






24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 92308位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
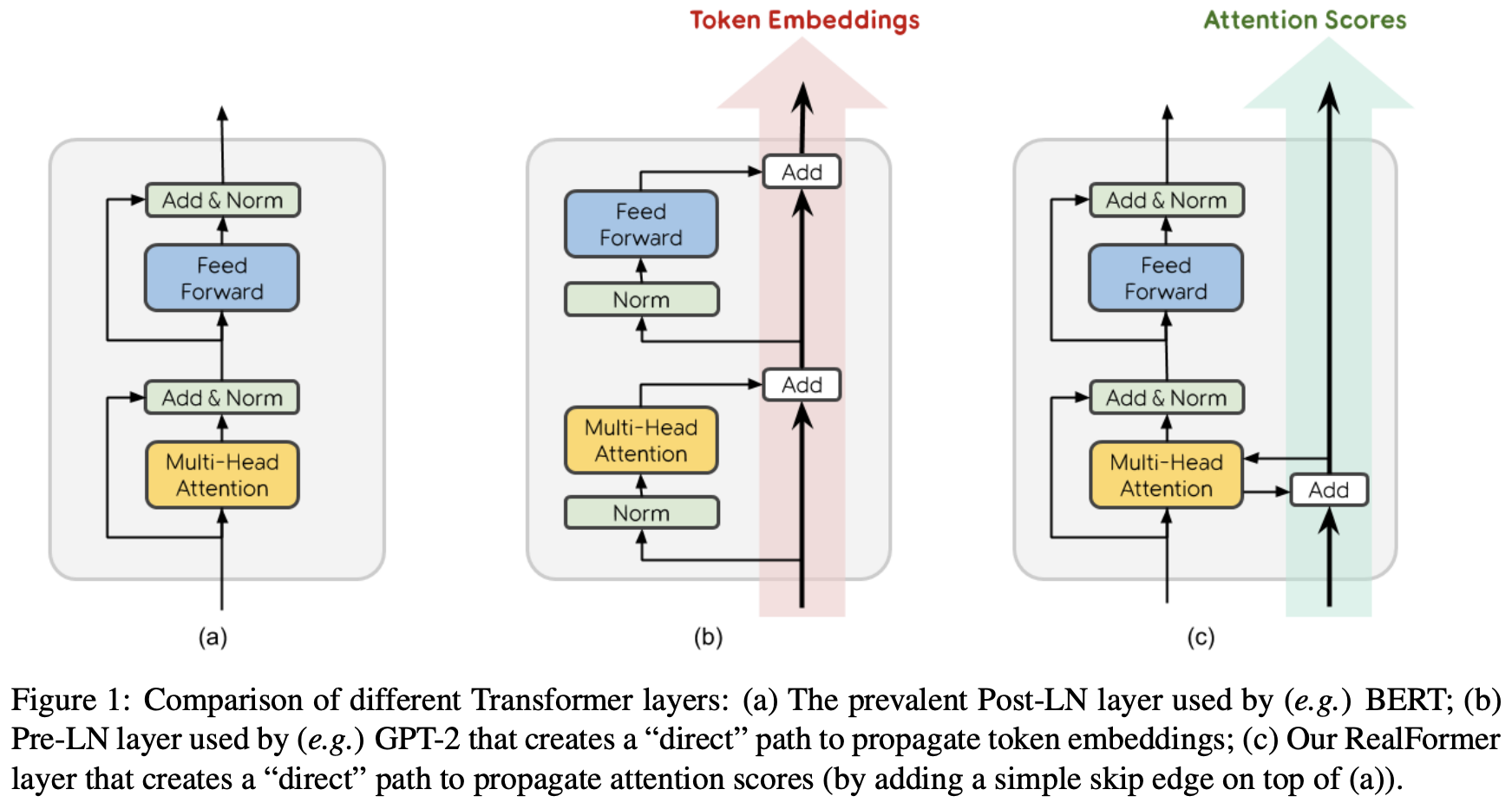
PostLN、PreLN和RealFormer结构示意图
23
Mar
Transformer升级之路:2、博采众长的旋转式位置编码
By 苏剑林 | 2021-03-23 | 280731位读者 | 引用上一篇文章中,我们对原始的Sinusoidal位置编码做了较为详细的推导和理解,总的感觉是Sinusoidal位置编码是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。
本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
11
Apr
无监督语义相似度哪家强?我们做了个比较全面的评测
By 苏剑林 | 2021-04-11 | 142502位读者 | 引用一月份的时候,笔者写了《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,指出无监督语义相似度的SOTA模型BERT-flow其实可以通过一个简单的线性变换(白化操作,BERT-whitening)达到。随后,我们进一步完善了实验结果,写成了论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》。这篇博客将对这篇论文的内容做一个基本的梳理,并在5个中文语义相似度任务上进行了补充评测,包含了600多个实验结果。
方法概要
BERT-whitening的思路很简单,就是在得到每个句子的句向量$\{x_i\}_{i=1}^N$后,对这些矩阵进行一个白化(也就是PCA),使得每个维度的均值为0、协方差矩阵为单位阵,然后保留$k$个主成分,流程如下图:

