






15
Mar
从最大似然到EM算法:一致的理解方式
By 苏剑林 | 2018-03-15 | 144023位读者 | 引用最近在思考NLP的无监督学习和概率图相关的一些内容,于是重新把一些参数估计方法理了一遍。在深度学习中,参数估计是最基本的步骤之一了,也就是我们所说的模型训练过程。为了训练模型就得有个损失函数,而如果没有系统学习过概率论的读者,能想到的最自然的损失函数估计是平均平方误差,它也就是对应于我们所说的欧式距离。而理论上来讲,概率模型的最佳搭配应该是“交叉熵”函数,它来源于概率论中的最大似然函数。
最大似然
合理的存在
何为最大似然?哲学上有句话叫做“存在就是合理的”,最大似然的意思是“存在就是最合理的”。具体来说,如果事件$X$的概率分布为$p(X)$,如果一次观测中具体观测到的值分别为$X_1,X_2,\dots,X_n$,并假设它们是相互独立,那么
$$\mathcal{P} = \prod_{i=1}^n p(X_i)\tag{1}$$
是最大的。如果$p(X)$是一个带有参数$\theta$的概率分布式$p_{\theta}(X)$,那么我们应当想办法选择$\theta$,使得$\mathcal{L}$最大化,即
$$\theta = \mathop{\text{argmax}}_{\theta} \mathcal{P}(\theta) = \mathop{\text{argmax}}_{\theta}\prod_{i=1}^n p_{\theta}(X_i)\tag{2}$$
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 431198位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 86962位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
20
Aug
开源一版DGCNN阅读理解问答模型(Keras版)
By 苏剑林 | 2019-08-20 | 71856位读者 | 引用去年写过《基于CNN的阅读理解式问答模型:DGCNN》,介绍了一个纯卷积的简单的问答模型。当时是用Tensorflow实现的,而且没有开源,这几天抽空用Keras复现了一下,决定开源。
模型综述
关于DGCNN的基本介绍,这里不再赘述。本文的模型并不是之前模型的重复实现,而是有所改动,这里只介绍一下被改动的地方。
1、这里放出的模型,线下验证集的分数大概是0.72(之前大约是0.75);
2、本次模型以字为单位,使用笔者之前探索出来的“字词混合Embedding”(之前是以词为单位);
3、本次模型完全去掉了人工特征(之前用了8个人工特征);
4、本次模型去掉了位置Embedding(之前将位置Embedding拼接到输入上);
5、模型架构和训练细节有所微调。
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 67171位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
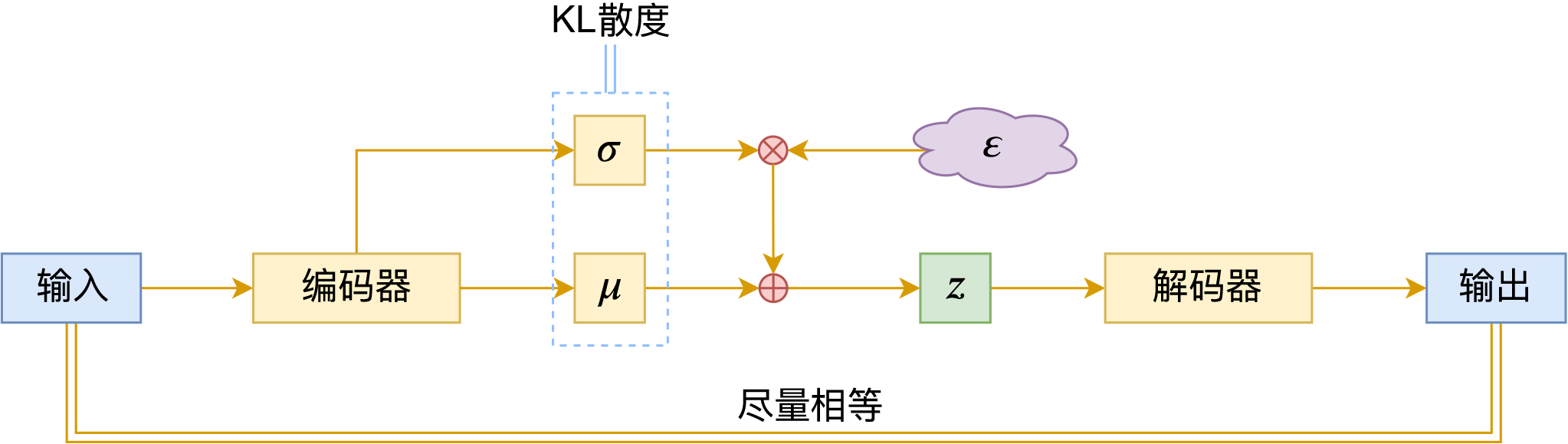
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 57492位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 80810位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
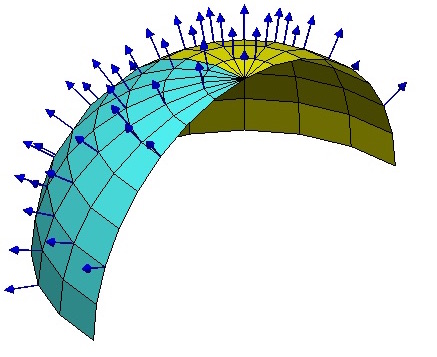
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
14
Oct
【理解黎曼几何】2. 从勾股定理到黎曼度量
By 苏剑林 | 2016-10-14 | 74528位读者 | 引用黎曼度量
几何,英文名是Geometry,原意是大地测量。既然是测量,就必须有参考物,还有得知道如何计算距离。
有了参照物,我们就可以建立坐标系,把每个点的坐标都写下来,至于计算距离,我们有伟大的勾股定理:
$$ds^2 = dx^2 + dy^2 \tag{1} $$
但这里我们忽略了两个问题。
第一个问题是,我们不一定使用直角坐标系,如果使用极坐标,那么应该是
$$ds^2 = dr^2 + r^2 d\theta^2 \tag{2} $$
因此可以联想,最一般的形式应该是
$$ds^2 = E(x^1, x^2)(dx^1)^2 + 2F(x^1, x^2)dx^1 dx^2 + G(x^1, x^2)(dx^2)^2 \tag{3} $$
这里的$x^1,x^2$是广义坐标,使用上标而不是下标来标记序号,是为了跟传统的教材记号一致。那这公式是什么意思呢?其实很简单,正如我们没理由要求全世界都使用人民币一样,我们没必要要求世界各地都使用同一个坐标系,而更合理的做法是,每一处地方都使用自己的坐标系(局部坐标系),然后给出当地计算距离的方法。因此,上述公式正是说,在位置$(x^1, x^2)$处计算向量$(dx^1, dx^2)$的长度的公式(当地的勾股定理)是$ds^2 = E(x^1, x^2)(dx^1)^2 + 2F(x_1, x_2)dx^1 dx^2 + G(x^1, x^2)(dx^2)^2$。

最近评论