






21
Sep
细水长flow之f-VAEs:Glow与VAEs的联姻
By 苏剑林 | 2018-09-21 | 132768位读者 | 引用这篇文章是我们前几天挂到arxiv上的论文的中文版。在这篇论文中,我们给出了结合流模型(如前面介绍的Glow)和变分自编码器的一种思路,称之为f-VAEs。理论可以证明f-VAEs是囊括流模型和变分自编码器的更一般的框架,而实验表明相比于原始的Glow模型,f-VAEs收敛更快,并且能在更小的网络规模下达到同样的生成效果。
原文地址:《f-VAEs: Improve VAEs with Conditional Flows》
近来,生成模型得到了广泛关注,其中变分自编码器(VAEs)和流模型是不同于生成对抗网络(GANs)的两种生成模型,它们亦得到了广泛研究。然而它们各有自身的优势和缺点,本文试图将它们结合起来。

由f-VAEs实现的两个真实样本之间的线性插值
基础
设给定数据集的证据分布为$\tilde{p}(x)$,生成模型的基本思路是希望用如下的分布形式来拟合给定数据集分布
$$\begin{equation}q(x)=\int q(z)q(x|z) dz\end{equation}$$
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 272558位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
2
Dec
最小熵原理(四):“物以类聚”之从图书馆到词向量
By 苏剑林 | 2018-12-02 | 92776位读者 | 引用从第一篇看下来到这里,我们知道所谓“最小熵原理”就是致力于降低学习成本,试图用最小的成本完成同样的事情。所以整个系列就是一个“偷懒攻略”。那偷懒的秘诀是什么呢?答案是“套路”,所以本系列又称为“套路宝典”。
本篇我们介绍图书馆里边的套路。
先抛出一个问题:词向量出现在什么时候?是2013年Mikolov的Word2Vec?还是是2003年Bengio大神的神经语言模型?都不是,其实词向量可以追溯到千年以前,在那古老的图书馆中...