BERT-whitening的基本流程
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 56780位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 74742位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
22
Oct
CAN:借助先验分布提升分类性能的简单后处理技巧
By 苏剑林 | 2021-10-22 | 144954位读者 | 引用顾名思义,本文将会介绍一种用于分类问题的后处理技巧——CAN(Classification with Alternating Normalization),出自论文《When in Doubt: Improving Classification Performance with Alternating Normalization》。经过笔者的实测,CAN确实多数情况下能提升多分类问题的效果,而且几乎没有增加预测成本,因为它仅仅是对预测结果的简单重新归一化操作。
有趣的是,其实CAN的思想是非常朴素的,朴素到每个人在生活中都应该用过同样的思想。然而,CAN的论文却没有很好地说清楚这个思想,只是纯粹形式化地介绍和实验这个方法。本文的分享中,将会尽量将算法思想介绍清楚。
思想例子
假设有一个二分类问题,模型对于输入$a$给出的预测结果是$p^{(a)} = [0.05, 0.95]$,那么我们就可以给出预测类别为$1$;接下来,对于输入$b$,模型给出的预测结果是$p^{(b)}=[0.5,0.5]$,这时候处于最不确定的状态,我们也不知道输出哪个类别好。
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 112586位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
18
Jan
多任务学习漫谈(一):以损失之名
By 苏剑林 | 2022-01-18 | 148490位读者 | 引用能提升模型性能的方法有很多,多任务学习(Multi-Task Learning)也是其中一种。简单来说,多任务学习是希望将多个相关的任务共同训练,希望不同任务之间能够相互补充和促进,从而获得单任务上更好的效果(准确率、鲁棒性等)。然而,多任务学习并不是所有任务堆起来就能生效那么简单,如何平衡每个任务的训练,使得各个任务都尽量获得有益的提升,依然是值得研究的课题。
最近,笔者机缘巧合之下,也进行了一些多任务学习的尝试,借机也学习了相关内容,在此挑部分结果与大家交流和讨论。
加权求和
从损失函数的层面看,多任务学习就是有多个损失函数$\mathcal{L}_1,\mathcal{L}_2,\cdots,\mathcal{L}_n$,一般情况下它们有大量的共享参数、少量的独立参数,而我们的目标是让每个损失函数都尽可能地小。为此,我们引入权重$\alpha_1,\alpha_2,\cdots,\alpha_n\geq 0$,通过加权求和的方式将它转化为如下损失函数的单任务学习
\begin{equation}\mathcal{L} = \sum_{i=1}^n \alpha_i \mathcal{L}_i\label{eq:w-loss}\end{equation}
在这个视角下,多任务学习的主要难点就是如何确定各个$\alpha_i$了。

最近评论