






25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 175649位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
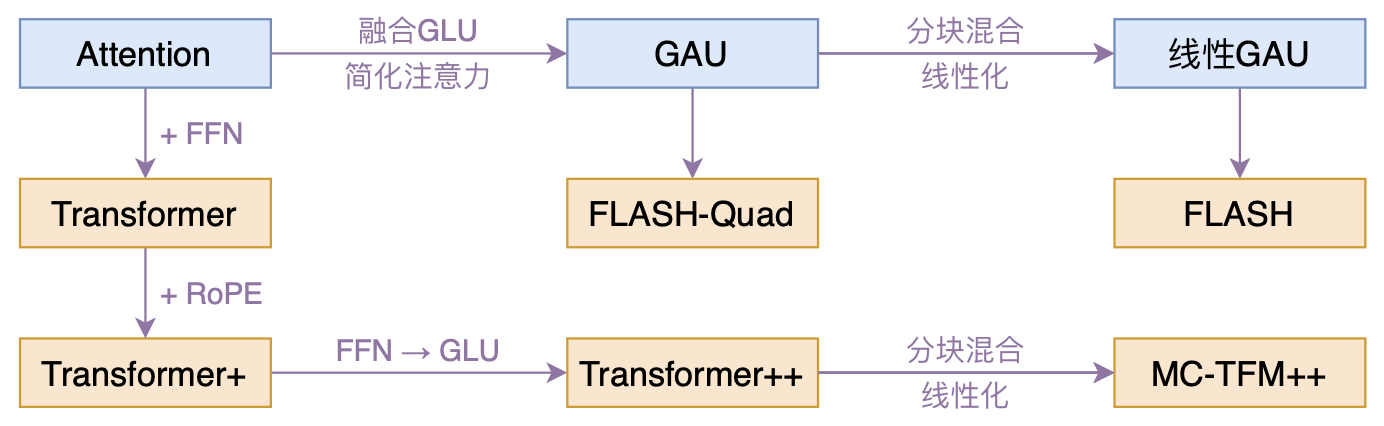
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 75017位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 57918位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 26244位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。
29
Mar
为什么Pre Norm的效果不如Post Norm?
By 苏剑林 | 2022-03-29 | 92966位读者 | 引用Pre Norm与Post Norm之间的对比是一个“老生常谈”的话题了,本博客就多次讨论过这个问题,比如文章《浅谈Transformer的初始化、参数化与标准化》、《模型优化漫谈:BERT的初始标准差为什么是0.02?》等。目前比较明确的结论是:同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。Pre Norm更容易训练好理解,因为它的恒等路径更突出,但为什么它效果反而没那么好呢?
笔者之前也一直没有好的答案,直到前些时间在知乎上看到 @唐翔昊 的一个回复后才“恍然大悟”,原来这个问题竟然有一个非常直观的理解!本文让我们一起来学习一下。
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 73075位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
7
Jun
相对位置编码Transformer的一个理论缺陷与对策
By 苏剑林 | 2022-06-07 | 92624位读者 | 引用位置编码是Transformer中很重要的一环,在《让研究人员绞尽脑汁的Transformer位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将Transformer的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多NLP/CV的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在Softmax之前的Attention矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得Transformer无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。
简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射 \begin{equation}\begin{array}{lc} \text{输入:} & [0, 0, \cdots, 0, 0] \\ & \downarrow\\ \text{输出:} & [1, 2, \cdots, n-1, n] \end{array}\end{equation}
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 67373位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。

最近评论