词向量模型(六):代码、分享与结语
By 苏剑林 | 2017-11-19 | 81489位读者 | 引用
23
Jan
分享一个slide:花式自然语言处理
By 苏剑林 | 2018-01-23 | 71838位读者 | 引用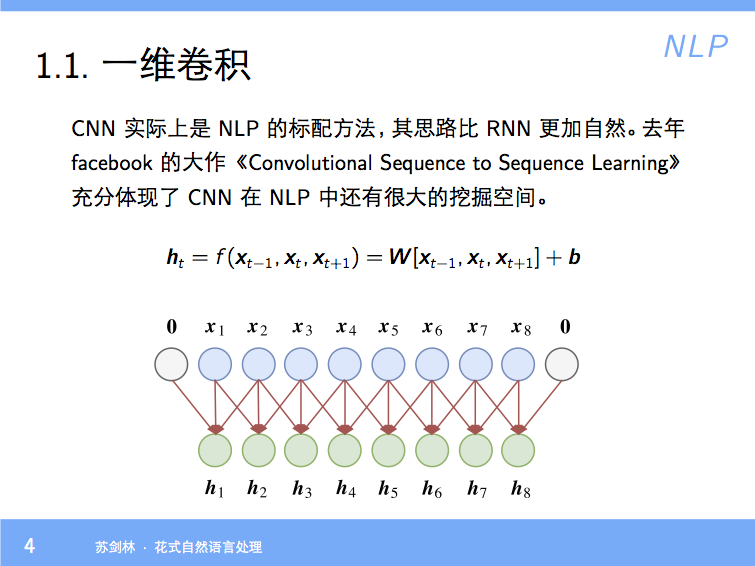
29
Jan
网站更新记录(2018年01月)
By 苏剑林 | 2018-01-29 | 25948位读者 | 引用也许读者会发现,这几天访问科学空间可能出现不稳定的情况,原因是我这几天都在对网站进行调整。
这次的调整幅度很大,不过从外表上可能很难发现,特此记录留念一下。主要的更新内容包括:
1、主题的优化:本博客用的geekg主题其实比较老了,去年花钱请人对它进行了第一次大升级,加入了响应式设计,这几天主要解决该主题的一些历史遗留问题,包括图片显示、边距、排版等细微调整;
2、内部的优化:大幅度减少了插件的使用,把一些基本的功能(如网站目录、归档页)等都内嵌到主题中,减少了对插件的依赖,也提升了可用性;
3、文章的优化:其实这也是个历史遗留问题,主要是早期写文章的时候比较随意,html代码、公式的LaTeX代码等都不规范,因此早期的文章显示效果可能比较糟糕,于是我就做了一件很疯狂的事情——把800多篇文章都过一遍!经过了两天多的时间,基本上修复了早期文章的大部分问题;
4、域名的优化:网站全面使用https!网站放在阿里云上面,可是阿里云有一套自以为是的监管系统,无故屏蔽我的一些页面。为了应对阿里云的恶意屏蔽,只好转向https,当然,这不会对读者平时访问造成影响,因为跳转https是自动的。目前两个域名spaces.ac.cn和kexue.fm都会自动跳转到https。
31
May
基于最小熵原理的NLP库:nlp zero
By 苏剑林 | 2018-05-31 | 86040位读者 | 引用陆陆续续写了几篇最小熵原理的博客,致力于无监督做NLP的一些基础工作。为了方便大家实验,把文章中涉及到的一些算法封装为一个库,供有需要的读者测试使用。
由于面向的是无监督NLP场景,而且基本都是NLP任务的基础工作,因此命名为nlp zero。
地址
Github: https://github.com/bojone/nlp-zero
Pypi: https://pypi.org/project/nlp-zero/
可以直接通过
pip install nlp-zero==0.1.6进行安装。整个库纯Python实现,没有第三方调用,支持Python2.x和3.x。

最近评论