






19
Nov
更别致的词向量模型(五):有趣的结果
By 苏剑林 | 2017-11-19 | 70986位读者 | 引用最后,我们来看一下词向量模型$(15)$会有什么好的性质,或者说,如此煞费苦心去构造一个新的词向量模型,会得到什么回报呢?
模长的含义
似乎所有的词向量模型中,都很少会关心词向量的模长。有趣的是,我们上述词向量模型得到的词向量,其模长还能在一定程度上代表着词的重要程度。我们可以从两个角度理解这个事实。
在一个窗口内的上下文,中心词重复出现概率其实是不大的,是一个比较随机的事件,因此可以粗略地认为
\[P(w,w) \sim P(w)\tag{24}\]
所以根据我们的模型,就有
\[e^{\langle\boldsymbol{v}_{w},\boldsymbol{v}_{w}\rangle} =\frac{P(w,w)}{P(w)P(w)}\sim \frac{1}{P(w)}\tag{25}\]
所以
\[\Vert\boldsymbol{v}_{w}\Vert^2 \sim -\log P(w)\tag{26}\]
可见,词语越高频(越有可能就是停用词、虚词等),对应的词向量模长就越小,这就表明了这种词向量的模长确实可以代表词的重要性。事实上,$-\log P(w)$这个量类似IDF,有个专门的名称叫ICF,请参考论文《TF-ICF: A New Term Weighting Scheme for Clustering Dynamic Data Streams》。
6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 719323位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 371517位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。
24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 106290位读者 | 引用前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
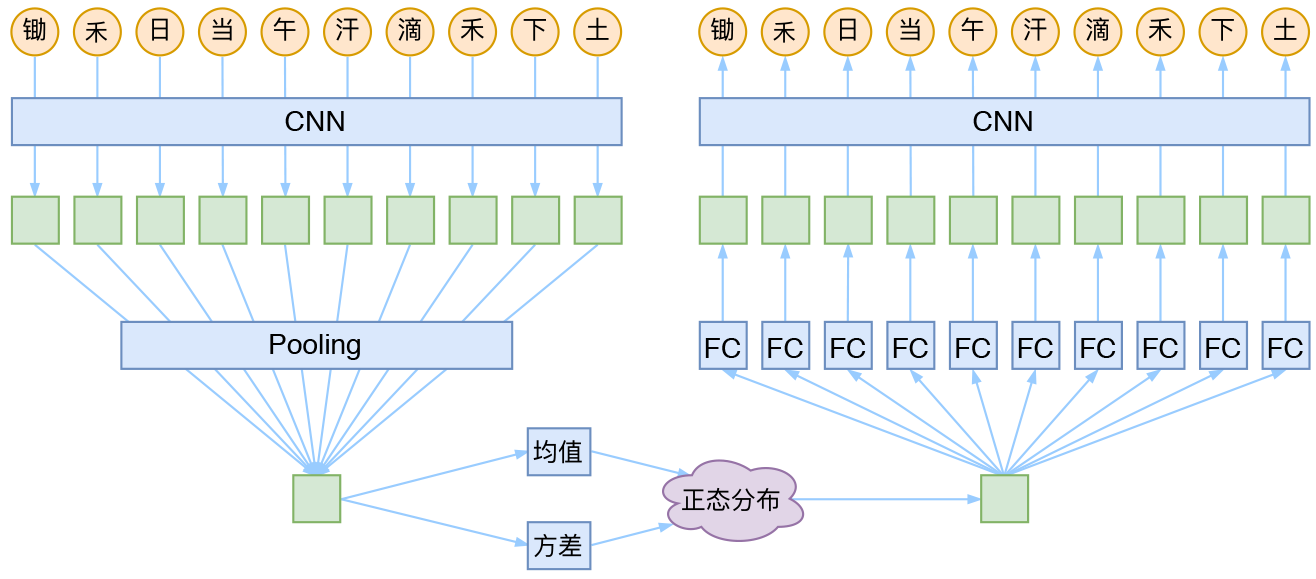
cnn + vae 诗歌生成模型
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 775680位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
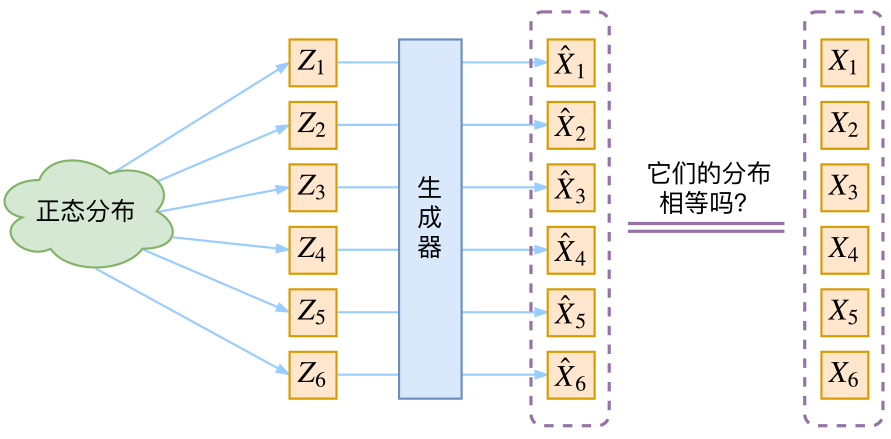
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 357854位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
23
Jun
貌离神合的RNN与ODE:花式RNN简介
