






8
Apr
生成扩散模型漫谈(二十二):信噪比与大图生成(上)
By 苏剑林 | 2024-04-08 | 44805位读者 | 引用盘点主流的图像扩散模型作品,我们会发现一个特点:当前多数做高分辨率图像生成(下面简称“大图生成”)的工作,都是先通过Encoder变换到Latent空间进行的(即LDM,Latent Diffusion Model),直接在原始Pixel空间训练的扩散模型,大多数分辨率都不超过64*64,而恰好,LDM通过AutoEncoder变换后的Latent,大小通常也不超过64*64。这就自然引出了一系列问题:扩散模型是不是对于高分辨率生成存在固有困难?能否在Pixel空间直接生成高分辨率图像?
论文《Simple diffusion: End-to-end diffusion for high resolution images》尝试回答了这个问题,它通过“信噪比”分析了大图生成的困难,并以此来优化noise schdule,同时提出只需在最低分辨率feature上对架构进行scale up、多尺度Loss等技巧来保证训练效率和效果,这些改动使得原论文成功在Pixel空间上训练了分辨率高达1024*1024的图像扩散模型。
29
Mar
Transformer升级之路:17、多模态位置编码的简单思考
By 苏剑林 | 2024-03-29 | 54941位读者 | 引用在这个系列的第二篇文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE)——通过绝对位置的形式实现相对位置编码的方案。一开始RoPE是针对一维序列如文本、音频等设计的(RoPE-1D),后来在《Transformer升级之路:4、二维位置的旋转式位置编码》中我们将它推广到了二维序列(RoPE-2D),这适用于图像的ViT。然而,不管是RoPE-1D还是RoPE-2D,它们的共同特点都是单一模态,即纯文本或者纯图像输入场景,那么对于多模态如图文混合输入场景,RoPE该做如何调整呢?
笔者搜了一下,发现鲜有工作讨论这个问题,主流的做法似乎都是直接展平所有输入,然后当作一维输入来应用RoPE-1D,因此连RoPE-2D都很少见。且不说这种做法会不会成为图像分辨率进一步提高时的效果瓶颈,它终究是显得不够优雅。所以,接下来我们试图探寻两者的一个自然结合。
旋转位置
RoPE名称中的“旋转”一词,来源于旋转矩阵$\boldsymbol{\mathcal{R}}_n=\begin{pmatrix}\cos n\theta & -\sin n\theta\\ \sin n\theta & \cos n\theta\end{pmatrix}$,它满足
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\end{equation}
17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 30471位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。
23
Apr
生成扩散模型漫谈(二十四):少走捷径,更快到达
By 苏剑林 | 2024-04-23 | 29872位读者 | 引用如何减少采样步数同时保证生成质量,是扩散模型应用层面的一个关键问题。其中,《生成扩散模型漫谈(四):DDIM = 高观点DDPM》介绍的DDIM可谓是加速采样的第一次尝试。后来,《生成扩散模型漫谈(五):一般框架之SDE篇》、《生成扩散模型漫谈(五):一般框架之ODE篇》等所介绍的工作将扩散模型与SDE、ODE联系了起来,于是相应的数值积分技术也被直接用于扩散模型的采样加速,其中又以相对简单的ODE加速技术最为丰富,我们在《生成扩散模型漫谈(二十一):中值定理加速ODE采样》也介绍过一例。
