






18
Sep
提速不掉点:基于词颗粒度的中文WoBERT
By 苏剑林 | 2020-09-18 | 109352位读者 | 引用当前,大部分中文预训练模型都是以字为基本单位的,也就是说中文语句会被拆分为一个个字。中文也有一些多颗粒度的语言模型,比如创新工场的ZEN和字节跳动的AMBERT,但这类模型的基本单位还是字,只不过想办法融合了词信息。目前以词为单位的中文预训练模型很少,据笔者所了解到就只有腾讯UER开源了一个以词为颗粒度的BERT模型,但实测效果并不好。
那么,纯粹以词为单位的中文预训练模型效果究竟如何呢?有没有它的存在价值呢?最近,我们预训练并开源了以词为单位的中文BERT模型,称之为WoBERT(Word-based BERT,我的BERT!),实验显示基于词的WoBERT在不少任务上有它独特的优势,比如速度明显的提升,同时效果基本不降甚至也有提升。在此对我们的工作做一个总结。
后台提示,本文是科学空间的第1000篇文章。
本想写下一篇文章的,但是看到这个提示,就先瞎写个水文纪念一下。都说人老了就喜欢各种感叹,这话还真不假。看到别人高考来个感想,博客十周年了来个感想,现在第1000篇文章了也来个感想,似乎总想找点理由感叹一下一样。那今天又能扯些啥犊子呢?

