






26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 305186位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
25
Dec
矩阵化简二次型(无穷小近似处理抛物型)
By 苏剑林 | 2012-12-25 | 24808位读者 | 引用(阅读本文最好有一定的线性代数基础,至少对线性代数里边的基本概念有所了解。)
这学期已经接近尾声了,我们的《解析几何》已经讲到化简二次曲线了。可是,对于没有线性代数的其他同学们,直接用转轴和移轴这个计算公式来变换,那计算量会让我们很崩溃的;虽然那个“不变量”方法计算上有些简单,却总让人感到很诡异,总觉得不知从何而来,而且又要记一堆公式。事实上,如果有线性代数的基础,这些东西变得相当好理解的。我追求用统一的方法求解同一种问题,即用统一的方式处理所有的二次型,当然也希望计算量简单一点。
一般的模型
一般的二次型可以写成
$$x^T A x + 2 b^T x + c=0$$
其中$x,b$都是n维列向量(各元素为$x_i$和$b_i$),A是n阶方阵(各元素为$a_{ij}$),c是常数。在这里,我们只讨论n=2和n=3的情况。化简二次型的过程,可以归结为A矩阵的简化。
24
Dec
用二次方程判别式判断正定矩阵
By 苏剑林 | 2013-12-24 | 57536位读者 | 引用快要学期末了,不少学霸开始忙碌起来了。不过对非学霸的我来说,基本上每天都是一样的,希望把自己感兴趣的东西深入研究下去,因为我觉得,真正学会点有用的东西才是最重要的。数学分析和高等代数老师都要求写课程论文,我也写了我比较感兴趣的“欧拉数学”和“超复数研究”,之后会把这部分内容与大家分享。