By 苏剑林 | 2018-06-23 | 82526位读者 | 引用本来笔者已经决心不玩RNN了,但是在上个星期思考时忽然意识到RNN实际上对应了ODE(常微分方程)的数值解法,这为我一直以来想做的事情——用深度学习来解决一些纯数学问题——提供了思路。事实上这是一个颇为有趣和有用的结果,遂介绍一翻。顺便地,本文也涉及到了自己动手编写RNN的内容,所以本文也可以作为编写自定义的RNN层的一个简单教程。
注:本文并非前段时间的热点“神经ODE”的介绍(但有一定的联系)。
RNN基本
什么是RNN?
众所周知,RNN是“循环神经网络(Recurrent Neural Network)”,跟CNN不同,RNN可以说是一类模型的总称,而并非单个模型。简单来讲,只要是输入向量序列$(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_T)$,输出另外一个向量序列$(\boldsymbol{y}_1,\boldsymbol{y}_2,\dots,\boldsymbol{y}_T)$,并且满足如下递归关系
$$\boldsymbol{y}_t=f(\boldsymbol{y}_{t-1}, \boldsymbol{x}_t, t)\tag{1}$$
的模型,都可以称为RNN。也正因为如此,原始的朴素RNN,还有改进的如GRU、LSTM、SRU等模型,我们都称为RNN,因为它们都可以作为上式的一个特例。还有一些看上去与RNN没关的内容,比如前不久介绍的CRF的分母的计算,实际上也是一个简单的RNN。
说白了,RNN其实就是递归计算。
27
Jun
从动力学角度看优化算法(一):从SGD到动量加速
By 苏剑林 | 2018-06-27 | 124865位读者 | 引用在这个系列中,我们来关心优化算法,而本文的主题则是SGD(stochastic gradient descent,随机梯度下降),包括带Momentum和Nesterov版本的。对于SGD,我们通常会关心的几个问题是:
SGD为什么有效?
SGD的batch size是不是越大越好?
SGD的学习率怎么调?
Momentum是怎么加速的?
Nesterov为什么又比Momentum稍好?
...
这里试图从动力学角度分析SGD,给出上述问题的一些启发性理解。
梯度下降
既然要比较谁好谁差,就需要知道最好是什么样的,也就是说我们的终极目标是什么?
训练目标分析
假设全部训练样本的集合为$\boldsymbol{S}$,损失度量为$L(\boldsymbol{x};\boldsymbol{\theta})$,其中$\boldsymbol{x}$代表单个样本,而$\boldsymbol{\theta}$则是优化参数,那么我们可以构建损失函数
$$L(\boldsymbol{\theta}) = \frac{1}{|\boldsymbol{S}|}\sum_{\boldsymbol{x}\in\boldsymbol{S}} L(\boldsymbol{x};\boldsymbol{\theta})\tag{1}$$
而训练的终极目标,则是找到$L(\boldsymbol{\theta})$的一个全局最优点(这里的最优是“最小”的意思)。

最近评论