这篇文章我们介绍另一个特别简单有效的加速技巧——Skip Tuning,出自论文《The Surprising Effectiveness of Skip-Tuning in Diffusion Sampling》,准确来说它是配合已有的加速技巧使用,来一步提高采样质量,这就意味着在保持相同采样质量的情况下,它可以进一步压缩采样步数,从而实现加速。
5
Jun
重温SSM(二):HiPPO的一些遗留问题
By 苏剑林 | 2024-06-05 | 20886位读者 | 引用书接上文,在上一篇文章《重温SSM(一):线性系统和HiPPO矩阵》中,我们详细讨论了HiPPO逼近框架其HiPPO矩阵的推导,其原理是通过正交函数基来动态地逼近一个实时更新的函数,其投影系数的动力学正好是一个线性系统,而如果以正交多项式为基,那么线性系统的核心矩阵我们可以解析地求解出来,该矩阵就称为HiPPO矩阵。
当然,上一篇文章侧重于HiPPO矩阵的推导,并没有对它的性质做进一步分析,此外诸如“如何离散化以应用于实际数据”、“除了多项式基外其他基是否也可以解析求解”等问题也没有详细讨论到。接下来我们将补充探讨相关问题。
离散格式
假设读者已经阅读并理解上一篇文章的内容,那么这里我们就不再进行过多的铺垫。在上一篇文章中,我们推导出了两类线性ODE系统,分别是:
\begin{align}
&\text{HiPPO-LegT:}\quad x'(t) = Ax(t) + Bu(t) \label{eq:legt-ode}\\[5pt]
&\text{HiPPO-LegS:}\quad x'(t) = \frac{A}{t}x(t) + \frac{B}{t}u(t) \label{eq:legs-ode}\end{align}
其中$A,B$是与时间$t$无关的常数矩阵,HiPPO矩阵主要指矩阵$A$。在这一节中,我们讨论这两个ODE的离散化。
27
Jun
重温SSM(四):有理生成函数的新视角
By 苏剑林 | 2024-06-27 | 16888位读者 | 引用在前三篇文章中,我们较为详细地讨论了HiPPO和S4的大部分数学细节。那么,对于接下来的第四篇文章,大家预期我们会讨论什么工作呢?S5、Mamba乃至Mamba2?都不是。本系列文章主要关心SSM的数学基础,旨在了解SSM的同时也补充自己的数学能力。而在上一篇文章我们简单提过S5和Mamba,S5是S4的简化版,相比S4基本上没有引入新的数学技巧,而Mamba系列虽然表现优异,但它已经将$A$简化为对角矩阵,所用到的数学技巧就更少了,它更多的是体现了工程方面的能力。
这篇文章我们来学习一篇暂时还声名不显的新工作《State-Free Inference of State-Space Models: The Transfer Function Approach》(简称RFT),它提出了一个新方案,将SSM的训练、推理乃至参数化,都彻底转到了生成函数空间中,为SSM的理解和应用开辟了新的视角
基础回顾
首先我们简单回顾一下上一篇文章关于S4的探讨结果。S4基于如下线性RNN
\begin{equation}\begin{aligned}
x_{k+1} =&\, \bar{A} x_k + \bar{B} u_k \\
y_{k+1} =&\, \bar{C}^* x_{k+1} \\
\end{aligned}\label{eq:linear}\end{equation}
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 45988位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 22189位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
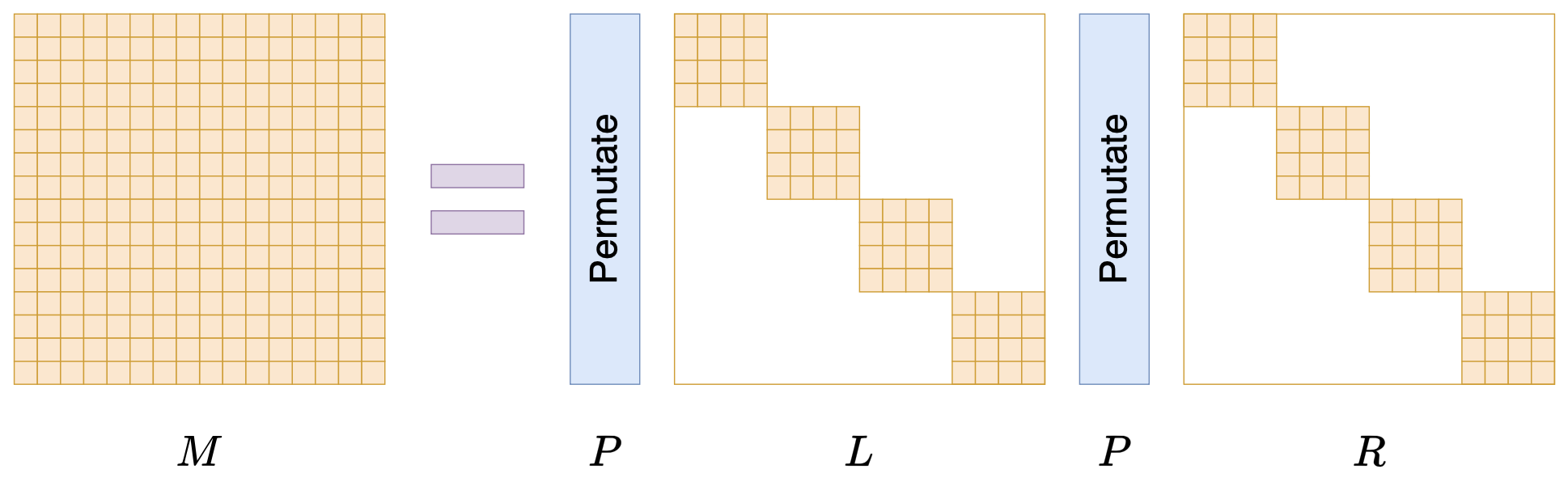
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。

最近评论