虽然学期已经接近尾声了,但是我们的课程还没有上完。事实上,我们的新课一直上到十八周~随着考试的接近,我们的《高等代数》课程也已经要落幕了。最近在上的是二次型方面的内容,讲到正定二次型和正定矩阵。关于正定矩阵的判别,教科书上提供了两个判别方法,一个是基于定义的初等变换,另外一个就是主子式法。前者无可厚非,但是后者我似乎难以理解——它虽然是正确的,但是它很丑,计算量又大。我还没有想清楚主子式法到底有什么好的?在我看来,本文所探讨的基于二次方程判别式的方法才是简单、快捷的。
正定二次型
所谓正定二次型,就是关于n个变量$x_1,x_2,...,x_n$的二次齐次函数,只要$x_i$不全为0,它的值恒为正数。比如
$$2 x_1^2+x_2^2-2 x_1 x_2=x_1^2+(x_2-x_1)^2$$
这是一个比较简单的正定二次型,多元的还有
$$5 x_1^2+x_2^2+5 x_3^2+4 x_1 x_2-8 x_1 x_3-4 x_2 x_3$$
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 213487位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
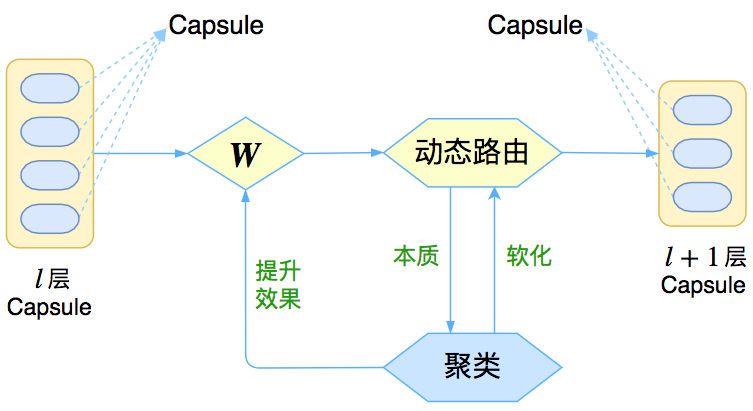
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 92262位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
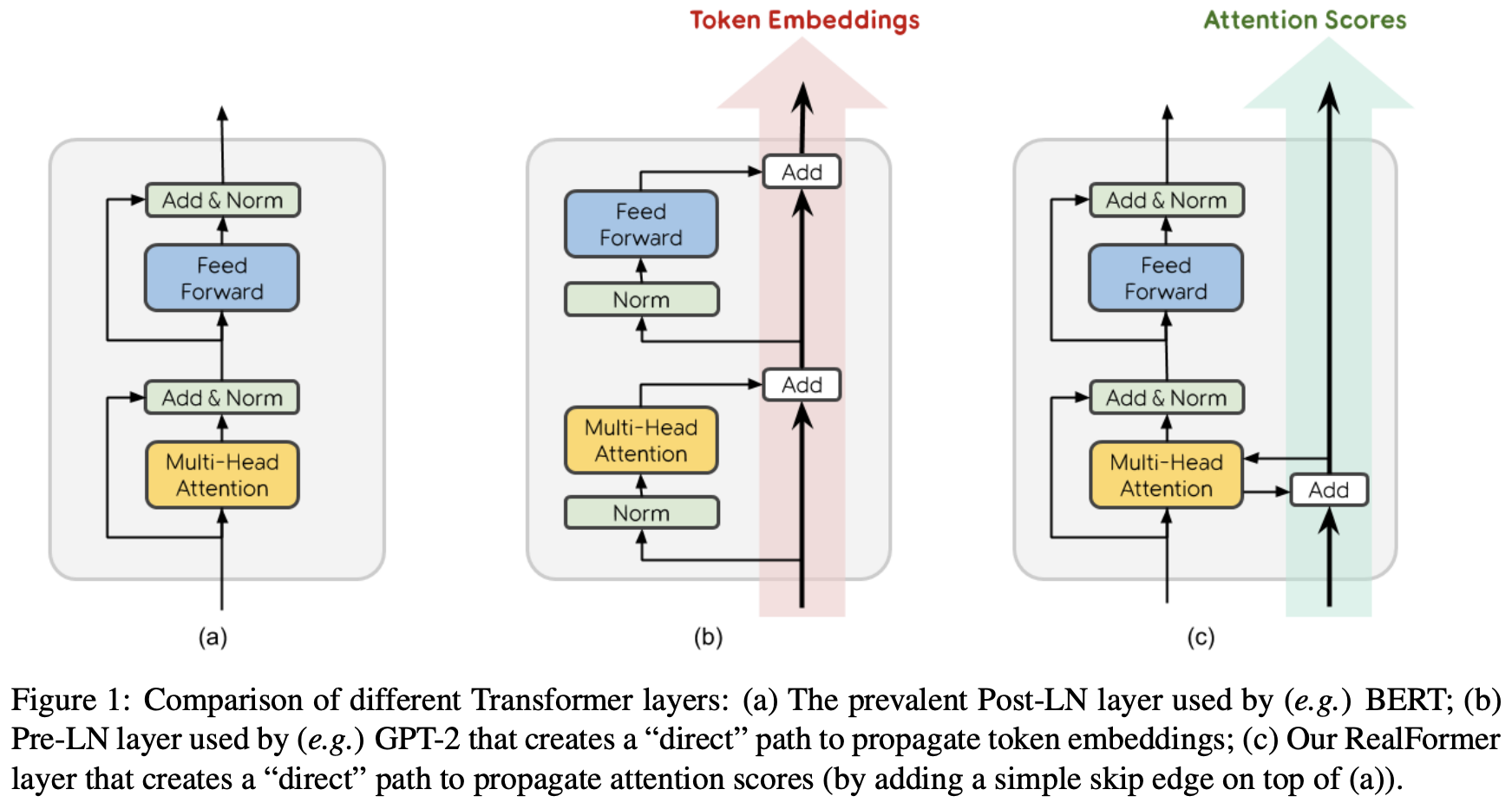
PostLN、PreLN和RealFormer结构示意图
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 44242位读者 | 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
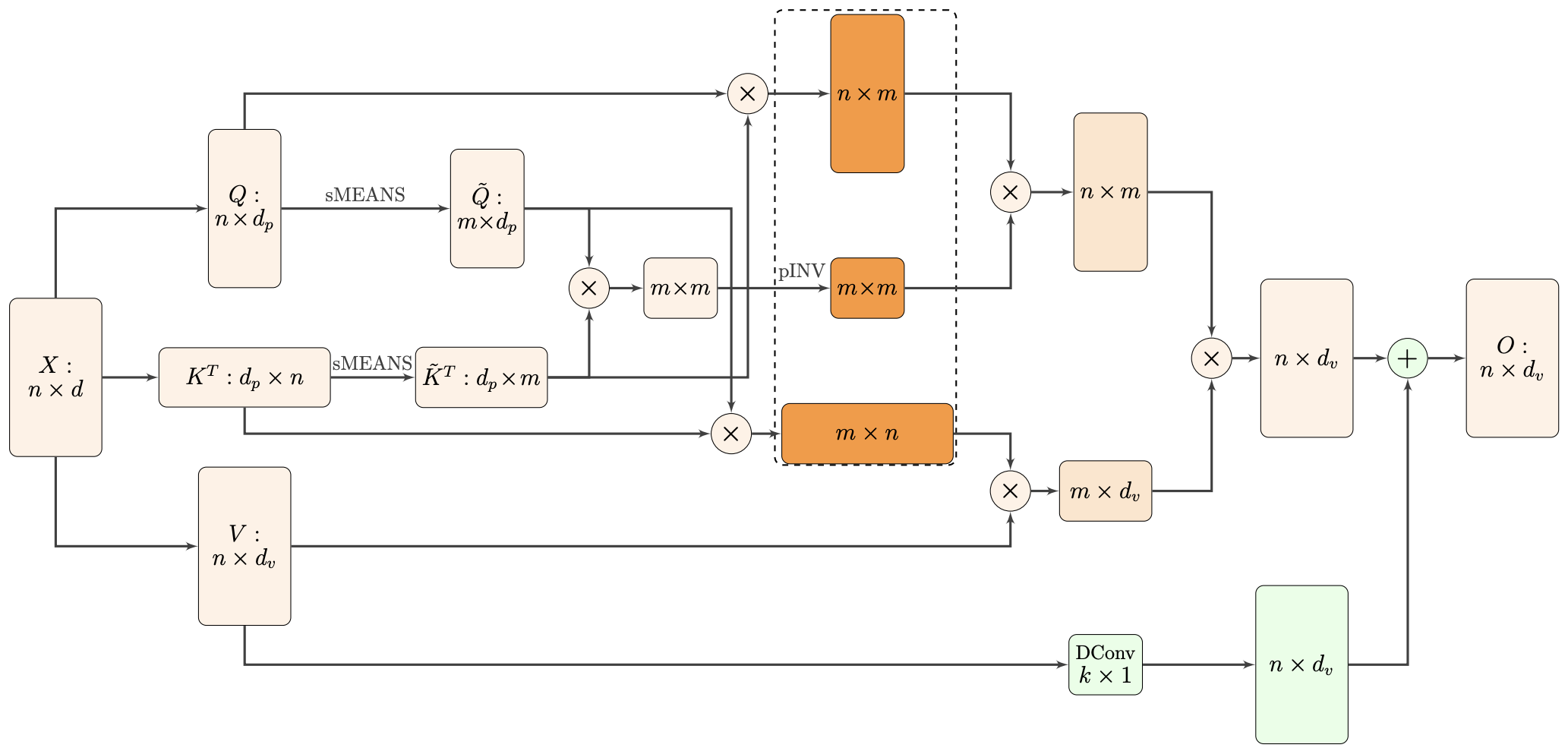
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
5
Jun
