






22
Oct
RSGAN:对抗模型中的“图灵测试”思想
By 苏剑林 | 2018-10-22 | 126047位读者 | 引用这两天无意间发现一个非常有意义的工作,称为“相对GAN”,简称RSGAN,来自文章《The relativistic discriminator: a key element missing from standard GAN》,据说该文章还得到了GAN创始人Goodfellow的点赞。这篇文章提出了用相对的判别器来取代标准GAN原有的判别器,使得生成器的收敛更为迅速,训练更为稳定。
可惜的是,这篇文章仅仅从训练和实验角度对结果进行了论述,并没有进行更深入的分析,以至于不少人觉得这只是GAN训练的一个trick。但是在笔者来看,RSGAN具有更为深刻的含义,甚至可以看成它已经开创了一个新的GAN流派。所以,笔者决定对RSGAN模型及其背后的内涵做一个基本的介绍。不过需要指出的是,除了结果一样之外,本文的介绍过程跟原论文相比几乎没有重合之处。
“图灵测试”思想
SGAN
SGAN就是标准的GAN(Standard GAN)。就算没有做过GAN研究的读者,相信也从各种渠道了解到GAN的大概原理:“造假者”不断地进行造假,试图愚弄“鉴别者”;“鉴别者”不断提高鉴别技术,以分辨出真品和赝品。两者相互竞争,共同进步,直到“鉴别者”无法分辨出真、赝品了,“造假者”就功成身退了。
在建模时,通过交替训练实现这个过程:固定生成器,训练一个判别器(二分类模型),将真实样本输出1,将伪造样本输出0;然后固定判别器,训练生成器让伪造样本尽可能输出1,后面这一步不需要真实样本参与。
问题所在
然而,这个建模过程似乎对判别器的要求过于苛刻了,因为判别器是孤立运作的:训练生成器时,真实样本没有参与,所以判别器必须把关于真实样本的所有属性记住,这样才能指导生成器生成更真实的样本。
20
Nov
不用L约束又不会梯度消失的GAN,了解一下?
By 苏剑林 | 2018-11-20 | 169507位读者 | 引用不知道从什么时候开始,我发现我也掉到了GAN的大坑里边了,唉,争取早日能跳出来...
这篇博客介绍的是我最近提交到arxiv的一个关于GAN的新框架,里边主要介绍了一种对概率散度的新理解,并且基于这种理解推导出了一个新的GAN。整篇文章比较偏理论,对这个GAN的相关性质都做了完整的论证,自认为是一个理论完备的结果。
文章链接:https://papers.cool/arxiv/1811.07296
先摆结论:
1、论文提供了一种分析和构造概率散度的直接思路,从而简化了构建新GAN框架的过程。
2、推导出了一个称为GAN-QP的GAN框架$\eqref{eq:gan-gp-gd}$,这个GAN不需要像WGAN那样的L约束,又不会有SGAN的梯度消失问题,实验表明它至少有不逊色于、甚至优于WGAN的表现。

GAN-QP效果图
论文的实验最大做到了512x512的人脸生成(CelebA HQ),充分表明了模型的有效性(效果不算完美,但是模型特别简单)。有兴趣的朋友,欢迎继续阅读下去。
3
May
从动力学角度看优化算法(四):GAN的第三个阶段