图书馆一角(图片来源于百度搜索)
走进图书馆
图书馆里有词向量?还是千年以前?在哪本书?我去借来看看。
放书的套路
其实不是哪本书,而是放书的套路。
很明显,图书馆中书的摆放是有“套路”的:它们不是随机摆放的,而是分门别类地放置的,比如数学类放一个区,文学类放一个区,计算机类也放一个区;同一个类也有很多子类,比如数学类中,数学分析放一个子区,代数放一个子区,几何放一个子区,等等。读者是否思考过,为什么要这么分类放置?分类放置有什么好处?跟最小熵又有什么关系?
23
Jun
从采样看优化:可导优化与不可导优化的统一视角
By 苏剑林 | 2020-06-23 | 55171位读者 | 引用不少读者都应该知道,损失函数与评测指标的不一致性是机器学习的典型现象之一,比如分类问题中损失函数用交叉熵,评测指标则是准确率或者F1,又比如文本生成中损失函数是teacher-forcing形式的交叉熵,评测指标则是BLEU、ROUGE等。理想情况下,当然是评测什么指标,我们就去优化这个指标,然而评测指标通常都是不可导的,而我们多数都是使用基于梯度的优化器,这就要求最小化的目标必须是可导的,这是不一致性的来源。
前些天在arxiv刷到了一篇名为《MLE-guided parameter search for task loss minimization in neural sequence modeling》的论文,顾名思义,它是研究如何直接优化文本生成的评测指标的。经过阅读,笔者发现这篇论文很有价值,事实上它提供了一种优化评测指标的新思路,适用范围并不局限于文本生成中。不仅如此,它甚至还包含了一种理解可导优化与不可导优化的统一视角。
采样视角
首先,我们可以通过采样的视角来重新看待优化问题:设模型当前参数为$\theta$,优化目标为$l(\theta)$,我们希望决定下一步的更新量$\Delta\theta$,为此,我们先构建分布
\begin{equation}p(\Delta\theta|\theta)=\frac{e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha}}{Z(\theta)},\quad Z(\theta) = \int e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha} d(\Delta\theta)\end{equation}
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 107290位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 132733位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
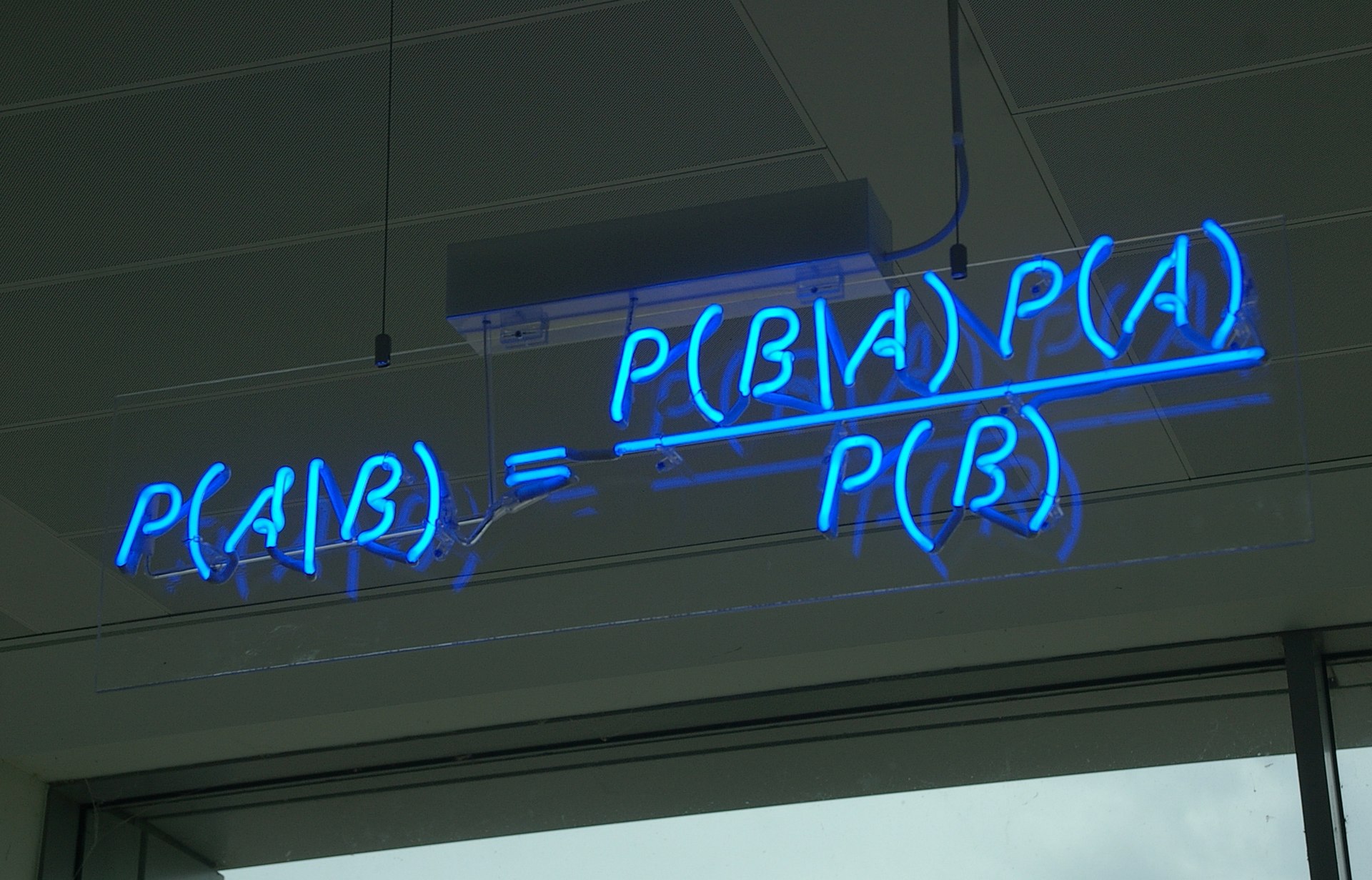
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
18
Oct
生成扩散模型漫谈(十三):从万有引力到扩散模型
By 苏剑林 | 2022-10-18 | 52292位读者 | 引用对于很多读者来说,生成扩散模型可能是他们遇到的第一个能够将如此多的数学工具用到深度学习上的模型。在这个系列文章中,我们已经展示了扩散模型与数学分析、概率统计、常微分方程、随机微分方程乃至偏微分方程等内容的深刻联系,可以说,即便是做数学物理方程的纯理论研究的同学,大概率也可以在扩散模型中找到自己的用武之地。
在这篇文章中,我们再介绍一个同样与数学物理有深刻联系的扩散模型——由“万有引力定律”启发的ODE式扩散模型,出自论文《Poisson Flow Generative Models》(简称PFGM),它给出了一个构建ODE式扩散模型的全新视角。
万有引力
中学时期我们就学过万有引力定律,大概的描述方式是:
两个质点彼此之间相互吸引的作用力,是与它们的质量乘积成正比,并与它们之间的距离成平方反比。
6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 244428位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图

最近评论