从一个单位向量变换到另一个单位向量的正交矩阵
By 苏剑林 | 2021-06-05 | 42198位读者 | 引用这篇文章我们来讨论一个比较实用的线性代数问题:
给定两个$d$维单位(列)向量$\boldsymbol{a},\boldsymbol{b}$,求一个正交矩阵$\boldsymbol{T}$,使得$\boldsymbol{b}=\boldsymbol{T}\boldsymbol{a}$。
由于两个向量模长相同,所以很显然这样的正交矩阵必然存在,那么,我们怎么把它找出来呢?
二维
不难想象,这本质上就是$\boldsymbol{a},\boldsymbol{b}$构成的二维子平面下的向量变换(比如旋转或者镜面反射)问题,所以我们先考虑$d=2$的情形。

正交分解示意图
24
May
重温SSM(一):线性系统和HiPPO矩阵
By 苏剑林 | 2024-05-24 | 39659位读者 | 引用前几天,笔者看了几篇介绍SSM(State Space Model)的文章,才发现原来自己从未认真了解过SSM,于是打算认真去学习一下SSM的相关内容,顺便开了这个新坑,记录一下学习所得。
SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的S4,不算太老,而SSM最新最火的变体大概是去年的Mamba。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样RWKV、RetNet还有此前我们在《Google新作试图“复活”RNN:RNN能否再次辉煌?》介绍过的LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。
尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作《HiPPO: Recurrent Memory with Optimal Polynomial Projections》(简称HiPPO),所以本文从HiPPO开始说起。

最近评论