






11
Apr
熵不变性Softmax的一个快速推导
By 苏剑林 | 2022-04-11 | 13092位读者 | 引用在文章《从熵不变性看Attention的Scale操作》中,我们推导了一版具有熵不变性质的注意力机制:
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\kappa \log n}{d}QK^{\top}\right)V\label{eq:a}\end{equation}
可以观察到,它主要是往Softmax里边引入了长度相关的缩放因子$\log n$来实现的。原来的推导比较繁琐,并且做了较多的假设,不利于直观理解,本文为其补充一个相对简明快速的推导。
推导过程
我们可以抛开注意力机制的背景,直接设有$s_1,s_2,\cdots,s_n\in\mathbb{R}$,定义
$$p_i = \frac{e^{\lambda s_i}}{\sum\limits_{i=1}^n e^{\lambda s_i}}$$
29
Dec
SquarePlus:可能是运算最简单的ReLU光滑近似
By 苏剑林 | 2021-12-29 | 31300位读者 | 引用ReLU函数,也就是$\max(x,0)$,是最常见的激活函数之一,然而它在$x=0$处的不可导通常也被视为一个“槽点”。为此,有诸多的光滑近似被提出,比如SoftPlus、GeLU、Swish等,不过这些光滑近似无一例外地至少都使用了指数运算$e^x$(SoftPlus还用到了对数),从“精打细算”的角度来看,计算量还是不小的(虽然当前在GPU加速之下,我们很少去感知这点计算量了)。最近有一篇论文《Squareplus: A Softplus-Like Algebraic Rectifier》提了一个更简单的近似,称为SquarePlus,我们也来讨论讨论。
需要事先指出的是,笔者是不建议大家花太多时间在激活函数的选择和设计上的,所以虽然分享了这篇论文,但主要是提供一个参考结果,并充当一道练习题来给大家“练练手”。
定义
SquarePlus的形式很简单,只用到了加、乘、除和开方:
\begin{equation}\text{SquarePlus}(x)=\frac{x+\sqrt{x^2+b}}{2}\end{equation}
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 58616位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
26
Mar
GELU的两个初等函数近似是怎么来的
By 苏剑林 | 2020-03-26 | 38553位读者 | 引用GELU,全称为Gaussian Error Linear Unit,也算是RELU的变种,是一个非初等函数形式的激活函数。它由论文《Gaussian Error Linear Units (GELUs)》提出,后来被用到了GPT中,再后来被用在了BERT中,再再后来的不少预训练语言模型也跟着用到了它。随着BERT等预训练语言模型的兴起,GELU也跟着水涨船高,莫名其妙地就成了热门的激活函数了。
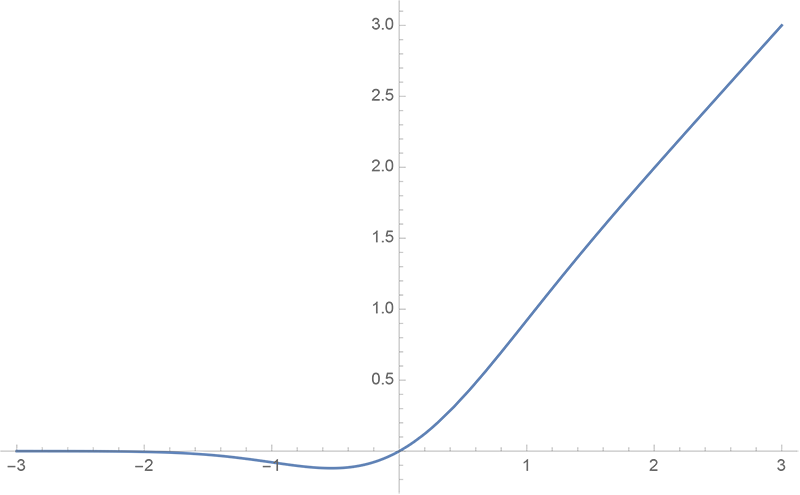
gelu函数图像
在GELU的原始论文中,作者不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式,本文来讨论它们是怎么得到的。
20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 100521位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到$\arg\max$等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是$\max$操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
22
May
当Matlab遇上牛顿法
By 苏剑林 | 2013-05-22 | 53030位读者 | 引用牛顿法是求方程近似根的一个相当有用而且快捷的方法,我们最近科学计算软件课程(Matlab)的一个作业就是编写求方程近似解的程序,其中涉及到牛顿法。我们要实现的目标是,用户输入一道方程,脚本就自动求出根来。这看起来是一个挺简单的循环迭代程序,但是由于Matlab本身的特殊性,却产生了不少困难。
Matlab是为了数值计算(尤其是矩阵运算)而生的,因此它并不擅长处理符号计算。这就给我们编程带来了困难。在网上随便一搜,就可以发现,网上的Matlab牛顿法程序都是要求用户同时输入方程及其导函数,这显然是不方便的,因为Matlab本身就具备了求导功能。下面我们来分析一下困难在哪里。
我们要实现的最基本功能是定义一个函数,然后可以根据该函数求具体的函数值,并且自动求该函数的导数,接着求导数值。这些看起来很基本的功能在Matlab中却很难调和,因为Matlab的“函数”定义很广,一个具有特定功能的M文件叫“函数”,一个运算式$f(x)$也可能是一个函数,显然后者是可以求导的,前者却不行,所以Matlab一刀砍——不能对函数求导!!
13
Mar
单摆运动级数解:初试同伦分析
By 苏剑林 | 2013-03-13 | 18308位读者 | 引用开始之初,我偶然在图书馆看到了一本名为《超越摄动:同伦分析方法导论》,里边介绍了一种求微分方程近似解的新方法,关键是里边的内容看起来并不是十分难懂,因此我饶有兴致地借来研究了。果然,这是一种非常有趣的方法,在某种意义上来说,还是非常简洁的方法。这解决了我一直以来想要研究的问题:用傅里叶级数来近似描述单摆运动的近似解。当然,它带给我的冲击不仅仅是这些。为了得出周期解,我又同时研究了各种摄动方法的技巧,如消除长期项的PL(Poincaré–Lindstedt)方法。这同时增加了我对各种近似解析方法的了解。从开学到现在快三周的时间,我一直都在研究这些问题。
7
Mar
轻微的扰动——摄动法简介(3)
By 苏剑林 | 2013-03-07 | 32914位读者 | 引用微分方程领域大放光彩
虽然微分方程在各个计算领域都能一展才华,不过它最辉煌的光芒无疑绽放于微分方程领域,包括常微分方程和偏微分方程。海王星——“笔尖上发现的行星”——就是摄动法的著名成果,类似的还有冥王星的发现。天体力学家用一颗假设的行星的引力摄动来解释已知行星的异常运动,并由此反推未知行星的轨道。我们已不止一次提到过,一般的三体问题是混沌的,没有精确的解析解。这就要求我们考虑一些近似的方法,这样的方法发展起来就成为了摄动理论。
跟解代数方程一样,摄动法解带有小参数或者大参数的微分方程的基本思想,就是将微分方程的解表达为小参数或大参数的幂级数。当然,这是最直接的,也相当好理解,不过所求得的级数解有可能存在一些性态不好的情况,比如有时原解应该是一个周期运动,但是级数解却出现了诸如$t \sin t$的“长期项”,这是相当不利的,因此也发展出各种技巧来消除这些项。可见,摄动理论是一门应用广泛、集众家所大成的实用理论。下面我们将通过一些实际的例子来阐述这个技巧。

最近评论