By 苏剑林 | 2019-05-03 | 94553位读者 | 引用在对GAN的学习和思考过程中,我发现我不仅学习到了一种有效的生成模型,而且它全面地促进了我对各种模型各方面的理解,比如模型的优化和理解视角、正则项的意义、损失函数与概率分布的联系、概率推断等等。GAN不单单是一个“造假的玩具”,而是具有深刻意义的概率模型和推断方法。
作为事后的总结,我觉得对GAN的理解可以粗糙地分为三个阶段:
1、样本阶段:在这个阶段中,我们了解了GAN的“鉴别者-造假者”诠释,懂得从这个原理出发来写出基本的GAN公式(如原始GAN、LSGAN),比如判别器和生成器的loss,并且完成简单GAN的训练;同时,我们知道GAN有能力让图片更“真”,利用这个特性可以把GAN嵌入到一些综合模型中。
2、分布阶段:在这个阶段中,我们会从概率分布及其散度的视角来分析GAN,典型的例子是WGAN和f-GAN,同时能基本理解GAN的训练困难问题,比如梯度消失和mode collapse等,甚至能基本地了解变分推断,懂得自己写出一些概率散度,继而构造一些新的GAN形式。
3、动力学阶段:在这个阶段中,我们开始结合优化器来分析GAN的收敛过程,试图了解GAN是否能真的达到理论的均衡点,进而理解GAN的loss和正则项等因素如何影响的收敛过程,由此可以针对性地提出一些训练策略,引导GAN模型到达理论均衡点,从而提高GAN的效果。
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 48989位读者 | 引用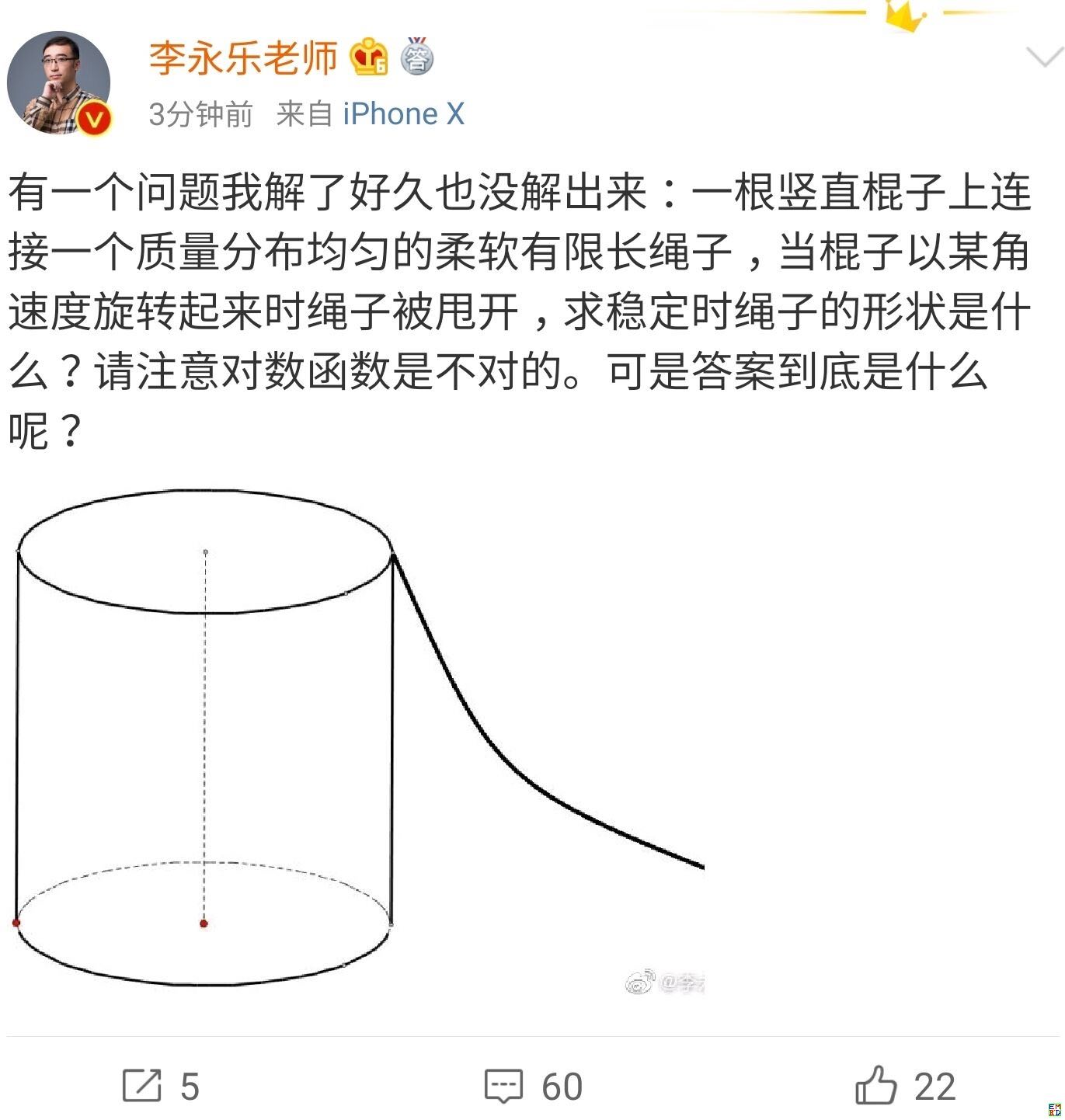
16
Jun
梯度流:探索通向最小值之路
By 苏剑林 | 2023-06-16 | 30539位读者 | 引用在这篇文章中,我们将探讨一个被称为“梯度流(Gradient Flow)”的概念。简单来说,梯度流是将我们在用梯度下降法中寻找最小值的过程中的各个点连接起来,形成一条随(虚拟的)时间变化的轨迹,这条轨迹便被称作“梯度流”。在文章的后半部分,我们将重点讨论如何将梯度流的概念扩展到概率空间,从而形成“Wasserstein梯度流”,为我们理解连续性方程、Fokker-Planck方程等内容提供一个新的视角。
梯度下降
假设我们想搜索光滑函数$f(\boldsymbol{x})$的最小值,常见的方案是梯度下降(Gradient Descent),即按照如下格式进行迭代:
\begin{equation}\boldsymbol{x}_{t+1} = \boldsymbol{x}_t -\alpha \nabla_{\boldsymbol{x}_t}f(\boldsymbol{x}_t)\label{eq:gd-d}\end{equation}
如果$f(\boldsymbol{x})$关于$\boldsymbol{x}$是凸的,那么梯度下降通常能够找到最小值点;相反,则通常只能收敛到一个“驻点”——即梯度为0的点,比较理想的情况下能收敛到一个极小值(局部最小值)点。这里没有对极小值和最小值做严格区分,因为在深度学习中,即便是收敛到一个极小值点也是很难得的了。
24
Jun
