






29
Jul
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 332688位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
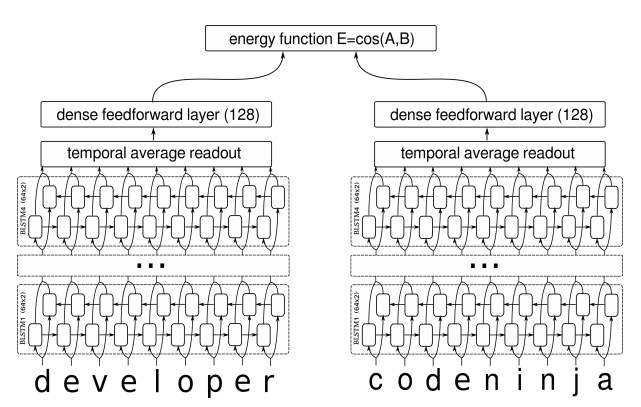
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
7
Jul
从SamplePairing到mixup:神奇的正则项
By 苏剑林 | 2018-07-07 | 78723位读者 | 引用SamplePairing和mixup是两种一脉相承的图像数据扩增手段,它们看起来很不合理,而操作则非常简单,但结果却非常漂亮:在多个图像分类任务中都表明它们能提高最终分类模型的精度。
某些读者会困惑于一个问题:为什么如此不合理的数据扩增手段,能得到如此好的效果?而本文则要表明,它们看起来是一种数据扩增方法,事实上它们是对模型的一种正则化方案。正如周星驰的电影《国产凌凌漆》的一句经典台词:
表面上看这是一个吹风机,其实它是一个刮胡刀。
数据扩增
让我们从数据扩增说起。数据扩增是指我们在对原始数据做一些简单的变换后,它们对应的类别往往不会变化,所以我们可以在原来数据的基础上,“造”出更多的数据来。比如一幅小狗的照片,将它水平翻转、轻微的旋转、裁剪、平移等操作后,我们认为它的类别没有变化,它还是原来的那只狗。这样一来,从一个样本我们可以衍生出好几个样本,从而增加了训练样本量。

狗

旋转的狗
6
Aug
“让Keras更酷一些!”:精巧的层与花式的回调
By 苏剑林 | 2018-08-06 | 167076位读者 | 引用Keras伴我走来
回想起进入机器学习领域的这两三年来,Keras是一直陪伴在笔者的身边。要不是当初刚掉进这个坑时碰到了Keras这个这么易用的框架,能快速实现我的想法,我也不确定我是否能有毅力坚持下来,毕竟当初是theano、pylearn、caffe、torch等的天下,哪怕在今天它们对我来说仍然像天书一般。
后来为了拓展视野,我也去学习了一段时间的tensorflow,用纯tensorflow写过若干程序,但不管怎样,仍然无法割舍Keras。随着对Keras的了解的深入,尤其是花了一点时间研究过Keras的源码后,我发现Keras并没有大家诟病的那样“欠缺灵活性”。事实上,Keras那精巧的封装,可以让我们轻松实现很多复杂的功能。我越来越感觉,Keras像是一件非常精美的艺术品,充分体现了Keras的开发者们深厚的创作功力。
本文介绍Keras中自定义模型的一些内容,相对而言,这属于Keras进阶的内容,刚入门的朋友请暂时忽略。
层的自定义
这里介绍Keras中自定义层及其一些运用技巧,在这之中我们可以看到Keras层的精巧之处。
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 306660位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
21
Sep
细水长flow之f-VAEs:Glow与VAEs的联姻
By 苏剑林 | 2018-09-21 | 133280位读者 | 引用这篇文章是我们前几天挂到arxiv上的论文的中文版。在这篇论文中,我们给出了结合流模型(如前面介绍的Glow)和变分自编码器的一种思路,称之为f-VAEs。理论可以证明f-VAEs是囊括流模型和变分自编码器的更一般的框架,而实验表明相比于原始的Glow模型,f-VAEs收敛更快,并且能在更小的网络规模下达到同样的生成效果。
原文地址:《f-VAEs: Improve VAEs with Conditional Flows》
近来,生成模型得到了广泛关注,其中变分自编码器(VAEs)和流模型是不同于生成对抗网络(GANs)的两种生成模型,它们亦得到了广泛研究。然而它们各有自身的优势和缺点,本文试图将它们结合起来。

由f-VAEs实现的两个真实样本之间的线性插值
基础
设给定数据集的证据分布为$\tilde{p}(x)$,生成模型的基本思路是希望用如下的分布形式来拟合给定数据集分布
$$\begin{equation}q(x)=\int q(z)q(x|z) dz\end{equation}$$
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 273888位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
20
Dec
从动力学角度看优化算法(二):自适应学习率算法
By 苏剑林 | 2018-12-20 | 47334位读者 | 引用在《从动力学角度看优化算法(一):从SGD到动量加速》一文中,我们提出SGD优化算法跟常微分方程(ODE)的数值解法其实是对应的,由此还可以很自然地分析SGD算法的收敛性质、动量加速的原理等等内容。
在这篇文章中,我们继续沿着这个思路,去理解优化算法中的自适应学习率算法。
RMSprop
首先,我们看一个非常经典的自适应学习率优化算法:RMSprop。RMSprop虽然不是最早提出的自适应学习率的优化算法,但是它却是相当实用的一种,它是诸如Adam这样的更综合的算法的基石,通过它我们可以观察自适应学习率的优化算法是怎么做的。
算法概览
一般的梯度下降是这样的:
$$\begin{equation}\boldsymbol{\theta}_{n+1}=\boldsymbol{\theta}_{n} - \gamma \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\end{equation}$$
很明显,这里的$\gamma$是一个超参数,便是学习率,它可能需要在不同阶段做不同的调整。
而RMSprop则是
$$\begin{equation}\begin{aligned}\boldsymbol{g}_{n+1} =& \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\\
\boldsymbol{G}_{n+1}=&\lambda \boldsymbol{G}_{n} + (1 - \lambda) \boldsymbol{g}_{n+1}\otimes \boldsymbol{g}_{n+1}\\
\boldsymbol{\theta}_{n+1}=&\boldsymbol{\theta}_{n} - \frac{\tilde{\gamma}}{\sqrt{\boldsymbol{G}_{n+1} + \epsilon}}\otimes \boldsymbol{g}_{n+1}
\end{aligned}\end{equation}$$
7
Oct
深度学习中的Lipschitz约束:泛化与生成模型
By 苏剑林 | 2018-10-07 | 149947位读者 | 引用前言:去年写过一篇WGAN-GP的入门读物《互怼的艺术:从零直达WGAN-GP》,提到通过梯度惩罚来为WGAN的判别器增加Lipschitz约束(下面简称“L约束”)。前几天遐想时再次想到了WGAN,总觉得WGAN的梯度惩罚不够优雅,后来也听说WGAN在条件生成时很难搞(因为不同类的随机插值就开始乱了...),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到。主要包含在这两篇论文中:《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》和《Spectral Normalization for Generative Adversarial Networks》。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是L约束,并不只是WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为$x$,输出为$y$,模型为$f$,模型参数为$w$,记为
$$\begin{equation}y = f_w(x)\end{equation}$$
很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了$f_{w+\Delta w}(x)$后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到$f_w(x)$;二是对于输入扰动的稳定性,比如输入从$x$变成了$x+\Delta x$后,$f_w(x+\Delta x)$是否能给出相近的预测结果。读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。

最近评论