






25
Nov
6个派生优化器的简单介绍及其实现
By 苏剑林 | 2019-11-25 | 51385位读者 | 引用优化器可能是深度学习最“玄学”的一个模块之一了:有时候换一个优化器就能带来明显的提升,有时候别人说提升很多的优化器用到自己的任务上却一丁点用都没有,理论性质好的优化器不一定工作得很好,纯粹拍脑袋而来的优化器也未必就差了。但不管怎样,优化器终究也为热爱“深度炼丹”的同学提供了多一个选择。
近几年来,关于优化器的工作似乎也在慢慢增多,很多论文都提出了对常用优化器(尤其是Adam)的大大小小的改进。本文就汇总一些优化器工作或技巧,并统一给出了代码实现,供读者有需调用。
基本形式
所谓“派生”,就是指相关的技巧都是建立在已有的优化器上的,任意一个已有的优化器都可以用上这些技巧,从而变成一个新的优化器。
已有的优化器的基本形式为:
\begin{equation}\begin{aligned}\boldsymbol{g}_t =&\, \nabla_{\boldsymbol{\theta}} L\\
\boldsymbol{h}_t =&\, f(\boldsymbol{g}_{\leq t})\\
\boldsymbol{\theta}_{t+1} =&\, \boldsymbol{\theta}_t - \gamma \boldsymbol{h}_t
\end{aligned}\end{equation}
其中$\boldsymbol{g}_t$即梯度,而$\boldsymbol{g}_{\leq t}$指的是截止到当前步的所有梯度信息,它们经过某种运算$f$(比如累积动量、累积二阶矩校正学习率等)后得到$\boldsymbol{h}_t$,然后由$\boldsymbol{h}_t$来更新参数,这里的$\gamma$就是指学习率。
8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 78694位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。
16
Jul
“让Keras更酷一些!”:层中层与mask
By 苏剑林 | 2019-07-16 | 146534位读者 | 引用这一篇“让Keras更酷一些!”将和读者分享两部分内容:第一部分是“层中层”,顾名思义,是在Keras中自定义层的时候,重用已有的层,这将大大减少自定义层的代码量;另外一部分就是应读者所求,介绍一下序列模型中的mask原理和方法。
层中层
在《“让Keras更酷一些!”:精巧的层与花式的回调》一文中我们已经介绍过Keras自定义层的基本方法,其核心步骤是定义build和call两个函数,其中build负责创建可训练的权重,而call则定义具体的运算。
拒绝重复劳动
经常用到自定义层的读者可能会感觉到,在自定义层的时候我们经常在重复劳动,比如我们想要增加一个线性变换,那就要在build中增加一个kernel和bias变量(还要自定义变量的初始化、正则化等),然后在call里边用K.dot来执行,有时候还需要考虑维度对齐的问题,步骤比较繁琐。但事实上,一个线性变换其实就是一个不加激活函数的Dense层罢了,如果在自定义层时能重用已有的层,那显然就可以大大节省代码量了。
30
Jul
Keras实现两个优化器:Lookahead和LazyOptimizer
By 苏剑林 | 2019-07-30 | 46027位读者 | 引用最近用Keras实现了两个优化器,也算是有点实现技巧,遂放在一起写篇文章简介一下(如果只有一个的话我就不写了)。这两个优化器的名字都挺有意思的,一个是look ahead(往前看?),一个是lazy(偷懒?),难道是两个完全不同的优化思路么?非也非也~只能说发明者们起名字太有创意了。
Lookahead
首先登场的是Lookahead优化器,它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 95426位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 323673位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
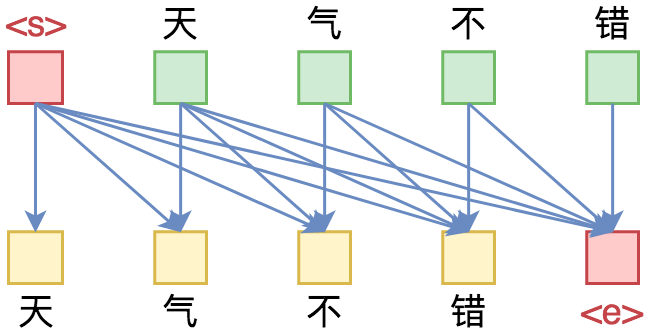
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 93014位读者 | 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
29
Jan

最近评论