生成扩散模型漫谈(十九):作为扩散ODE的GAN
By 苏剑林 | 2023-06-24 | 30403位读者 | 引用在文章《生成扩散模型漫谈(十六):W距离 ≤ 得分匹配》中,我们推导了Wasserstein距离与扩散模型得分匹配损失之间的一个不等式,表明扩散模型的优化目标与WGAN的优化目标在某种程度上具有相似性。而在本文,我们将探讨《MonoFlow: Rethinking Divergence GANs via the Perspective of Wasserstein Gradient Flows》中的研究成果,它进一步展示了GAN与扩散模型之间的联系:GAN实际上可以被视为在另一个时间维度上的扩散ODE!
这些发现表明,尽管GAN和扩散模型表面上是两种截然不同的生成式模型,但它们实际上存在许多相似之处,并在许多方面可以相互借鉴和参考。
思路简介
我们知道,GAN所训练的生成器是从噪声$\boldsymbol{z}$到真实样本的一个直接的确定性变换$\boldsymbol{g}_{\boldsymbol{\theta}}(\boldsymbol{z})$,而扩散模型的显著特点是“渐进式生成”,它的生成过程对应于从一系列渐变的分布$p_0(\boldsymbol{x}_0),p_1(\boldsymbol{x}_1),\cdots,p_T(\boldsymbol{x}_T)$中采样(注:在前面十几篇文章中,$\boldsymbol{x}_T$是噪声,$\boldsymbol{x}_0$是目标样本,采样过程是$\boldsymbol{x}_T\to \boldsymbol{x}_0$,但为了便于下面的表述,这里反过来改为$\boldsymbol{x}_0\to \boldsymbol{x}_T$)。看上去确实找不到多少相同之处,那怎么才能将两者联系起来呢?
6
Sep
“闭门造车”之多模态思路浅谈(三):位置编码
By 苏剑林 | 2024-09-06 | 33303位读者 | 引用在前面的文章中,我们曾表达过这样的观点:多模态LLM相比纯文本LLM的主要差异在于,前者甚至还没有形成一个公认为标准的方法论。这里的方法论,不仅包括之前讨论的生成和训练策略,还包括一些基础架构的设计,比如本文要谈的“多模态位置编码”。
对于这个主题,我们之前在《Transformer升级之路:17、多模态位置编码的简单思考》就已经讨论过一遍,并且提出了一个方案(RoPE-Tie)。然而,当时笔者对这个问题的思考仅处于起步阶段,存在细节考虑不周全、认识不够到位等问题,所以站在现在的角度回看,当时所提的方案与完美答案还有明显的距离。
因此,本文我们将自上而下地再次梳理这个问题,并且给出一个自认为更加理想的结果。
多模位置
多模态模型居然连位置编码都没有形成共识,这一点可能会让很多读者意外,但事实上确实如此。对于文本LLM,目前主流的位置编码是RoPE(RoPE就不展开介绍了,假设读者已经熟知),更准确来说是RoPE-1D,因为原始设计只适用于1D序列。后来我们推导了RoPE-2D,这可以用于图像等2D序列,按照RoPE-2D的思路我们可以平行地推广到RoPE-3D,用于视频等3D序列。
25
Aug


最近评论