1000
首先,自恋一下。1000篇文章,如果要印刷下来,就算每篇文章印一页,那也能印个1000页了,相信不少人都没捧起过1000页的书吧(我还真读过,有文章为证:《哈哈,我的“〈圣经〉”到了》),我居然能写个1000篇,也是挺佩服自己的。当然,早期的文章有部分是转载的,不是全部都自己写的,不过还是坚持了不少原创内容,而且就算是转载的也是经过自己编辑整理的,不算纯Copy,所以也勉强能说的过去吧。
然后,庆幸一下。博客开始的主题是天文和科普,后来慢慢偏向了理论物理和数学,现在则偏向了机器学习,但不管怎样,总算很庆幸地在科学这条路坚持了下来。虽然没有像幼时设想的那样成为一名真正的自然科学家/数学家,但终究有点相关,闲时依然可以做做科学计算,勉强也对得起当初的梦想。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 118342位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
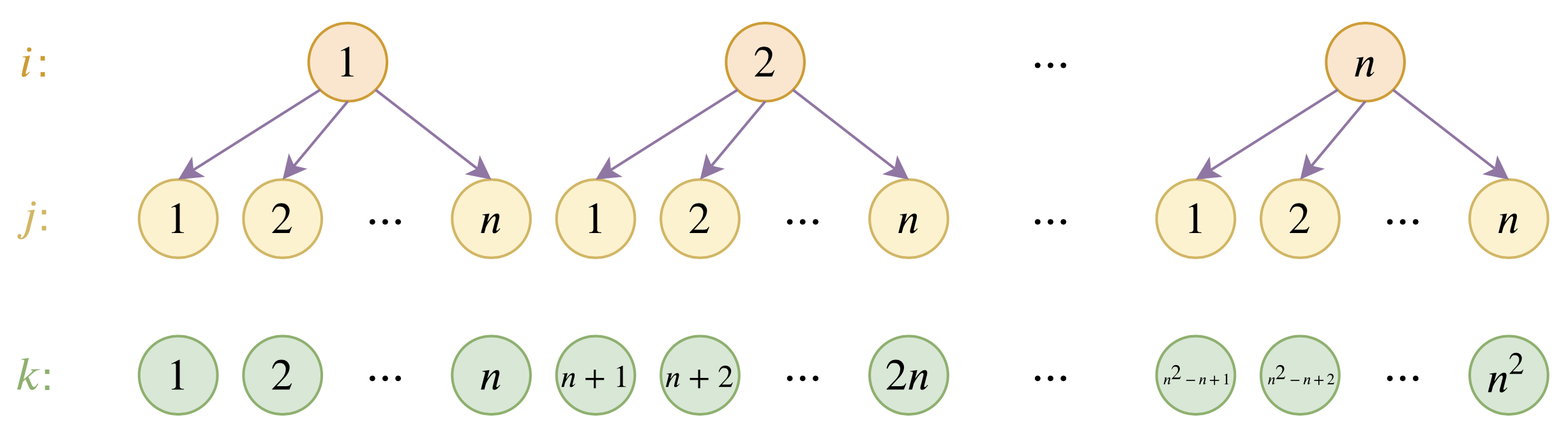
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。
5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 105327位读者 | 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
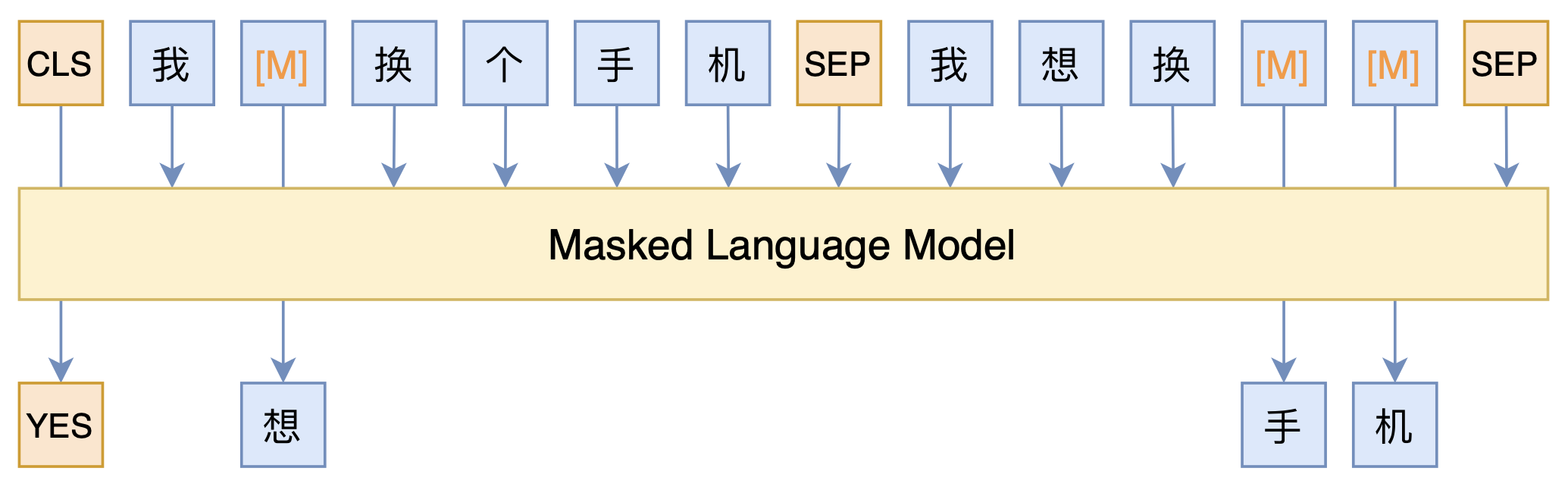
本文模型示意图
26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 229101位读者 | 引用今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。
4
Dec
开局一段扯,数据全靠编?真被一篇“神论文”气到了
By 苏剑林 | 2021-12-04 | 53966位读者 | 引用这篇文章谈一下笔者被昨天出来的一篇“神论文”气到了的经历。
这篇“神论文”是《How not to Lie with a Benchmark: Rearranging NLP Leaderboards》,论文的大致内容是说目前很多排行榜算平均都用算术平均,而它认为几何平均与调和平均更加合理。最关键是它还对GLUE、SuperGLUE等榜单上的模型用几何平均和调和平均重新算了一下排名,结果发现那些超过人类的模型在新的平均方案下都没超过人类了。
看上去是不是觉得挺有意思的?我也觉得挺有意思的,所以打算写一篇博客介绍一下它。结果博客快写完了,然后在对数据的时候,发现里边表格的数据全是乱来的!!!真实的结果完全不支撑它的结论!!!所以,这篇博客就从“表扬大会”变成了“批评大会”...
24
Dec
概率分布的熵归一化(Entropy Normalization)
By 苏剑林 | 2021-12-24 | 47238位读者 | 引用在上一篇文章《从熵不变性看Attention的Scale操作》中,我们从熵不变性的角度推导了一个新的Attention Scale,并且实验显示具有熵不变性的新Scale确实能使得Attention的外推性能更好。这时候笔者就有一个很自然的疑问:
有没有类似L2 Normalization之类的操作,可以直接对概率分布进行变换,使得保持原始分布主要特性的同时,让它的熵为指定值?
笔者带着疑问搜索了一番,发现没有类似的研究,于是自己尝试推导了一下,算是得到了一个基本满意的结果,暂称为“熵归一化(Entropy Normalization)”,记录在此,供有需要的读者参考。
幂次变换
首先,假设$n$元分布$(p_1,p_2,\cdots,p_n)$,它的熵定义为
\begin{equation}\mathcal{H} = -\sum_i p_i \log p_i = \mathbb{E}[-\log p_i]\end{equation}
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 75814位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
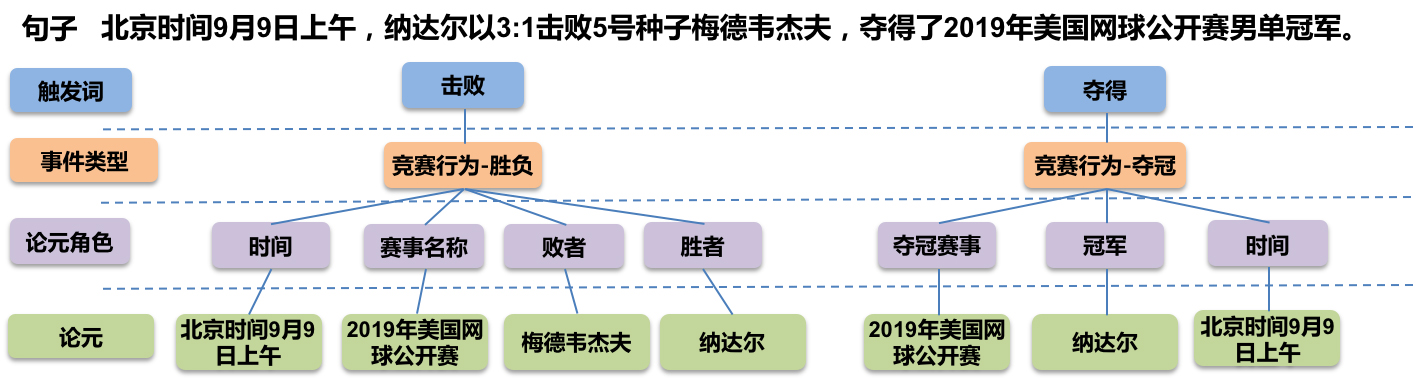
标准的事件抽取样本(图片来自百度DuEE的GitHub)

最近评论